






文章目录
1. 数据结构和算法基础 ↑
1.1 索引的本质 ↑
数据库就是用来写入和查询数据的,典型的互联网应用中查询要远大于读取,数据库设计者采用各种各样的算法来优化查询速度。
- 最简单的查询算法是顺序查找,查询复杂度是O(n),在数据量大的时候,查询性能是不可接受的。
- 二分查找(binary search)提供的查询复杂度是O(log2(n)),但是要求数据本身是有序的。
- 二叉树查找(binary tree search)提供了二分查找相同的复杂度,但要求数据本身是二叉树。
每种算法都只适用于特定的数据结构,一份存储不可能满足所有的数据结构,如一个用户表我可能需要按用户ID查找,这个时候我可能需要数据按用户ID顺序组织(以二叉树为例):
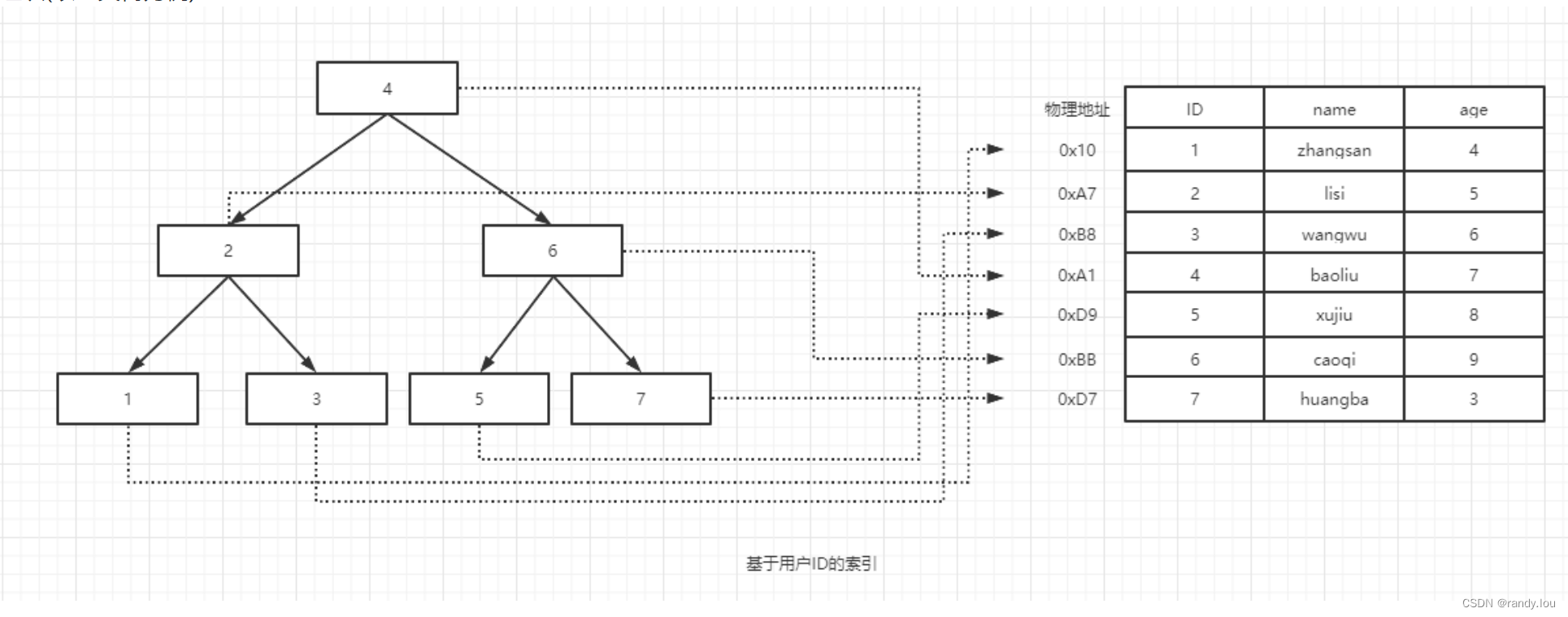
我也可能按用户名查找,这个时候我可能需要数据按用户名顺序组织(以二叉树为例):
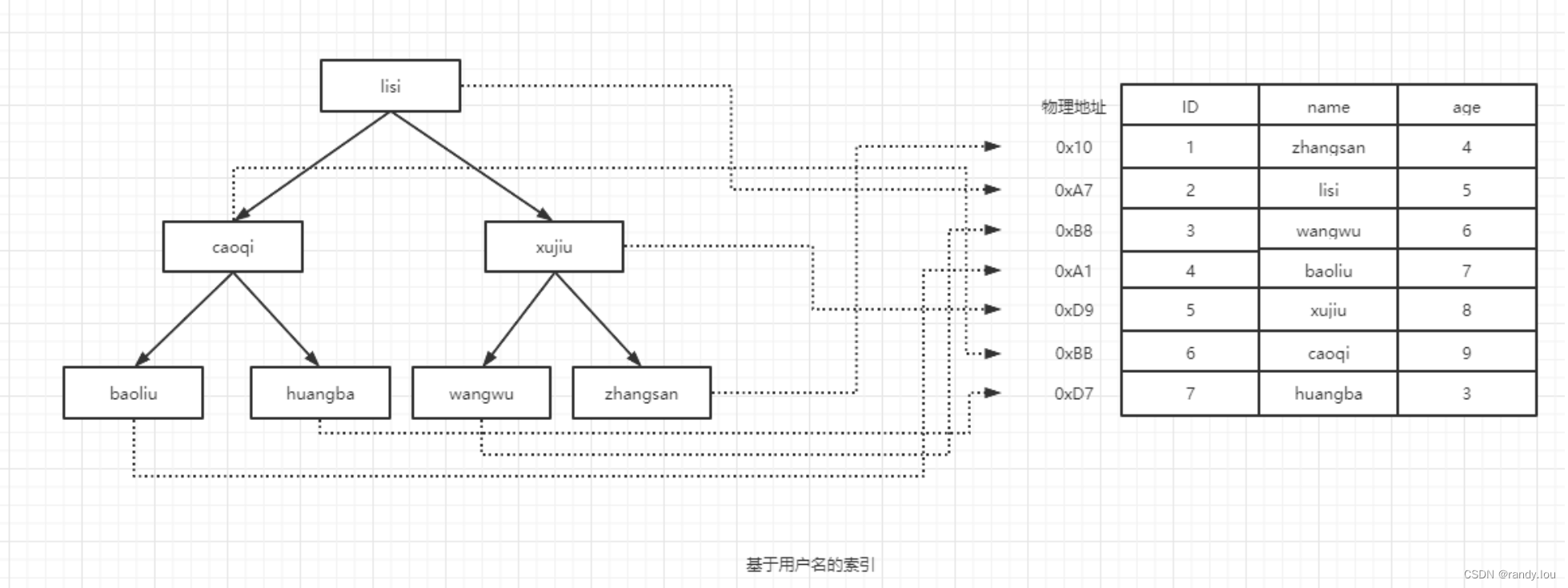
我们无法在同一份数据上同时满足上面两个条件。 在数据之外,额外维护一份数据结构,这些数据结构以某种方式引用(文件位置偏移量)数据,这样我们就能够在这些数据结构上实现高级查找算法。
这种数据结构就称为索引。索引的本质就是,帮助高效查询的数据结构。
1.2 B-Tree和B+Tree ↑
现实世界中基本上没有数据库是使用二叉树(binary search tree)做索引的,数据量足够大的时候,索引也不会太小,所以索引往往并不是常驻内存的。 查询的时候我们需要先定位索引数据结构中相应的Key,找到对应的引用位置。
而二叉树(binary search tree)本身的问题,数据结构的层级相对较深,需要多次磁盘IO,而磁盘IO耗时过高。 B-Tree和B+Tree的主要作用就是优化索引读取的IO次数。
B-Tree中元素角色分为两种: 指针、 Key-Data。 我们通过以下规则来定义B-Tree:
- d为大于1的正整数,称为B-Tree的出度
- h为正整数,称为B-Tree的高度
- 节点由n个指针和n-1个Key-Data组成, 指针和Key-Data相互间隔,node的两端是指针,其中d <= n <= 2d
- 节点内多个key-Data,Key从左到右是非递减队列
- 指针要么null,要么指向一个节点,非叶子节点指针可以是null,叶子结点指针必须为null
- 所有叶子节点具有相同深度,等于B-Tree的高度h
- Key-Data左侧指针指向的子孙node里的Key都小于当前Key;右侧指针执行的子孙node里的key都大于等于当前key
- 指针指向的node里的所有key,都大于等于指针左侧Key-Data,到小于右侧Key-Data
B-Tree的一个样例:

基于B-Tree查询时,只需要从根节点开始二分查找,找到Key-Data则返回,否则通过对应区间的指针递归查找,直到查到对应数据或者指针为null。
对于出度为d的B-Tree,如果有N个索引Key,则树高h的上限是: logdN,可见查询是相当高效的。
同样,插入数据时会导致B-Tree的分裂、合并、转移等操作,对写入性能有一定的损耗。
B+Tree是B-Tree最常见的变种之一,MySQL里就普遍使用B+Tree做索引。 与B-Tree相比,B+Tree主要有两点不同:
- 每个节点的指针上限是2d而不是2d+1
- 非叶子节点只存储Key,不存储data;叶子结点不存储指针
非叶子节点不存储数据,叶子节点不存储指针,提高了节点内存储元素个数的上限。
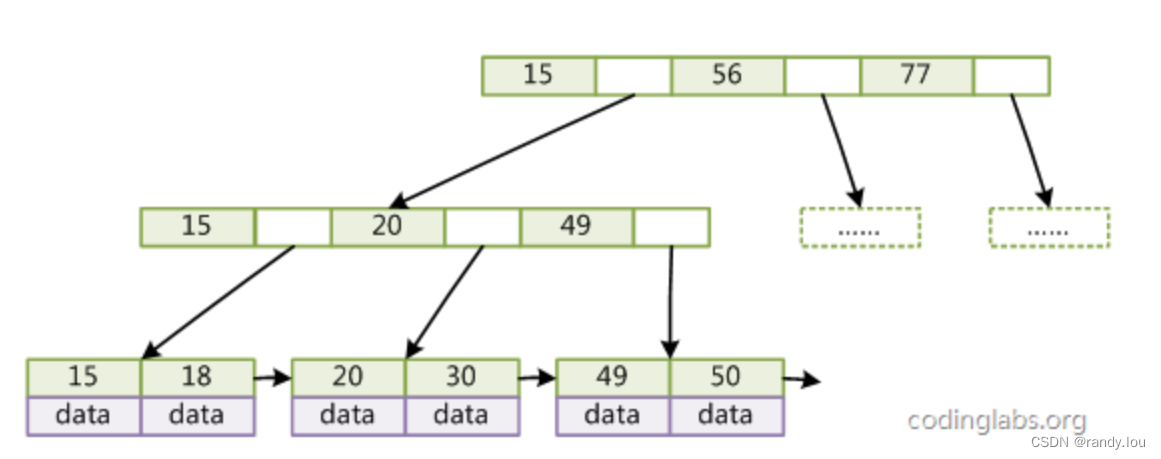
B+Tree的一个样例:

带顺序访问指针的B+Tree
MySQL里对B+Tree做了进一步优化,每个叶子节点增加一个指向相邻节点的指针,当我们使用范围查询的时候,先找到第一个叶子节点,只要沿着指针依次读取即可,不需要再从根节点查找。
1.3 为什么使用B+Tree ↑
前面我们提到,当数据量比较大时对应的索引也不会很小,无法全部存储到内存中。 当索引存储到文件时,文件IO的成本高昂,索引的读取和查找效率就成了索引优劣的关键指标。 这涉及到内存和磁盘的工作方式,我们先简单介绍一些它们的工作原理。
内存存取原理
现代RAM的结构和存取比较复杂,我们抽象一个简单的模型来说明基本工作原理:
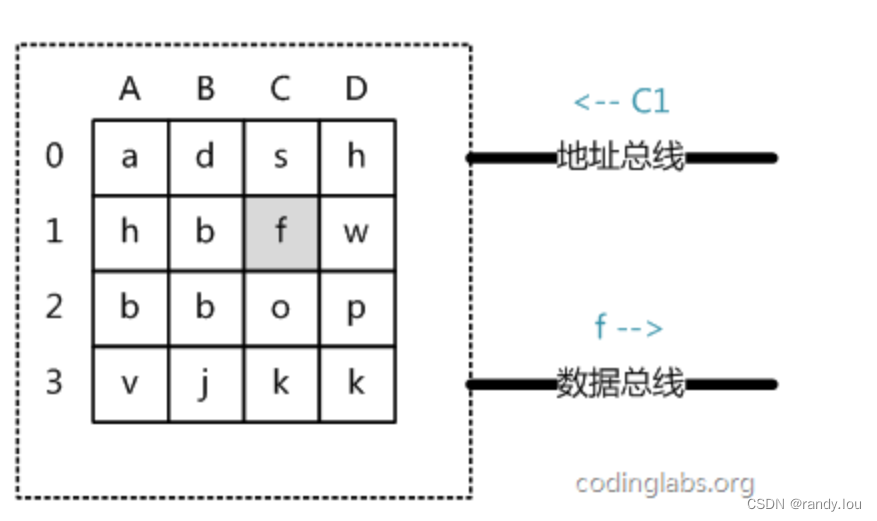
内存由一系列的存储单元组成,每个存储单元有一个唯一的寻址地址,实际的地址编址规则复杂,这里我们将它简化为一个4 x 4的二维表格。
-
读取过程
- 系统将寻址地址信号放入到地址总线
- 内存接收到地址信号后,解析信号,将存储单元的数据放到数据总线
- 系统通过数据总线获取结果
-
写入过程
- 系统将寻址地址写入到地址总线,将数据放入到数据总线
- 主存从两个总线获取数据,写入对应存储单元
对内存而已,顺序读和随机读速度是一样的
磁盘存取原理
一个磁盘有多个盘片组成,盘片一侧有一个磁头支架,每个盘片对应一个磁头。 磁盘被划分为一系列同心圆,每个同心圆的一环叫做一个磁道,所有相同半径的同心圆称为柱面。

磁道被划成相同大小的段,每个段称为一个扇区。 扇区是磁盘的最小存储单元。

当我们需要读取数据的时候,根据读取地址,想将磁头移动到对应的磁道(柱面),这一步称为寻道,所耗费的时间叫做寻道时间,然后磁盘旋转,让磁头对准要读取的第一个扇区,这个时间叫做寻转时间。
- 磁盘的读取事件计算公式
IO Time = Seek Time + 60 sec/Rotational Speed/2 + IO Chunk Size/Transfer Rate
# Seek Time: 寻址时间,磁盘参数里会有标明平均寻址事件,以常见的10000 rpm磁盘为例,多数平均寻址时间为5ms
# Rotational Speed: 磁盘转数, 常见有10000 rpm、 15000 rpm
# IO Chunk Size: 读取数据的大小
# Transfer Rate: 最大传输速度,也是磁盘的关键参数之一
以一个15000转,读取速度上限40MB(只用于举例,实际肯定要大于这个值)的磁盘为例,读取64K数据时间为:
5ms + (60sec/15000RPM/2) + 64K/40MB = 5 + 60 * 1000 / 15000 /2 + 64 / (40 * 1000) * 1000 = 5 + 2 + 1.6 = 8.6ms
# 15000转/秒,所以每转的时间是: 60 * 1000 / 15000 毫秒, 半转时间除以2
# 假设读取速度是40M/s, 所以64K的读取时间是: 64 / (40 * 1000) 秒,乘以1000转换为毫秒
可以看到寻找时间远大于旋转时间、数据读取时间,如果我们顺序读写(这样就不用寻道),这将大大的提高IOPS以及磁盘的读写能力,普通HDD读取速度上限到133M~200M左右, SSD能突破300M
局部性原理
- 定义
当一个数据被使用时,其附近的数据通常也会马上被使用。
磁盘在读取数据的时候,不会严格的按需读取,而是会预加载一些数据,因为磁盘顺序读效率很高。 预读长度通常是页(page)的整数倍。 页是计算机管理存储器的逻辑块,硬件及操作系统通常将内存和磁盘划分给连续的大小相当的块,每个存储块称为一页。
主存和硬盘以页为单位交换数据,当程序要读取的数据不在主存时,系统会向磁盘一次读取多个页进主存,后面几次都从主存直接读取,直到读完主存内的数据,才再次读取硬盘。
1.4 B-Tree性能分析 ↑
根据B-Tree的定义,检索一次最多只需要访问h个节点。 MySQL巧妙的利用了磁盘预读(局部性原理),将一个节点的大小设置为一页,这样保证每个节点只要一次IO就能完全载入。
B-Tree中出度d往往非常大,因此h往往会比较小(通常不超过3),而且根节点常驻内存,所以一般检索索引最多需要2次IO。
我们以一个int类型数据做为Key,同样以int做为索引node做为偏移量,做为例子,假设根节点存有n个key,因此也有n个指针,假设页大小为4K
2 * n * 4 = 4 * 1024
n = (4 * 1024) / 4 / 2
所以根节点我看可以有512个Key和512个指针。
假设h为2,那么第二层都是叶子节点,只保存了数据,在使用聚集索引的情况下,假设存储的行数据为:
| 字段名 | 类型 | 长度 |
|---|---|---|
| id | int | 4 |
| name | varchar(20) | 20 |
| age | short | 2 |
那么第二层节点能够存储的记录数等于:
根节点指针数 * 页大小 / 每条数据占用的字节数 = 512 * 4 * 1024 / (4 + 20 + 2) = 80659
也就是说,如果表格一行只占26字节的情况下,2层B-Tree索引能够支撑80000行数据,3层B-Tree能支撑4000万数据
如果使用非聚集索引,索引里只存储一个8 Byte(Key占4 Byte,记录地址占4 Byte)的key的话,3层B-Tree能过索引1.3亿数据,从一定也说明,索引要尽量的保持精简,更有选择性。
二叉树不适合做索引的原因就是每一层的出度小,导致树的高度大,需要更多次数的IO才能定位到叶子节点。
2. MySQL索引的实现 ↑
MySQL索引是在存储引擎里实现的,不同的存储引擎索引的实现方式不同,这里只介绍MyISAM和InnoDB的B+Tree索引。
2.1 MyISAM的B+Tree索引 ↑
MyISAM的B+Tree叶子结点中处方数据记录的地址(文件偏移量),下图是MyISAM的B+Tree索引原理图:
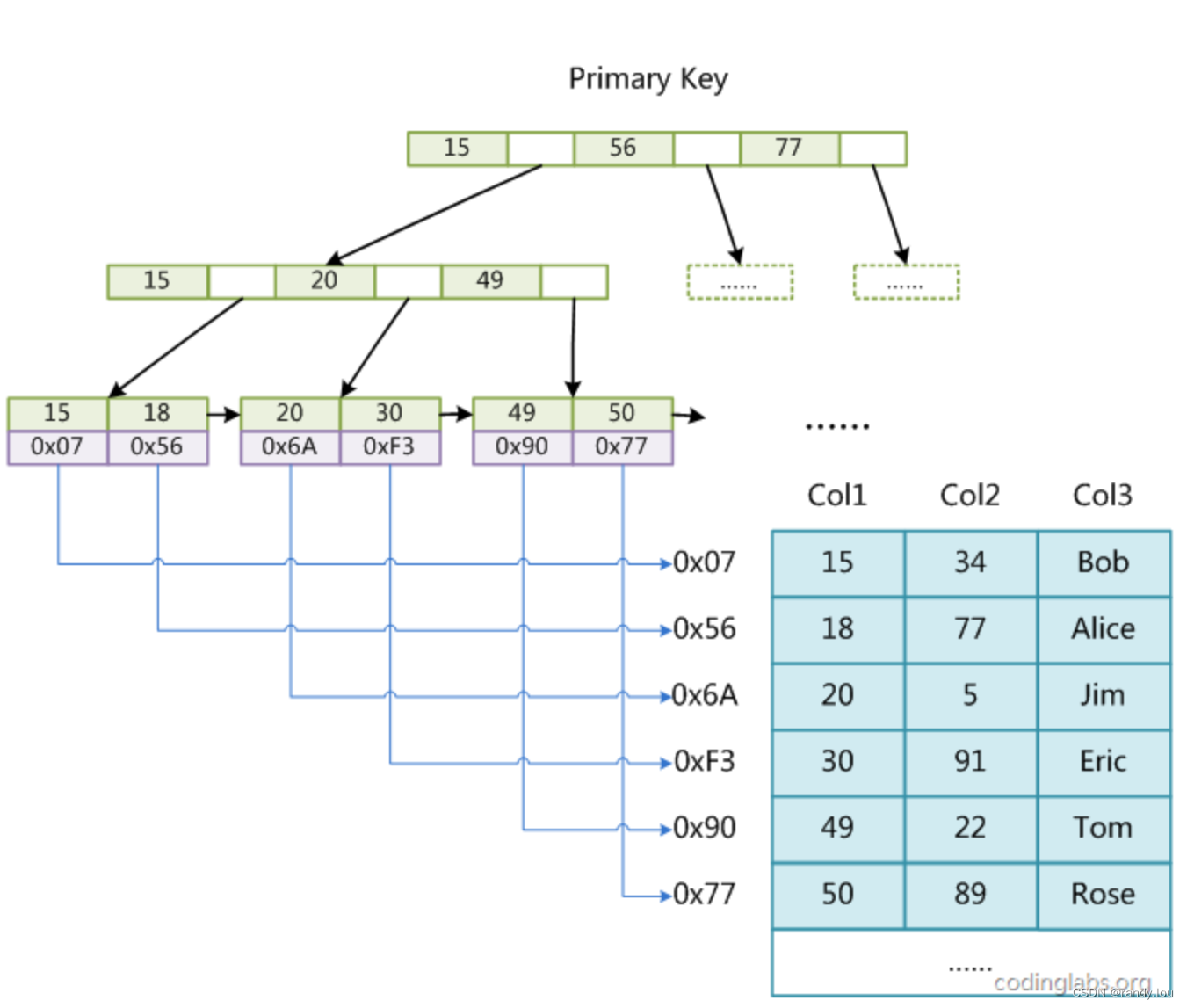
如图假设表有3列, Col1是主键,上面的图就是主键索引的示意图。 可以看出索引只保存记录地址,这保证了索引最小。
按之前学的B+Tree原理,只保存4 Byte的Key和4 Byte的记录地址引用的话,3层B+Tree能索引1.3亿数据。
日常查询不可能都是按主键查询,比如上面的例子,我们可能需要按Col2查询,这时候我们就需要按Col2建一个索引,这个索引也叫做辅助索引。 在MyISAM中,辅助索引和主键索引在数据结构上并没有差别。

辅助索引同样是一颗B+Tree,data域保存着记录地址。 MyISAM检索数据时先从B+Tree定位Key,再根据data指定的位置读出实际的记录。 这种不把完整的数据记录放到索引内的方式,我们称为非聚集索引
2.2 InnoDB索引的实现 ↑
InnoDB的B+Tree索引和MyISAM的截然不同,InnoDB的数据文件本身就是索引文件,在主键索引的叶子节点上会保留完整的数据,索引和之前相同的数据,InnoDB的B+Tree大概是长这样的:
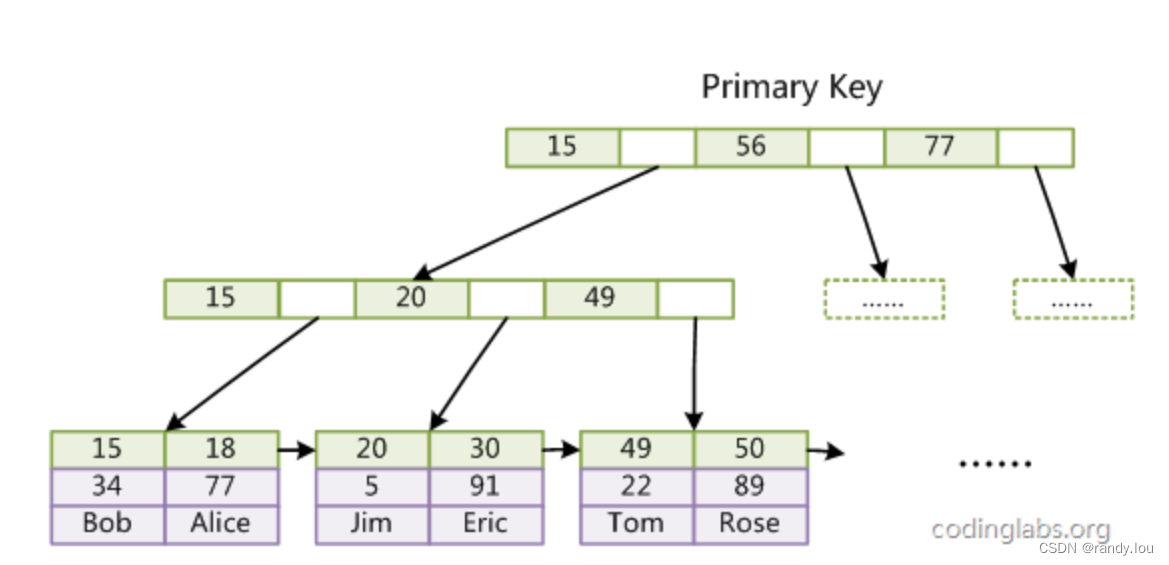
这种索引被称为聚集索引。 因为数据存储是依赖主键索引完成的,索引InnoDB必须要有一个主键,如果没有显示指定,MySQL会自动选择一个可以唯一标识数据的列做为主键,如果没有唯一标识的列,MySQL会自动生成一个6字节的长整型做为ID。
当然每一个索引都是聚集索引会浪费很多的存储空间,InnoDB的辅助索引(非主键索引)和MyISAM有点类似,data域存储的是记录引用,但不是文件的偏移量,而是主键ID。如下图,我们在Col3上建立了一个辅助索引:

聚集索引的查询效率极高,但是会导致node内能储存的记录数急剧变小,导致B+Tree的h变大,尤其是每一行的记录本身很大的时候。 辅助索引可以保证B+Tree有足够的出度,但是检索完辅助索引获取主键以后,还需要用获得的主键在主键索引上检索对应记录。
了解索引的实现有助于我们正确使用和优化索引。 知道了InnoDB的索引实现后,我们就知道要尽量选择多小的列做主键,因为每一个索引都保存在主键做为引用,主键过多容易造成所有索引都变大; 主键应该尽量选择单调递增的列,非单调递增的主键会导致数据库为了维持B+Tree的平衡,频繁的调整、分裂、旋转,增加内耗。
3. 索引的使用和优化 ↑
MySQL的优化分为结构优化(优化存储)和查询优化(优化查询语句)。 这里我们主要讨论结构优化,优化的理论基础就是上面我们刚刚学习完的。
3.1 最左前缀原理 ↑
因为B+Tree是基于顺序的,只有你指定索引键最左侧的字段才能利用索引。
假设我们有employess.titles表,索引如下:
SHOW INDEX FROM employees.titles;
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Null | Index_type |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| titles | 0 | PRIMARY | 1 | emp_no | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 2 | title | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 3 | from_date | A | 443308 | | BTREE |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
- 指定索引的所有列是最高效的
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- 指定索引左侧的列,索引仍然可以被使用
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
- 没有使用左侧的列,导致全表扫描
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- like函数也支持最左前缀
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title LIKE 'Senior%';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- 范围查询的那一列可以使用索引,范围查询列右侧的列不能再使用索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no < '10010' and title='Senior Engineer';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- 查询中使用函数或表达式无法使用索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND left(title, 6)='Senior';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1='10000';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
3.2 索引选择性 ↑
索引的选择性可以通过公式: select count(distinct column) / count(column)计算,数字越接近1说明选择性也高,用这一列做为索引能更快的将数据限定到更小的范围内。
在不影响选择性的前提下,我们可以截断列的一部分前缀做为索引,能过优化查询速度:
ALTER TABLE employees.employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
3.3 尽可能的使用自增主键列 ↑
InnoDB数据被记录到主键索引里,要求同一个节点内数据是按主键顺序存放的。 如果使用非自增主键会导致数据频繁的被插入(从而导致整个B+Tree更多旋转、分裂、合并)
参考文档 ↑
- http://blog.codinglabs.org/articles/theory-of-mysql-index.html















 1884
1884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









