







Proximal Algorithms:近端算法,近似算法
proximal operator:近端操作,近似操作
1 简介
1.1定义
a proper convex function:
在数值分析和优化中,一个proper convex function 函数是这样的一个凸函数,其在扩展实轴上的取值满足:
至少存在一个 x ,使得f(x)<+∞
并且对于所有的 x ,f(x)>−−∞
一个凸函数是适当的,也就是说,其在有效定义域内为非空的,并且不能取得 −∞ .
a closed convex funciton:
一个函数 f:Rn→R ,如果对于每一个 α∈R ,其水平子集 {x∈domf|f(x)≤α} 是一个闭集,那么我们称函数 f 是闭凸函数。
令
是一个非空闭凸集。函数 f 的有效域:
也就是说,函数 f 在该点集合上为有限值。
函数
其中 ||⋅||2 是欧式范数。公式右手边( minx 内)函数是强凸函数,并且不是处处无限,因此 for ∀ v∈Rn (甚至当 domf⊂Rn ),该函数有唯一的最小值。
我们经常会碰到scaled function λf 的 近端操作(其中 λ>0 ),其可以表示为,
这也可以称作带有参数 λ 的函数 f 的近端操作。(为了符号的简洁,我们写成
1.2 解释
图1.1描述了近端操作。细黑线是凸函数
f
的等值线。粗黑线表示其定义域的边界。在蓝色的点处计算
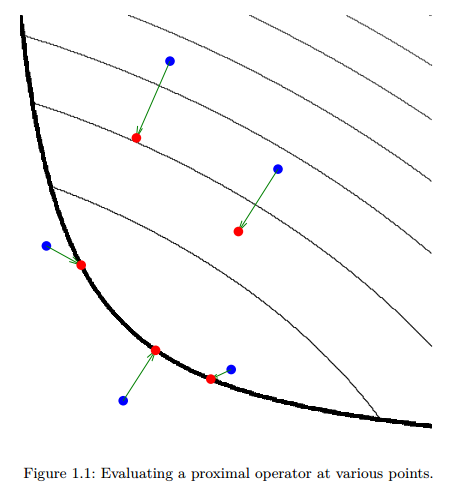
近端操作的定义表明,
proxf(v)
的点是最小化函数
f
和临近
有时称为
v
关于
当
f
是个示性函数(indicator function):
其中 C 是闭的非空凸集,函数
因此,近端操作可以看作是广义投影。
函数 f 的近端操作也可以解释为函数
这表明,近端操作和梯度方法之间存在着紧密的联系,同时暗示着近端操作在优化中很有用,也同样表明, λ 扮演的角色类似于梯度方法中的步长。
最终,函数 f 的近端操作的固定点(fixed points)恰好是函数
1.3 近端算法
近端算法就是指,在求解凸优化问题中,使用了目标项(object terms)的近端操作的算法。
近端算法的优点:
1、其可以应用于一般情况下,包括函数为非平滑的情况。
2、计算快。因为可以存在函数的简单的近端操作。
3、可以用于分布式优化,因此其可以用于解决大规模问题。
4、概念和数学上简单,对于一个特定的问题,易于理解,推导和实现。
实际上,许多近端算法可以解释为其他众所周知并且广泛使用的算法的推广,像投影梯度法。
2 近端操作的性质。
2.1 Separable sum(可分的和)
如何函数
f
可以分解为两个变量的表示形式,即
这样,计算一个可分离的函数的近端操作降为计算每一个可分离部分的近端操作,这两个操作可以独立的实现。
如果 f 完全可分离,意思就是
换句话说,在这种情况下,矢量函数上的近端操作降为在计算标量函数的近端操作,我们将在第5章看到,近端操作的 可分的和属性是推导近端算法并行的关键。
2.2 基本操作
这一部分当需要时,可做参考。
Postcomposition:
如何函数
f(x)=αφ(x)+b,α>0
,那么:
Procomposion:
如何 f(x)=φ(αx+b),α≠0 ,那么:
如何 f(x)=φ(Qx) ,其中 Q 是正交的(
Affine addtition.
如何 f(x)=φ(x)+αTx+b ,那么
Regularization.
如何 f(x)=φ(x)+(ρ/2)||x−α||22 ,那么:
其中 λ~=λ/(1+λρ).
参考文献:
1、 https://web.stanford.edu/~boyd/papers/pdf/prox_algs.pdf
Proximal Algorithms.Neal Parikh,Stephen Boyd.
2、 https://en.wikipedia.org/wiki/Proper_convex_function
3、 https://en.wikipedia.org/wiki/Closed_convex_function















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









