






基于 java 1.6
HashMap 和其他的 Map 一样,都有由key和它的value构成。但是不同的Map其key的存储方式是大不相同的。 HashMap 较其他Map具有更好的查询效率,这是由于Hash Map 采用了 Hash 算法。 每一个 key 本身都具有一个获取 hashCode 的方法。这些hashCode通过hash算法,被转化为一个个序号,对应“横向”链表上的存储位置。
当序号相同且key的值不同时,在这个位置上就会形成一个“纵向”的链表。在这个链表中先添加的key处于链表的末端,后添加的处于链表的前端。链表的存储单元为 Entry <k,y> , 在这个类中有一个还有一个类型为 Entry<k,y> 的参数,名为 next 。 next 指向的是下一个 Entry<k,y> 的地址 , Hash Map 就是以这样的方式形成了一个“纵向”的链表。

hashMap 还具有自动扩张的功能。每当map中的容量达到 threshold 的时候,hashMap就会通过resize () 方法扩张一倍。 R esize() 的过程是比较消耗性能的,所以如果事先知道存储的大概范围时,也可以预先设置Map的大小,从而降低扩张带来的消耗。thres hold 的算法是size *loadFactor ,load Factor 是一个比例参数,决定了多大比例的长度作为 threshold, 一般而言 loadFactor 的值为 0.75 。如果一个hashMap的长度为 16 , loadFactor 的值为 0.75 ,那么它的临界值为 12 ,当添加的元素达到 12 时,这个map就会扩张一倍达到 32.
hashMap 可以通过构造函数在初始化的时候设置hashMap的各项参数。它提供的构造参数有Hash Map(int size,float threshold) , HashMap(int size),HashMap() 和 HashMap(Map map) 。size是指Map的大小,然而这个值不一定会成为HashMap的最终大小,它会最终转换为最接近 的 2 的N次方值。在Hash Map(int size,float threshold) 的源码里,有这样的代码:
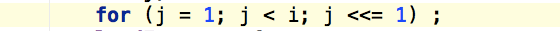
其中 j 为最终的大小,i就是我们传递过来的size,通过位运算,j的最终取值为稍大于size的 2 的N次方值。以下是默认的构造函数 HashMap():

可以看到 loadFactor 的默认值为 0.75 ,默认临界值为 12 (并不是很大),而“横向”的链表其实只是一个数组。如果事先知道HashMap的大小,就应该使用HashMap(int size,float loadFactor)或HashMap(int size)为这个HashMap设置一个合适的大小。即便HashMap有着自动扩张的能力,但是这个功能会消耗不少性能,所以事先设置长度是更好的办法。
hash Map 的大小总是 2 的 n 次方。这是经过计算得出的最佳大小,在这个大小上,hashCode的映射可以达到最小碰撞的效果。
1.将key的hashCode经过HashMap的hash算法后获取的值设为A
2.将HashMap的总长度设为S
那么这个key对应的hashMap中的位置实际应为table[A & (S-1)] 。如果总长度总为16,那么在16-1在二进制对应的值为1111,这个值具有最好的匹配度,因为它每一位都为1。它就像一面光滑的镜子,可以将Hash后的值均匀的映射到table的各个位置上。
参考文档 :
http://alex09.iteye.com/blog/539545
http://www.iteye.com/topic/539465/















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









