






1. 简介
正则表达式用于描述一组字符的共有特性,以便于我们对字符集做搜索、替换、编辑等操作。 Java的正则表达式实现是通过java.util.regex包实现。 这个文档用于描述java.util.regex支持的正则表达式语法,并提供一些实例。
1.1 java.util.regex包的结构
java.util.regex主要有3个类组成,包括: Pattern、Matcher、PatternSyntaxException
| 类 | 说明 |
|---|---|
| Pattern | Pattern对象用于表示编译后的正则。 通过Pattern.compile静态方法创建Pattern对象,该方法第一个参数接收一个正则表达式字符串。 |
| Matcher | Matcher是执行引擎,用Pattern定义解释并匹配字符串,可以通过Pattern的实例方法matcher创建。 |
| PatternSyntaxException | PatternSyntaxException是一个RuntimeException,表示正则表达式编译时的语法错误。 |
2. 测试工具
这一节我们定义一个测试类RegexTestHarness,接收控制台传入的正则和待匹配字符串,返回匹配结果。
import java.io.Console;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexTestHarness {
public static void main(String[] args){
Console console = System.console();
if (console == null) {
System.err.println("No console.");
System.exit(1);
}
while (true) {
Pattern pattern =
Pattern.compile(console.readLine("%nEnter your regex: "));
Matcher matcher =
pattern.matcher(console.readLine("Enter input string to search: "));
boolean found = false;
while (matcher.find()) {
console.format("I found the text" +
" \"%s\" starting at " +
"index %d and ending at index %d.%n",
matcher.group(),
matcher.start(),
matcher.end());
found = true;
}
if(!found){
console.format("No match found.%n");
}
}
}
}
3. 基本语法
3.1 字面量、组合
| 语法 | 说明 | ||
|---|---|---|---|
| [abc] | 匹配a,b或c中的一个 | ||
| [^abc] | 匹配a,b,c以外的字符 | ||
| [a-zA-Z] | 匹配a-z或A-Z的任意字符,通过unicode编码定义范围 | ||
| [a-d[m-p]] | 匹配a-d或m-p的任意字符,相当于" | "或操作 | |
| [a-z&&[def]] | a-z和[def]取交集,结果是d,e,f中任意一个 | ||
| [a-z&&[^bc]] | 同上,a-z和非bc的字符取交集 |
3.2 预定义字符
| 预定义字符 | 说明 |
|---|---|
| . | 匹配任意字符(可能也匹配换行符,根据flag的设置而不同) |
| \d | 匹配任意数字,等同于[0-9] |
| \D | 匹配任意非数字,等同于[^0-9] |
| \s | 匹配任意空白字符,等同于[ \t\n\x0B\f\r] |
| \S | 匹配任意非空白字符,等同于[^\s] |
| \w | 匹配任意字母、数字或下划线,等同于[a-zA-Z_0-9] |
| \W | 相当于\w取反 |
3.3 量词
| 贪婪 | 懒惰 | 占有 | 说明 |
|---|---|---|---|
| x? | x?? | x?+ | 匹配0或1个x |
| x* | x*? | x*+ | 匹配0或多个x |
| x+ | x+? | x++ | 匹配1或多个x |
| x{n} | x{n}? | x{n}+ | 匹配n个x |
| x{n,} | x{n,}? | x{n,}+ | 匹配n及以上个x |
| x{n,m} | x{n,m}? | x{n,m}+ | 匹配n到m个x |
贪婪表达式匹配尽可能多字符,如果其余部分不匹配,则回退一个字符,重试,直到完全匹配或当前表达式不匹配为止。懒惰和贪婪正好相反,匹配尽可能少的字符,如果其余部分不匹配,则增加一个字符,重试,直到完全匹配或当前表达式不匹配为止。占有表现和贪婪一致,不同的是它不会回退字符。
1. 贪婪型
贪婪型的.*会直接先匹配整个xfooxxxxxxfoo,由于正则后面还有foo,所以导致不匹配,然后回退一个字符xfooxxxxxxfo,依然不匹配,再次回退一个字符xfooxxxxxxf,还是不匹配,再回退一个字符,这个时候是匹配的,.*匹配xfooxxxxxx,后面的foo匹配foo。 所以表现是现在这样的,找到一个匹配:
Enter your regex: .*foo // greedy quantifier
Enter input string to search: xfooxxxxxxfoo
I found the text "xfooxxxxxxfoo" starting at index 0 and ending at index 13.
2. 懒惰型
懒惰型的.*?会先匹配空值,然后因为foo导致不匹配,于是多读入一个字符,x,剩余部分匹配foo,找到一个匹配。 然后再从读入0个字符开始匹配.*,拿剩余部分匹配foo。 结果如下,找到两个匹配:
Enter your regex: .*?foo // reluctant quantifier
Enter input string to search: xfooxxxxxxfoo
I found the text "xfoo" starting at index 0 and ending at index 4.
I found the text "xxxxxxfoo" starting at index 4 and ending at index 13.
3. 占有型
占有型,一次性读入整个字符串匹配.*+,然后不回退,导致没有字符匹配foo,于是提示找不到匹配。
Enter your regex: .*+foo // possessive quantifier
Enter input string to search: xfooxxxxxxfoo
No match found.
3.4 空值匹配(zero-length match)
当我们使用正则a*或a?时,正则本身运行匹配0长度字符串。 在字符串a中用正则a?匹配,会有两个匹配结果,a本身以及一个0长度空白字符串。
如下场景中可能出现空值匹配:
- 待匹配字符串问空
- 待匹配字符串的开头
- 待匹配字符串的结尾
- 待匹配字符串的两个字符间
用正则a?匹配字符串aaaaa,返回的结果是:
Enter your regex: a?
Enter input string to search: aaaaa
I found the text "a" starting at index 0 and ending at index 1.
I found the text "a" starting at index 1 and ending at index 2.
I found the text "a" starting at index 2 and ending at index 3.
I found the text "a" starting at index 3 and ending at index 4.
I found the text "a" starting at index 4 and ending at index 5.
I found the text "" starting at index 5 and ending at index 5.
因为a?是贪婪的总是尽可能的匹配更多。如果匹配ababaaaab就会发现,每一次非a字符的出现都会导致一次控制匹配。
Enter your regex: a?
Enter input string to search: ababaaaab
I found the text "a" starting at index 0 and ending at index 1.
I found the text "" starting at index 1 and ending at index 1.
I found the text "a" starting at index 2 and ending at index 3.
I found the text "" starting at index 3 and ending at index 3.
I found the text "a" starting at index 4 and ending at index 5.
I found the text "a" starting at index 5 and ending at index 6.
I found the text "a" starting at index 6 and ending at index 7.
I found the text "a" starting at index 7 and ending at index 8.
I found the text "" starting at index 8 and ending at index 8.
I found the text "" starting at index 9 and ending at index 9.
3.5 边界匹配符
| 符号 | 说明 |
|---|---|
| ^ | 行头 |
| $ | 行尾 |
| \b | 单词边界 |
| \B | 非单词边界 |
| \A | 输入的开头 |
| \G | 上一次匹配的结尾 |
| \Z | 输入的结尾,但不包含结束符 |
| \z | 输入的结尾 |
4. 捕获分组
4.1 分组编号
分组的按分组括号的出现顺序编号,比如对于正则表达式((A)(B(C))).*编号的话:
| 编号 | 对应内容 | 说明 |
|---|---|---|
| 0 | ((A)(B©)).* | 特殊分组,永远对应着整个正则的匹配 |
| 1 | ((A)(B©)) | 第1个(对应的分组 |
| 2 | (A) | 第2个( |
| 3 | (B©) | 第3个( |
| 4 | © | 第4个( |
通过Matcher.groupCount()能够获取到分组的个数,这个需要特别注意的的groupCount的个数不包括0分组,对应上面的例子的话,groupCount返回的4。
通过Matcher的方法能过拿到特定分组的信息,包括:
| 方法 | 说明 |
|---|---|
| int Matcher.start(i) | 分组i对应的开始索引 |
| int Matcher.end(i) | 分组i对应的结束索引 |
| String Matcher.group(i) | 分组i对应的内容 |
4.2 分组引用
正则使用过程中我们常用的场景时,当一对标签匹配时,才匹配正则,比如以双引号或单引号(“或’)开头,以双引号或单引号(”')结尾时我们识别为字符串内容,前提是开头和结尾的字符必须一样,要么都是单引号,要么都是双引号。 或者匹配HTML时,<[^<>]+>开头,以</[^<>]+>结尾,而且我们希望"<>"的标签名一致。 分组引用就是为了解决这类问题而诞生的。
我们可以在正则表达式内通过\分组编号引用前面的分组。 比如下面这个例子,就要求两位数字重复出现2次才匹配:
Enter your regex: (\d\d)\1
Enter input string to search: 1212
I found the text "1212" starting at index 0 and ending at index 4.
4.3 命名分组
通过语法(?<name>正则信息)可以定义命名分组,这里的分组名称是name
1. 命名分组
(?<分组名>正则)
2. 分组引用
普通的分组可以通过序号引用,\1引用第一个分组。命名分组通过指定分组名引用:
\k<分组明>
4.4 非捕获分组
普通分组会占用一个分组序号,特定场景下,我们需要通过括号来编写分组,但又不希望捕获分组,这就是使用非捕获分组的使用场景。
比如:
(?:[a-c]at)+
4.5 前瞻后顾
特定场景下我们希望指定正则匹配的前提匹配部分前面或后面有特定的内容,比如只有跟在"Tel"后面的11位数字我们才认为它是手机号。
| 语法 | 命名 | 作用 |
|---|---|---|
| (?=正则) | 正前瞻 | 匹配部分跟着符合指定正则的内容 |
| (?!正则) | 反前瞻 | 匹配部分不跟着符合指定正则的内容 |
| (?<=正则) | 正后顾 | 匹配部分前面的内容符合指定正则 |
| (?<!正则) | 反后顾 | 匹配部分前面的内容不符合指定正则 |
5. Pattern
5.1 Pattern.compile
我们通过Pattern.compile(String regex)创建正则表达式对象,除了指定正则,我们还可以通过Pattern.compile(String regex, int flags)配置Pattern对象。
Pattern提供了可以用的flags常量,通过二进制位表示配置信息。 指定一个flag,我们可以这么做:
Pattern pattern = Pattern.compile("[a-z]",Pattern.CASE_INSENSITIVE);
如果要指定多个flag,用按位或连接:
pattern = Pattern.compile("[az]$", Pattern.MULTILINE | Pattern.UNIX_LINES);
此外Java正则还提供了内嵌标记,在正则定义时标记哪些flag生效,比如下面这个例子,表示启用多行模式、使用Unix换行符
pattern = Pattern.compile("(?md)[az]$";
1. 可用的flag配置
| Flag | 内嵌标记 | 说明 |
|---|---|---|
| Pattern.CANON_EQ | None | 规范分解(canonical decompositions)后相等就认为匹配,比如"a\u030A"会被认为匹配"\u00E5",字符串里的"\uxxxx"会替换后在匹配 |
| Pattern.CASE_INSENSITIVE | (?i) | 匹配是忽略大小写,默认只有ascii字符忽略大小写,如果想使用unicode忽略大小写,还需要指定Pattern.UNICODE_CASE |
| Pattern.COMMENTS | (?x) | 允许在正则中忽略空空格和注释,注释以"#"开头。 注释需要在正则表达式中指定(?x)开启,不实用。 |
| Pattern.DOTALL | (?s) | 开启DOTALL模式,".“匹配任意字符,包括换行符。 不指定DOTALL的情况下,不匹配换行。 也可以通过正则中指定”(?s)"启用 |
| Pattern.LITERAL | None | 将整个字符串当字面量,不转义 |
| Pattern.MULTILINE | (?m) | 多行模式,"^$"只匹配行头和行尾(换行符前后)。 默认"^$"是匹配整个字符串的开头和结尾。 |
| Pattern.UNIX_LINES | (?d) | 使用Unix换行符,"\n"做为换行符。 |
5.2 Pattern.matches
Pattern提供了静态方法Pattern.matches(String regex, CharSequence text),是检查text里是否有匹配regex的快捷方式。 返回true的前提是正则能匹配整个text字符串。
Pattern提供了实例方法
System.out.println(Pattern.matches("[a-z]*(\\d+)\\1","abc12341234"));
System.out.println(Pattern.matches("[a-z]*(\\d+)\\1[a-z]+","abc12341234"));
5.3 Pattern.quote
静态方法Pattern.quote(String s)将s转义成字面量,而不当成正则表达式匹配,实际通过添加"\Q"开头和"\E"结尾实现的。 比如:
System.out.println(Pattern.quote("%s\\d"));
输出: \Q%s\d\E
5.4 Pattern.toString
实例方法Pattern.toString()返回Pattern对应的正则表达式。 直接返回Pattern.compile的regex入参,无法体现flag信息。
我们可一个示例:
Pattern p = Pattern.compile("(?m)[a-z]*(\\d+)\\1[a-z]+", Pattern.CANON_EQ | Pattern.DOTALL | Pattern.MULTILINE);
System.out.println(p.toString());
输出:
(?m)[a-z]*(\d+)\1[a-z]+
6. String
6.1 String.matches
实例方法String.matches(String regex)用于校验当前字符串是否匹配给定正则。 str.matches(regex)实际上和Pattern.matches(regex,str)是等价的。
使用示例:
boolean b = "abc123123".matches("[a-z]*(\\d+)\\1");
System.out.println(b)
6.2 String.split
实例方法String.split(String regex, int limit)用于将当前字符串用regex正则切分,最多切分limit个。 str.split(regex,n)实际上和Pattern.compile(regex).split(str,n)是等价的。
实例方法String.split(regex)实际是把String.split(String regex, int limit)的limit默认成为0,切分出来最后的空字符串(长度为0)会被忽略。
1. String.split(regex)实际就是String.split(regex,0)
通过一个例子能说明,下面是示例代码:
String[] arr = "a1b2c345".split("\\d");
System.out.println(Arrays.toString(arr));
arr = "a1b2c345".split("\\d",0);
System.out.println(Arrays.toString(arr));
输出:
[a, b, c]
[a, b, c]
2. 返回结尾的空字符串
String.split(regex)默认会忽略结尾的空字符,如果你希望这些字符也被返回的话,你需要指定limit=-1,如:
String[] arr = "a1b2c345".split("\\d",-1);
System.out.println(Arrays.toString(arr));
输出:
[a, b, c, , , ]
3. 指定最大切分次数
通过指定limit可以限定切分次数。以一个例子来看:
arr = "a1b2c345".split("\\d",2);
System.out.println(Arrays.toString(arr));
输出:
[a, b2c345]
7. CharSequence
CharSequence提供了3个基于正则替换的方法,分别是replace、replaceAll、replaceFirst。
7.1 CharSequence.replace
CharSequence.replace(CharSequence target, CharSequence replacement)是通过Pattern和Matcher实现,正则采用的Pattern.LITERAL模式,replacement执行了Matcher.quoteReplacement(replacement)。 以下是CharSequence.replace()实现:
public String replace(CharSequence target, CharSequence replacement) {
return Pattern.compile(target.toString(), Pattern.LITERAL).matcher(this).replaceAll(Matcher.quoteReplacement(replacement.toString()));
}
我们来看一个使用示例:
System.out.println("abc123123".replace("[a-z]*(\\d+)\\1", "$1"));
System.out.println("abc[a-z]*(\\d+)\\1".replace("[a-z]*(\\d+)\\1", "$1"));
输出是:
abc123123
abc$1
replace只会把target和replacement都当成字面量处理,而不会当成正则,不会动态匹配。
7.2 CharSequence.replaceAll
String还提供了一个String.replaceAll(String regex, String replacement),会正常的处理正则,它的实现是:
public String replaceAll(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}
我们看一个例子:
System.out.println("abc123123".replaceAll("[a-z]*(\\d+)\\1", "1-\\1-\\$-$1"));
输出:
1-1-$-123
regex是正则,replacement中可以通过$分组编号(如$1)引用分组,通过\\转义特殊字符。
7.3 CharSequence.replaceFirst
String.replaceFirst和String.replaceAll实现基本一致,只不过它只会替换第一次出现。
8. Matcher
8.1 索引位置
| 方法签名 | 说明 |
|---|---|
| int start() | 当前匹配的开始位置 |
| int start(int group) | 当前匹配指定分组的开始位置 |
| int end() | 当前匹配的结束位置 |
| int end(int group) | 当前匹配指定分组的结束位置 |
8.2 判断方法
校验输入字符,判断是否能找到匹配正则的内容。
| 方法签名 | 说明 |
|---|---|
| boolean lookingAt() | 从输入字符的开头开始匹配,是否能找到匹配的部分。 |
| boolean find() | 从输入字符串任意位置找匹配正则的内容,找到既返回true |
| boolean find(int start) | 类似find,不过find是从记录的上一次找到的匹配位置之后开始找,这个是从指定位置开始找 |
| boolean matches() | 只有输入字符串整个匹配正则才返回true |
1. lookingAt
输入字符串的开头部分必须匹配正则,字符串后面还可以跟上一些其他字符。 我们看几个例子。
-
正则和输入字符串完全匹配,返回true
Pattern p = Pattern.compile(“\d+”);
Matcher mat = p.matcher(“1234”);
System.out.println(mat.lookingAt()); -
正则匹配输入字符串前面部分,带了一些其他字符,返回true
mat = p.matcher(“1234a”);
System.out.println(mat.lookingAt()); -
开头不匹配,返回false
mat = p.matcher(“b1234a”);
System.out.println(mat.lookingAt());
2. find
同样上面的例子,如果换成使用find方法,全部返回为true,因为find只要找到任意部分匹配就返回为true。
Pattern p = Pattern.compile("\\d+");
Matcher mat = p.matcher("1234");
System.out.println(mat.find());
mat = p.matcher("1234a");
System.out.println(mat.find());
mat = p.matcher("b1234a");
System.out.println(mat.find());
通过指定find(int start)开始查找的位置(包含指定位置的那个字符),我们指到最后一个数字之后,这些方法全部返回false。
Pattern p = Pattern.compile("\\d+");
Matcher mat = p.matcher("1234");
System.out.println(mat.find(4));
mat = p.matcher("1234a");
System.out.println(mat.find(4));
mat = p.matcher("b1234a");
System.out.println(mat.find(5));
3. matches
matches要求整个输入字符串完整的匹配正则,还是从之前的例子看,只有输入字符串是1234才返回true。
Pattern p = Pattern.compile("\\d+");
Matcher mat = p.matcher("1234");
System.out.println(mat.matches());
mat = p.matcher("1234a");
System.out.println(mat.matches());
mat = p.matcher("b1234a");
System.out.println(mat.matches());
8.3 替换方法
用户将字符串中匹配正则的部分替换为其他字符,Java 8为止,函数式编程还没有大量使用,基于匹配的内容动态生成替换字符还略显麻烦,要通过appendReplacement和appendTail来实现。
| 方法签名 | 说明 |
|---|---|
| Matcher appendReplacement(StringBuffer sb, String replacement) | 查找正则的下一次匹配,将上一次匹配(如果没有就从输入字符串开头开始)到这一次匹配之间的内容添加到sb中,并将替换的replacement内容放到sb中。 |
| StringBuffer appendTail(String sb) | 将未匹配的剩余部分写入到sb中并返回 |
| String replaceAll(String replacement) | 将输入字符中所有匹配正则的内容用replacement替换 |
| String replaceFirst(String replacement) | 将输入字符中第一个匹配的内容用replacement替换 |
| String quoteReplacement(String s) | 转义s中的特殊字符,'‘和’$'不再有特殊含义,当字面量处理。 |
1. appendReplacement和appendTail
你可以通过find()调用后,获取匹配内容,根据匹配内容计算要添加的内容,然后动态生成replacement
boolean result = find();
if (result) {
StringBuffer sb = new StringBuffer();
do {
appendReplacement(sb, replacement); // 基于动态算replacement,你可以做到基于匹配生成replacement,动态替换
result = find();
} while (result);
appendTail(sb);
return sb.toString();
}
return text.toString();
比如我们可以基于appendReplacement和appendTail实现一个类似模板的功能。 它的代码差不多是这样的:
Map<String, Object> context = new HashMap<>();
context.put("age", 1);
context.put("name", "zhangsan");
Pattern p = Pattern.compile("\\$\\{([a-zA-Z][a-zA-Z0-9]*)\\}");
Matcher m = p.matcher("Hello ${name} , you are ${age} years old.");
boolean found = m.find();
if (found) {
StringBuffer sb = new StringBuffer();
do {
String key = m.group(1);
m.appendReplacement(sb, context.get(key).toString());
found = m.find();
} while (found);
m.appendTail(sb);
System.out.println(sb.toString());
}
2. replaceAll
replaceAll是将匹配内容全部替换为指定内容的简便方法。 如果上面的例子我们只希望把变量替换为特定内容的话,他就可以简化为:
Pattern p = Pattern.compile("\\$\\{([a-zA-Z][a-zA-Z0-9]*)\\}");
Matcher m = p.matcher("Hello ${name} , you are ${age} years old.");
String s = m.replaceAll("变量替换");
System.out.println(s);
3. replaceFirst
replaceFirst和replaceAll基本类似,但是之后替换第一个出现。
Pattern p = Pattern.compile("\\$\\{([a-zA-Z][a-zA-Z0-9]*)\\}");
Matcher m = p.matcher("Hello ${name} , you are ${age} years old.");
String s = m.replaceFirst("变量替换");
System.out.println(s);
4. quoteReplacement
替换的目标内容允许放入特定元字符,比如’$‘引用特定分组,’\'转义特殊字符。 quoteReplacement的作用是将元字符转为转义字符。
System.out.println(Matcher.quoteReplacement("\\1$1"));
9. PatternSyntaxException
PatternSyntaxException是对正则编译的错误信息封装。
| 方法签名 | 说明 | 样例 |
|---|---|---|
| String getDescription() | 返回错误描述信息 | Unclosed group |
| int getIndex() | 正则表达式错误位置索引 | 22 |
| String getPattern() | 编译的正则表达式本身 | $([a-zA-Z][a-zA-Z0-9]* |
| String getMessage() | 详细的错误信息,上面的几个字段合并在一起 | Unclosed group near index 22 $([a-zA-Z][a-zA-Z0-9]* |
我们看一个错误示例:
try {
Pattern p = Pattern.compile("$([a-zA-Z][a-zA-Z0-9]*");
} catch (PatternSyntaxException e) {
System.out.println(e.getDescription());
System.out.println(e.getIndex());
System.out.println(e.getPattern());
System.out.println(e.getMessage());
}
输出的错误信息包括:
Unclosed group
22
$([a-zA-Z][a-zA-Z0-9]*
Unclosed group near index 22
$([a-zA-Z][a-zA-Z0-9]*
^
10. Unicode支持
从Java 7开始,Java正则开始支持Unicode,主要支持有两种,1. 允许指定codePoint范围匹配; 2. 允许通过Unicode类型匹配
10.1 CodePoint匹配
正则里允许使用"\uXXXX"直接引用代码点,甚至支持代码点范围。不过需要特别注意的是,这里的代码点必须是4为16进制表示,即使不足4位前面也要用0补足。
我们来可一个例子:
int aCodePoint = "a".codePointAt(0);
int zCodePoint = "z".codePointAt(0);
String regex = String.format("[%s-%s]+", "\\u00" + Integer.toHexString(aCodePoint), "\\u00" + Integer.toHexString(zCodePoint));
System.out.println(regex);
System.out.println(Pattern.matches(regex,"abc"));
10.2 使用Unicode类型匹配
Unicode定义了很多属性都是对字符分组的作用,General Category、Unicode Script、Unicode Block只是不同维度的分组而已。
我们通过\p{}指定要匹配的分组,遵循正则上的关联\P{}(P大写)和\p{}是取反的意思。
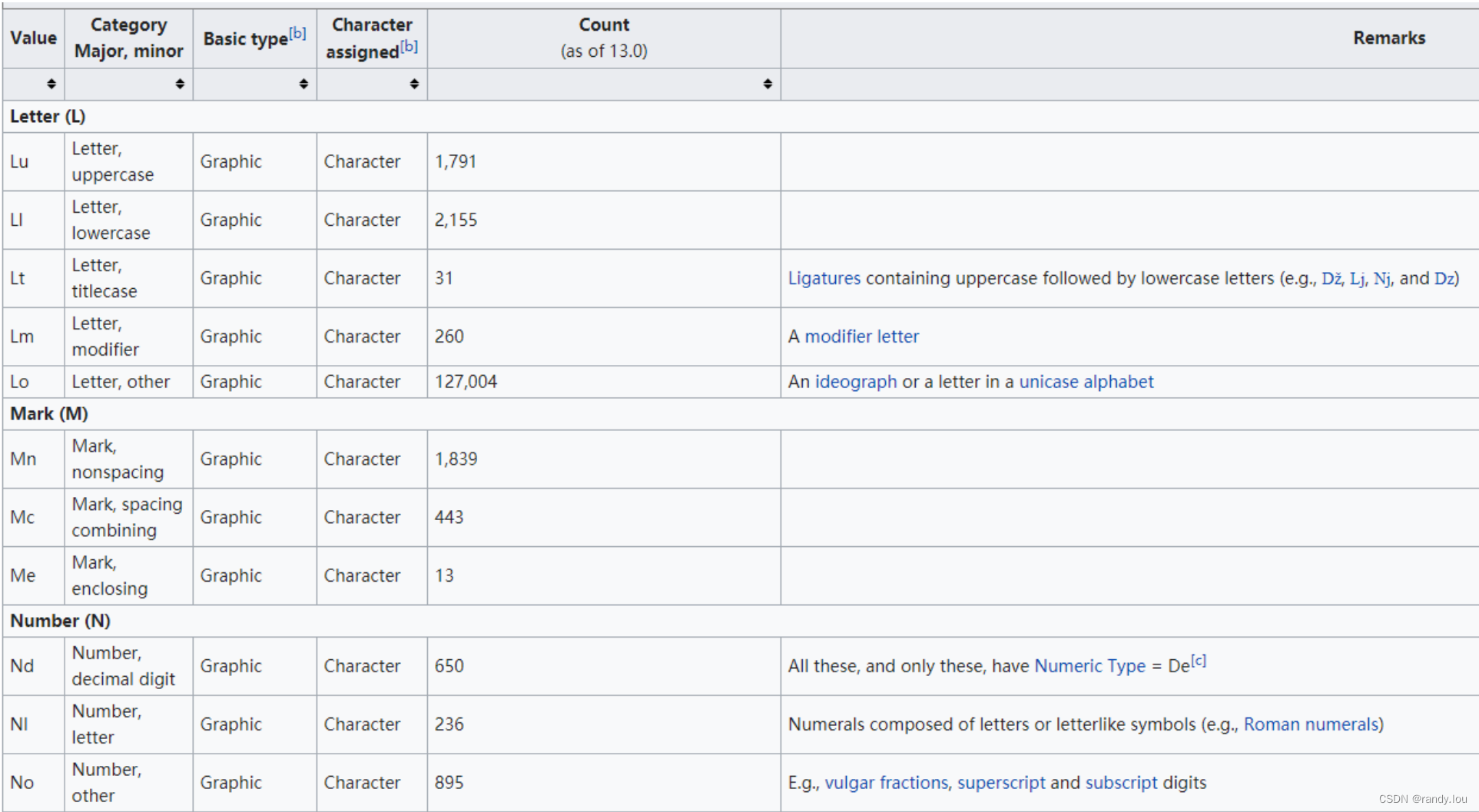
1. General Category
关于General Category的定义见Wikepedia: https://en.wikipedia.org/wiki/Unicode_character_property#General_Category。
我们来看一个例子,通过Lu表示大写字母:
System.out.println(Pattern.matches("\\p{Lu}+","ABC")); // true
System.out.println(Pattern.matches("\\P{Lu}+","abc")); // true
2. Unicode Script
对应Java里是UnicodeScript类,我们可以通过\p{script=名字}使用。可用的名字是UnicodeScript.forName(name)支持的名字。 我们看一个使用示例:
int aCodePoint = "a".codePointAt(0);
Character.UnicodeScript us = Character.UnicodeScript.of(aCodePoint);
System.out.println(us.name());
System.out.println(Pattern.matches("\\p{script=LATIN}+","abc"));
System.out.println(Pattern.matches("\\P{script=LATIN}+","abc"));
3. Unicode Block
对应Java里是UnicodeBlock类,我们可以通过\p{block=名字}指定。
更多关于UnicodeBlock的信息查看Wiki: https://en.wikipedia.org/wiki/Unicode_block
我们看一个例子:
Character.UnicodeBlock blk = Character.UnicodeBlock.of('a');
System.out.println(blk.toString()); // 打印block名称
System.out.println(Pattern.matches("\\p{block=BASIC_LATIN}+","ABC")); // 使用block匹配,返回true
System.out.println(Pattern.matches("\\P{block=BASIC_LATIN}+","abc")); // 返回false
11. 元字符
正则支持的元字符 <([{^-=$!|]})?*+.> ,如果想要把元字符当成普通字符:
- 使用反斜杠转义
- 使用\Q和\E包装
参考资料
- Java正则 https://docs.oracle.com/javase/tutorial/essential/regex/index.html
- Unicode Property说明 https://en.wikipedia.org/wiki/Unicode_character_property
- Unicode Block划分 https://en.wikipedia.org/wiki/Unicode_block















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









