







目录
读日志
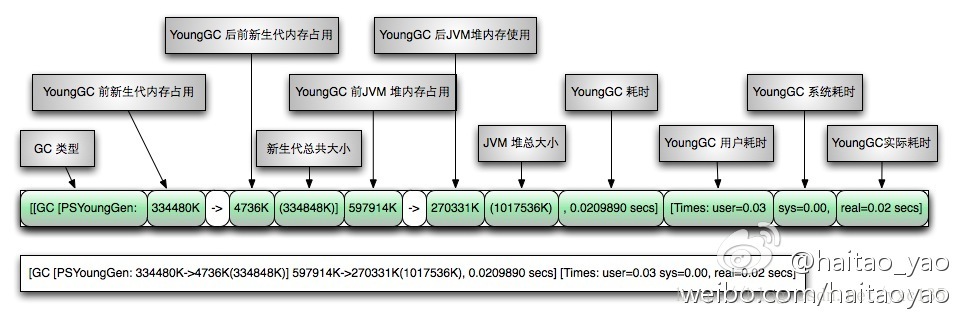
GC (minor )日志
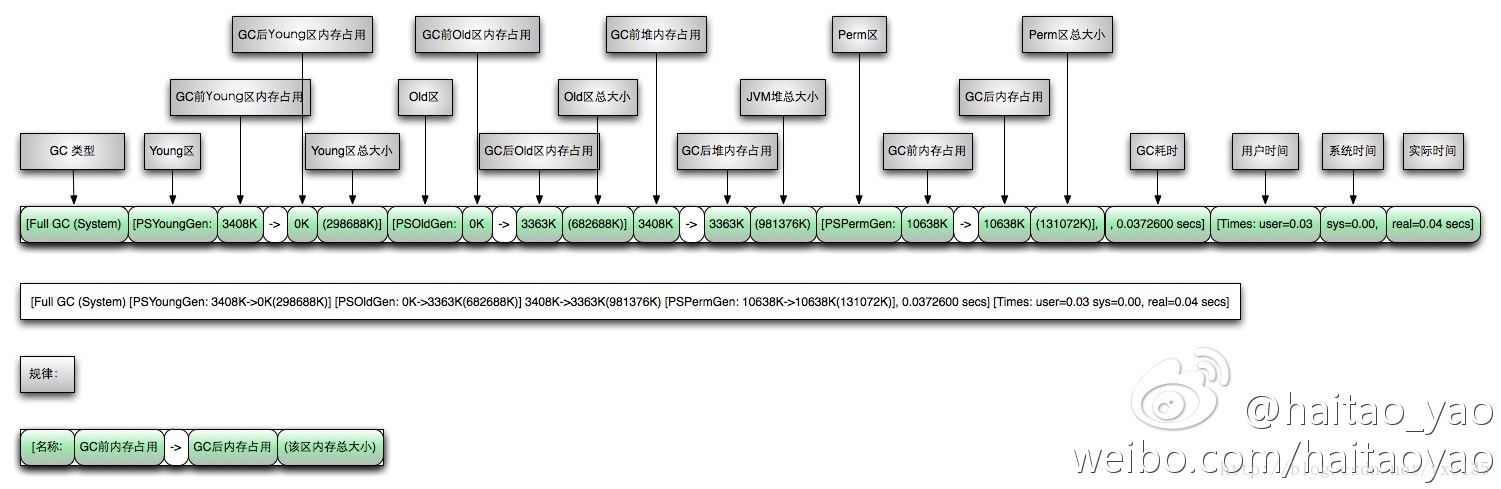
Full GC 日志
concurrent mode failure
concurrent mode failure,主要是由于cms的无法处理浮动垃圾(Floating Garbage)引起的。这个跟cms的机制有关。cms的并发清理阶段,用户线程还在运行,因此不断有新的垃圾产生,而这些垃圾不在这次清理标记的范畴里头,cms无法再本次gc清除掉,这些就是浮动垃圾。由于这种机制,cms年老代回收的阈值不能太高,否则就容易预留的内存空间很可能不够(因为本次gc同时还有浮动垃圾产生),从而导致concurrent mode failure发生。可以通过-XX:CMSInitiatingOccupancyFraction的值来调优。
concurrent mode failure是两个原因:
- 在 CMS 启动过程中,新生代提升速度过快,老年代收集速度赶不上新生代提升速度,在执行CMS GC的过程中同时有对象要放入老年代,而此时老年代空间不足造成的
- 在 CMS 启动过程中,老年代碎片化严重,无法容纳新生代提升上来的大对象
发送这种情况,应用线程将会全部停止(相当于网站这段时间无法响应用户请求),进行压缩式垃圾收集(回退到 Serial Old 算法)
解决办法:
- 新生代提升过快问题:(1)如果频率太快的话,说明空间不足,首先可以尝试调大新生代空间和晋升阈值。(2)如果内存有限,可以设置 CMS 垃圾收集在老年代占比达到多少时启动来减少问题发生频率(越早启动问题发生频率越低,但是会降低吞吐量,具体得多调整几次找到平衡点),参数如下:如果没有第二个参数,会随着 JVM 动态调节 CMS 启动时间
-XX:CMSInitiatingOccupancyFraction=68 (默认是 68)
-XX:+UseCMSInitiatingOccupancyOnly- 老年代碎片严重问题:(1)如果频率太快或者 Full GC 后空间释放不多的话,说明空间不足,首先可以尝试调大老年代空间(2)如果内存不足,可以设置进行 n 次 CMS 后进行一次压缩式 Full GC,参数如下:
-XX:+UseCMSCompactAtFullCollection:允许在 Full GC 时,启用压缩式 GC
-XX:CMSFullGCBeforeCompaction=n 在进行 n 次,CMS 后,进行一次压缩的 Full GC,用以减少 CMS 产生的碎片promotion failure
promotion failure,是在minor gc过程中,survivor的剩余空间不足以容纳eden及当前在用survivor区间存活对象,只能将容纳不下的对象移到年老代(promotion),而此时年老代满了无法容纳更多对象,通常伴随full gc,因而导致的promotion failure。这种情况通常需要增加年轻代大小,尽量让新生对象在年轻代的时候尽量清理掉。
Allocation Failure
表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了
Evacuation Failure
当没有更多的空闲region被提升到老一代或者复制到幸存空间时,并且由于堆已经达到最大值,堆不能扩展,从而发生Evacuation Failure。对于G1 GC,它是非常耗时的。
a.对于成功复制的对象,G1需要更新引用,并且该region被一直引用。
b.对于未成功复制的对象,G1将自动转发它们,并保留这些region。
解决方案:
①.不要过度加一些jvm参数。比如-Xmn,这个参数会限制G1的参数的自动扩展。可以仅使用-Xms,-Xmx和暂停时间目标-XX:MaxGCPauseMillis,删除任何额外的堆大小,例如-Xmn,-XX:NewSize,-XX:MaxNewSize,-XX:SurvivorRatio等。
②.如果问题仍然存在,则增加JVM堆大小(即-Xmx)。
③.如果您无法增加堆大小,并且您注意到marking cycle没有足够早地开始回收老一代,那么请减少-XX:InitiatingHeapOccupancyPercent。默认值是45%。减小该值将提前开始marking cycle 。另一方面,如果marking cycle 提前开始并且未收回,请将-XX:InitiatingHeapOccupancyPercent阈值增加到默认值以上。
④.如果并发marking cycle准时开始,但需要很长时间才能完成,那么使用属性'-XX:ConcGCThreads'增加并发标记线程数的数量。默认是GC Workers: 1 ,单线程执行。
⑤.如果有大量“空间耗尽(to-space exhausted)”或“空间溢出(to-space overflow)”GC事件,则增加-XX:G1ReservePercent。默认值是Java堆的10%。注意:G1 GC将此值限制在50%以内。
Humongous Allocation
它是由'G1 Humongous Allocation'造成的。大型对象(Humongous )是大于G1中region大小50%的对象。频繁大型对象分配会导致性能问题。如果region里面包含大量的大型对象,则该region中最后一个具有巨型对象的区域与区域末端之间的空间将不会使用。如果有多个这样的大型对象,这个未使用的空间可能导致堆碎片化。直到jdk1.8u40之前,这些巨型对象的回收只在full GC期间完成。在较新的JVM中,对这些对象的清理放在了清理阶段。
解决方案:
①.可以加大region的大小,设置-XX:G1HeapRegionSize=n,但是这个参数需要设置为2的幂次方,最小值是1M,做大值是32M。
②.如果可以的话增加JVM堆大小(即-Xmx -Xms)。
gc日志在线分析工具















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









