






大家好,今天我们分享的内容是基于Helm和Operator的K8S应用管理。
我们知道,Kubernetes基于服务粒度提供了多种资源描述类型。描述一个应用系统尤其是微服务架构系统,需要组合使用大量的Kubernetes资源。针对有状态应用,常常还需要复杂的运维管理操作以及更多的领域知识。
今晚的分享就将介绍如何用Helm这一Kubernetes应用包管理的社区主导方案来简化应用的部署管理,如何制作应用模板以及打造Kubernetes版应用商店,以及如何利用operator自动化应用的运维。
我们知道在K8S社区里面,根据不同的领域,分成了不同的兴趣小组,英文叫SIG。今晚的话题属于APP这个领域。它们是为了解决K8S的应用管理里面的一些问题而生的。
一、Helm
让我们从零开始吧。比如说我们现在已经部署了一个K8S的集群。不管是用GKE或者是EKS,都不是难事,因为现在部署K8S已经不是以前那么麻烦的事情了。然后我们做了应用的容器化。接下来,我们要试着去把我们的应用部署到K8S上面去。
其实在K8S里面,资源对象是很多的:

对于一些微服务架构来说,会有不同的服务在上面运行,你可能要管理诸如deployment、service、有状态的Statefulset、权限的控制等等。你会发现,部署应用后还会有很多其他关联的东西以及你需要考虑的点:比如说你的不同团队,要去管理这样一个应用,从开发到测试再到生产,在不同的环境中,同样一套东西可能都需要不同的配置。例如,你在开发的时候,不需要用到PV,而是用一些暂时的存储就行了;但是在生产环境中,你必须要持久存储;并且你可能会在团队之间做共享,然后去存档。
另外,你不仅仅要部署这个应用资源,你还要去管理其生命周期,包括升级、更新换代、后续的删除等。我们知道,K8S里面的deployment是有版本管理的,但是从整个应用或某个应用模块来考虑的话,除了deployment,可能还会有其他的configmap之类的去跟其关联。这时我们会想,是否有这样一个工具可以在更上层的维度去管理这些应用呢?这个时候我们就有了社区的一个包管理工具:Helm。
我们知道K8S的意思是舵手,即掌控船舵的那个人。而Helm其实就是那个舵。
在Helm里面,它的一个应用包叫Charts,Charts其实是航海图的意思。它是什么东西呢?
它其实就是一个应用的定义描述。里面包括了这个应用的一些元数据,以及该应用的K8S资源定义的模板及其配置。其次,Charts还可以包括一些文档的说明,这些可以存储在chart的仓库里面。
怎么用Helm这个工具呢?Helm其实就是一个二进制工具。你只要把它下载下来,已经配置好了kubeconfig的一些相关配置信息,就可以在K8S中做应用的部署和管理了。
用Helm可以做什么事情呢?其实Helm分为服务端跟客户端两部分,你在helm init之后,它会把一个叫做Tiller的服务端,部署在K8S里面。这个服务端可以帮你管理Helm Chart应用包的一个完整生命周期。
Release == Chart 的安装实例:

接着说说Helm Chart。它本质上是一个应用包,你可以把它理解成dpkg或者像rpm这样的包。只不过,它是基于K8S领域的一个应用包的概念。你可以对同一个chart包进行多次部署,每次安装它都会产生一个Release。这个Release相当于一个chart中的安装实例。
现在我们已经把Tiller部署进去了,那么就可以去做我们应用的管理了:
$ helm install
# (stable/mariadb, ./nginx-1.2.3.tgz, ./nginx, https://example.com/charts/nginx-1.2.3.tgz)
$ helm upgrade <release>
$ helm delete <release>关于一些常用的命令例如安装一个应用包,可以用install,它其实是可以支持不同格式的:比如说本地的一些chart包,或者说你的远程仓库路径。
对于应用的更新,用Helm upgrade。
如果要删除的话,就用Helm Delete。
Helm的一个Release会生成对应的Configmap,由它去存储这个Release的信息,并存在K8S里面。它相当于把应用的一个生命周期的迭代,直接跟K8S去做关联,哪怕Tiller挂了,但只要你的配置信息还在,这个应用的发布和迭代历程不会丢失:例如想回滚到以前的版本,或者是查看它的升级路径等。
接下来我们看一个chart的结构。
$ helm create demoapp

用Helm create的话,它会提供一个大概的框架,你可以去创建自己的一个应用。比如说这个应用就叫做Demoapp,里面会有如下内容:

其中最核心的是templates,即模板化的K8S manifests文件,这里面会包括资源的定义,例如deployment、service等。现在我们create出来的是一个默认的、用一个nginx deployment去部署的应用。
它本质上就是一个Go的template模板。Helm在Go template模板的基础上,还会增加很多东西。如一些自定义的元数据信息、扩展的库以及一些类似于编程形式的工作流,例如条件语句、管道等等。这些东西都会使得我们的模板变得非常丰富。
有了模板,我们怎么把我们的配置融入进去呢?用的就是这个values文件。
这两部分内容其实就是chart的核心功能。


这个deployment,就是一个Go template的模板。里面可以定义一些预设的配置变量。这些变量就是从values文件中读取出来的。这样一来,我们就有了一个应用包的模板,可以用不同的配置将这个应用包部署在不同的环境中去。
除此之外,在Helm install/upgrade时候,可以使用不同的value。
配置选项:


$ helm install --set image.tag=latest ./demoapp
$ helm install -f stagingvalues.yaml ./demoapp比如说你可以set某个单独的变量,你可以用整个File去做一个部署,它会用你现在的配置覆盖掉它的默认配置。因此我们可以在不同的团队之间,直接用不同的配置文件,并用同样的应用包去做应用管理。
Chart.yaml即chart的元数据,描述的就是这个chart包的信息。


另外还有一些文档的说明,例如NOTES.txt,一般放在templates里面,它是在你安装或者说你察看这个部署详情之时(helm status),自动列出来的。通常会放一些部署了的应用和如何访问等一些描述性的信息。

除了模板以外,Helm chart的另一个作用就是管理依赖。

比如说你部署一个Wordpress,它可以依赖一些数据库服务。你可以把数据库服务作为一个chart形式,放在一个依赖的目录下面。这样的话应用之间的依赖管理就可以做的很方便了。
假如现在已经创建了我们自己的应用包,想要有一个仓库去管理这个包,在团队之间共享应该怎么做?
chart的仓库其实就是一个HTTP服务器。只要你把你的chart以及它的索引文件放到上面,在Helm install的时候,就可以通过上面的路径去拿。
Helm工具本身也提供一个简单的指令,叫Helm serve,帮你去做一个开发调试用的仓库。
例如 https://example.com/charts 的仓库目录结构:

关于 Helm,社区版其实已经有了很多的应用包,一般放在K8S下面的一些项目中,比如安装Helm时候,它默认就有一个Stable的项目。里面会有各种各样的应用包。
Stable和incubator chart 仓库:https://github.com/kubernetes/charts
另外,社区版还会提供类似于Rancher Catalog应用商店的这样一个概念的UI,你可以在这上面做管理。它叫Monocular,即单筒望远镜的意思,这些项目的开发都非常的活跃,一直在随着K8S的迭代做着更新。
Monocular: chart的UI管理项目:https://github.com/kubernetes-helm/monocular
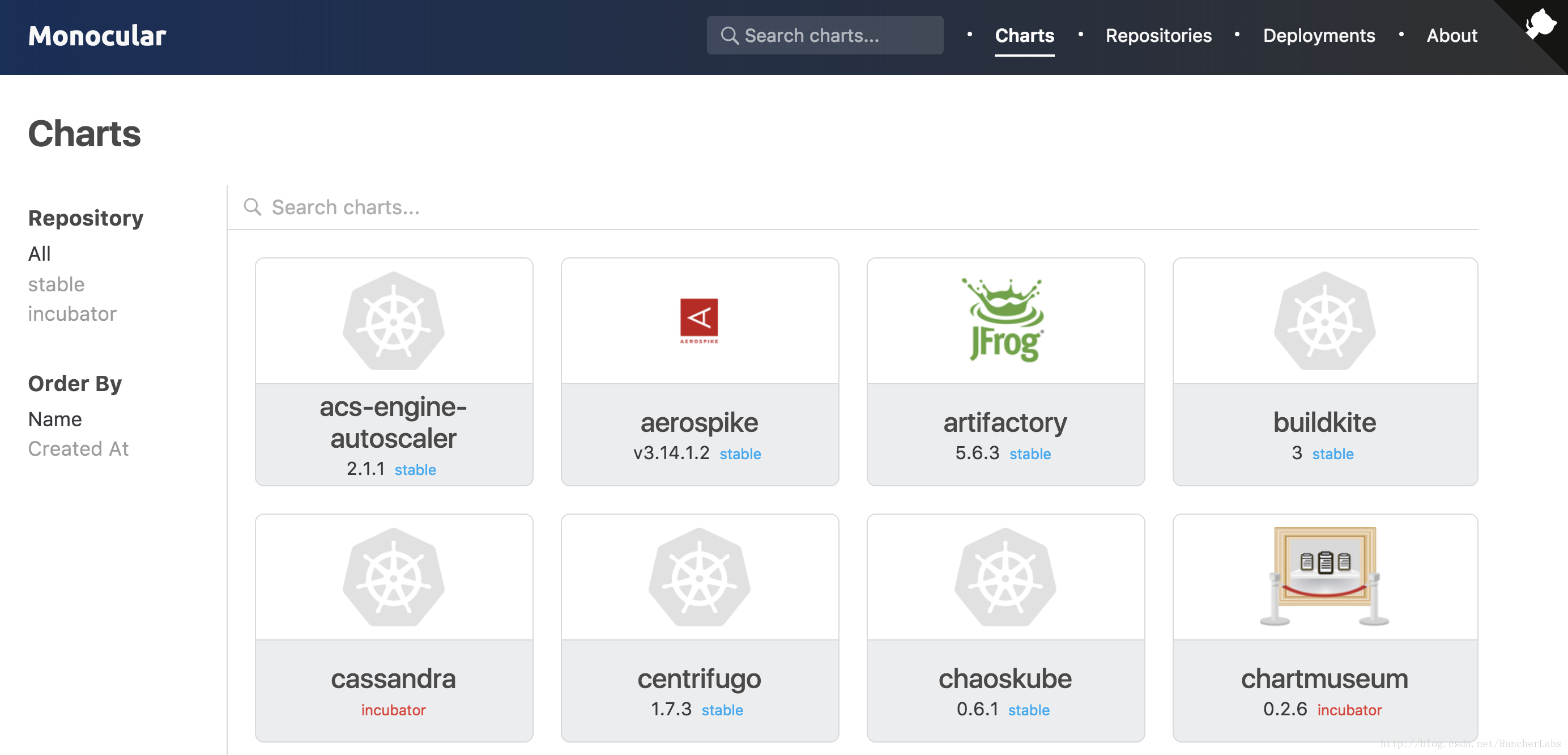
那么怎么去部署K8S版的应用商店呢?其实也非常简单。因为有了Helm之后,你只要使用Helm install这个Monocular,先把它的仓库加进来,再install一下,就可以把这个应用部署到你的K8S集群之中了。它其实也是利用了Helm Tiller去做部署。我们可以在上面去搜索一些chart,管理你的仓库,例如官方的stable,或者是incubator里面的一些项目。

你也可以管理一些已经部署的应用。比如说你要搜索一个应用,点一下部署,就可以把它部署上去了。不过这其中还有很多亟待完善的东西,比如这里的部署不能配置各种不同的参数,它只能输入namespace。其次,里面的一些管理依然存在局限性,比如不能很方便地在UI上做更新。
围绕Helm chart我们也会跟一些公有云厂商有相关的合作。因为Helm chart的好处就是:一个应用包可以在多个地方部署。比如公有云的服务,可以基于它去实现应用的编排和管理,把一个服务便利地提供给不同的用户。Rancher也会在2.0的应用商店中加入对helm chart的支持,希望帮助用户在方便利用已有模板的同时提供良好的体验。
在stable的仓库里面已经有很多chart,其实并不是特别完善,还有很多应用是可以补充和增强的。就我们的实践经验来说,什么都可以chart化,不管是分布式的数据库集群,还是并行计算框架,都可以以这样的形式在K8S上部署和管理起来。
另外一点就是Helm是插件化的,helm的插件有Helm-templates, helm-github,等等。
比如你在Helm install的时候,它可以调用插件去做扩展。它没有官方的仓库,但是已经有一些功能可用。其实是把Restless/release的信息以及你的chart信息以及Tiller的连接信息交给插件去处理。Helm本身不管插件是用什么形式去实现的,只要它是应用包,则对传入的这些参数做它自己的处理就行。
Helm的好处,大概就有这些:
•利用已有的Chart快速部署进行实验
•创建自定义Chart,方便地在团队间共享
•便于管理应用的生命周期
•便于应用的依赖管理和重用
•将K8S集群作为应用发布协作中心
二、Operator
我们接下来说说Operator。为什么讲Operator呢?Operator其实并不是一个工具,而是为了解决一个问题而存在的一个思路。什么问题?就是我们在管理应用时,会遇到无状态和有状态的应用。管理无状态的应用是相对来说比较简单的,但是有状态的应用则比较复杂。在Helm chart的stable仓库里面,很多数据库的chart其实是单节点的,因为分布式的数据库做起来会较为麻烦。
Operator的理念是希望注入领域知识,用软件管理复杂的应用。例如对于有状态应用来说,每一个东西都不一样,都可能需要你有专业的知识去处理。对于不同的数据库服务,扩容缩容以及备份等方式各有区别。能不能利用K8S便捷的特性去把这些复杂的东西简单化呢?这就是Operator想做的事情。
以无状态应用来说,把它做成一个Scale UP的话是比较简单的:扩充一下它的数量就行了。


接着在deployment或者是说ReplicaSet的controller中,会去判断它当前的状态,并向目标状态进行迁移。对有状态的应用来说,我们常常需要考虑很多复杂的事情,包括升级、配置更新、备份、灾难恢复、Scale调整数量等等,有时相当于将整个配置刷一遍,甚至可能要重启一些服务。
比如像Zookeeper315以前不能实时更新集群状态,想要扩容非常麻烦,可能需要把整个节点重启一轮。有些数据库可能方便一点,到master那里注册一下就好。因此每个服务都会有它自己的特点。
拿etcd来说,它是K8S里面主要的存储。
如果对它做一个Scale up的话,需要往集群中添加一些新节点的连接信息,从而获取到集群的不同Member的配置连接。然后用它的集群信息去启动一个新的etcd节点。
如果有了etcd Operator,会怎么样?
Operator其实是CoreOS布道的东西。CoreOS给社区出了几个开源的Operator,包括etcd,那么如何在这种情况下去扩容一个etcd集群?
首先可以以deployment的形式把etcd Operator部署到K8S中。
部署完这个Operator之后,想要部署一个etcd的集群,其实很方便。因为不需要再去管理这个集群的配置信息了,你只要告诉我,你需要多少的节点,你需要什么版本的etcd,然后创建这样一个自定义的资源,Operator会监听你的需求,帮你创建出配置信息来。
$ kubectl create –f etcd-cluster.yaml
要扩容的话也很简单,只要更新数量(比如从3改到5),再apply一下,它同样会监听这个自定义资源的变动,去做对应的更新。
$ kubectl apply -f upgrade-example.yaml
这样就相当于把以前需要运维人员去处理集群的一些工作全部都交付给Operator去完成了。
如何做到的呢?即应用了K8S的一个扩展性的API——CRD(在以前称为第三方资源)。
在部署了一个etcd Operator之后,通过kubernetes API去管理和维护目标的应用状态。本质上走的就是K8S里面的Controller的模式。K8S Controller会对它的resource做这样的一个管理:去监听或者是说检查它预期的状态,然后跟当前的状态作对比。如果其中它会有一些差异的话,它会去做对应的更新。
Kubernetes Controller 模式:

etcd的做法是在拉起一个etcd Operator的时候,创建一个叫etcd cluster的自定义资源,监听应用的变化。比如你的声明你的更新,它都会去产生对应的一个事件,去做对应的更新,将你的etcd集群维护在这样的状态。
除了etcd以外,社区比如还有普罗米修斯Operator都可以以这种方便的形式,去帮你管理一些有状态的应用。
值得一提的是,Rancher2.0广泛采用了Kubernetes-native的Controller模式,去管理应用负载乃至K8S集群,调侃地说,是个Kubernetes operator。
三、Helm和Operator的对比
这两个东西讲完了,我们来对比一下二者吧。
Operator本质上是针对特定的场景去做有状态服务,或者说针对拥有复杂应用的应用场景去简化其运维管理的工具。Helm的话,它其实是一个比较普适的工具,想法也很简单,就是把你的K8S资源模板化,方便共享,然后在不同的配置中重用。
其实Operator做的东西Helm大部分也可以做。用Operator去监控更新etcd的集群状态,也可以用定制的Chart做同样的事情。只不过你可能需要一些更复杂的处理而已,例如在etcd没有建立起来时候,你可能需要一些init Container去做配置的更新,去检查状态,然后把这个节点用对应的信息给拉起来。删除的时候,则加一些PostHook去做一些处理。所以说Helm是一个更加普适的工具。两者甚至可以结合使用,比如stable仓库里就有etcd-operator chart。
就个人理解来说,在K8S这个庞然大物之上,他们两者都诞生于简单但自然的想法,helm是为了配置分离,operator则是针对复杂应用的自动化管理。
我今天分享的内容就到这里,我们可以在QA环节继续交流。
QA环节
Q1:像Rancher有自带的应用商店Catalog,那Helm是相当于K8S的应用商店吗?
A1:是的,Rancher大概是在早期版本、Rancher 1.3开始支持Helm了。用户在Rancher部署K8S的时候,Rancher会把Helm工具都给装好给用户使用。现在的Rancher在K8S里面是没有应用商店的,我们就是考虑到Helm社区很活跃与成熟了,用户可以直接用Helm这个工具,所以K8S里面的应用商店其实是拿掉了的。Rancher 1.x版本,用户使用helm chart并没有cattle catalog那么好,不过2.0里这一点就极大改善了。
Q2:如何将本地的chart包push到远程仓库?
A2:chart repository就是普通的http web 服务器带特定的index文件,把chart包按对应格式传到host的目录就可以了,具体可以参考https://docs.helm.sh/developing_charts/#the-chart-repository-guide
Q3:想添加本地某个目录(包含index.yaml)作为私有仓库该怎么做?
A3:最简单的用helm提供的serve命令。
Q4:helm是一个图形化管理工具吗?
A4:不是图形化管理工具,但是有对应的ui项目。
Q5:helm架构中的tiller是指什么?
A5:tiller就是部署在k8s中的服务端,实际执行部署更新等操作,你用的helm binary是client端会向它发请求
Q6:helm目前国内使用不是很方便,目前所有的charts都是放在google服务器的, 国内用什么好用的repository么?
A6:可以翻墙或者自己搭,我没怎么了解过国内的源(捂脸)
Q7:所以operator是一种管理有状态应用的软件架构模式?
A7:通常用作管理有状态应用,就是利用k8s的crd扩展及声明式定义的方式做应用管理的模式。
Q8:operator业界有通用框架吗?
A8:在k8s的世界就是controller模式那一套,可以参考之前的一篇go-client相关的文章:http://mp.weixin.qq.com/s/MHjuS21iIyV99-o5hESWCw
如若转载,请注明出处谢谢!
微信号:RancherLabs
















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









