







1. 背景知识
1. 程序如何被执行
程序的执行是通过CPU不断的执行指令来推进的。CPU并不知道线程/进程,它单纯的接收指令,使用寄存器,读写外部设备,操作系统将指令喂给CPU。分时操作系统,用时间片轮转的方式将CPU时间分配给不同的任务,轮转时需要保存/恢复现场(CPU寄存器、栈、PC计数器等),这个过程被称为上下文切换。而进程/线程就是参与切换的这些任务。
我们通过操作系统执行一个可执行程序时,比如Shell下执行echo,Shell会通过系统条用fork()创建一个新的进程,再通过exec()系统调用读取可执行文件ELF,用其中的数据布置现场,将其中的指令初始化栈和PC计数器,分时调度到当前进程的时候,就可以执行当前进程对应的CPU指令集了。这个模型只是为了让我们理解一个可执行程序是如何被引导并开始执行的,实际的过程会多很多细节和差异。
Java程序的执行和上面的基本没有本质的差别,只是执行过程会有Java字节码的解析,生成最终要执行的机器指令。
这是一个CPU多核架构的图,图片来自看懂CPU信息,根据这张图来理解一下上面的运行过程和上下文切换。
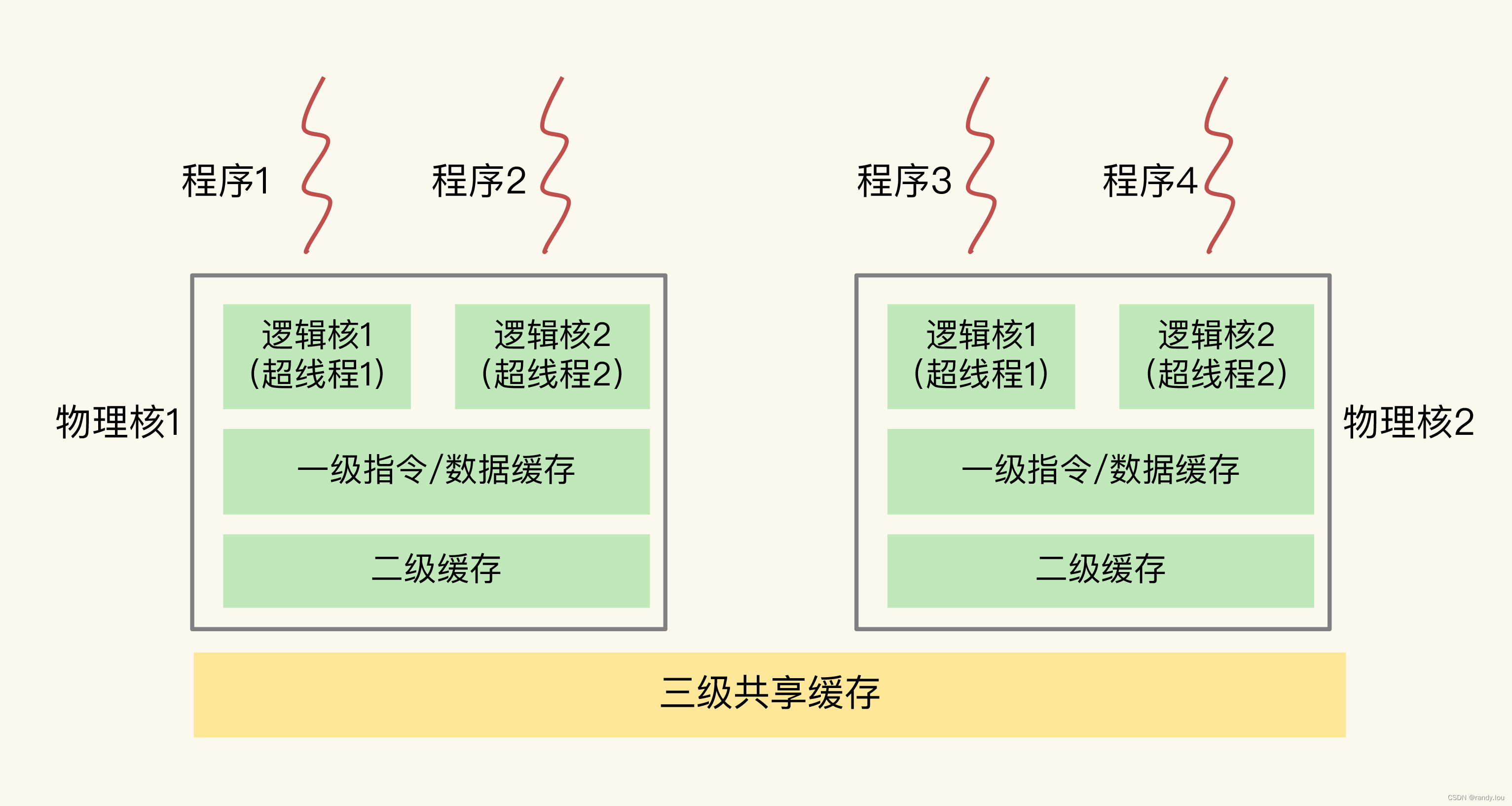
2. 一个线程的开销
Linux下启动线程和启动进程采用了相同的实现,只是线程会共享部分资源(如地址空间),见参考资料[The Linux Thread Implementation]。创建一个线程首先会在用户态分配如下空间
| Java栈 | 记录线程状态,调用栈和栈帧。初始化第1个栈帧Thread.run方法的局部变量、操作数栈、动态链接、返回地址等信息 |
| PC计数器 | 指示当前正在执行的字节码指令的地址 |
| 本地方法栈 | 支持JNI调用 |
| Java堆 | 将线程维护到内部数据结构,以便进行管理和调度,如线程dump、ThreadMXBean |
等这些步骤都完成后,JVM会通过系统调用,请求操作系统创建本机线程,在Java虚线程之前,Java线程是一比一的映射到本机线程的
| 内核线程资源 | 分配内核栈、进程标识符(PID)等 |
| 线程上下文 | 用于在上下文切换时保存寄存器状态、信号掩码、调度优先级等 |
| 调度器 | 将线程添加到父进程,操作系统调度器中,等待调度 |
这些开销里我们核心关注的是Java栈、内核栈,Java栈的默认大小根据不同的JVM实现、版本、CPU架构(32位64位)都可能不同,默认值是1M左右。
要想看当前运行中的进程的Java栈大小可以通过jinfo命令,具体示例如下
randy@namenode:~$ jinfo -flag ThreadStackSize 25166
-XX:ThreadStackSize=1024除此以外,我们可以在启动命令上指定-Xss1M指定Java栈的大小,使用-XX:+PrintFlagsFinal打印最终生效的配置值,示例如下
randy@namenode:~$ java -Xss -XX:+PrintFlagsFinal -Xmx1024M -Xms256M -Xss1M -jar yangsi-0.0.1-SNAPSHOT.jar
...
intx ThreadStackSize = 1024 {pd product} {default}
...内核栈的大小同样依赖操作系统、版本、CPU架构(32位64位)、编译参数等,从资料看大小在4~32K上下,比Java栈大小要小太多,这里我们忽略。
2. Java线程
现在是时候来看看用Java中的线程了,在Java中创建线程还是比较简单的,可选方式有两种,继承Thread覆盖run方法;或者实现Runnable,用Runnable创建Thread。下面我们来看一个极简的示例
public static class HeartBeat implements Runnable {
public void run() {
System.out.println("I'm fine.");
}
}
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(new HeartBeat());
t.start();
t.join();
}我们定义了一个Runnable实现类,然后用Runnable实现类HeartBeat创建Thread对象,调用start方法启动线程,start方法内部会经过系统调用创建本机线程。这里调用t.join()的目的是让main方法所在的线程等待t线程运行结束。
1. 生命周期
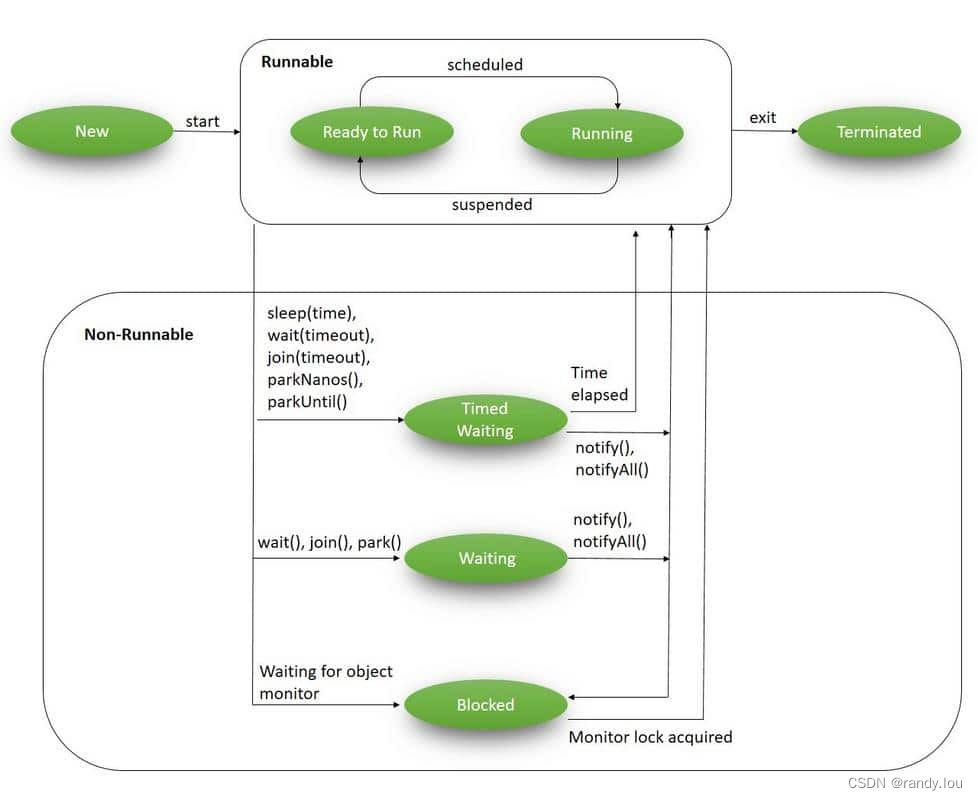
Java定义了一个枚举类Thread.State用来指示线程的状态,任意时刻线程的状态都是其中一个枚举值,下图来自参考资料[Java Thread LifeCycle],结合该图我们来看一下状态怎么转换的:
- New: 创建Thread对象后,调用start之前的状态,这时候线程还没有真正的创建
- Runnable: 新建Thread对象调用start后就进入到Runnable状态,Java里并不区分可执行和正在执行这两个状态
- Waiting: 当线程内调用Object.wait()、Condition.await()、LockSupport.park()、Thread.join()之后,线程进入该状态,直到对于的notify、signal、unpark方法被调用转为Runnable
- Timed-Waiting: 和Waiting一样,不同的是它会设置一个超时时间,条件超时未达成依然会转为Runnable状态
- Blocked: 等待锁或同步块时,线程进入该状态,所成功或者等待锁超时返回Runnable状态
- Terminated: 线程的run方法执行结束后进入该状态
这里要特殊提一下的是,如果线程IO阻塞了,这个时候线程的状态可能还是Runnable,然后实际上不会被执行,而且这个时候线程持有的锁并不会被释放,所有等待这个相同的锁的线程都会进入等待。Thread.sleep()进入休眠的线程,状态会变成Timed Waiting,休眠期间线程持有的锁不会释放。通过条件wait、await的线程则不同,进入Waiting、Timed Waiting状态时,线程会释放持有的锁,再执行时会重新加锁,要重新校验条件。
2. 中断线程
正常的线程只有在run方法执行结束或者run方法内抛出未处理的异常时才会结束,如果我们想要执行过程的线程停止运行要怎么做呢?
1. Thread.stop()
早期的Java使用Thread.stop()来从run方法抛出ThreadDeath异常来终止线程。正常的Java代码是无法做到调用stop方法,让run方法抛出异常的,除非在stop方法内设置标志位,run方法内设置检查点。这种方式在线程重新进入检查点之前无法感知线程状态变化。实测下来,调用stop后,即使阻塞在synchronized的线程也会立即停止,应该是JVM直接在Java栈上写入了athrow指令。
通过Thread.stop()方法来中断线程已经不推荐使用了,我们用一个例子来解释它有什么问题,为什么会被废弃。假设我们有两个账号: accountA、accountB,现在用一个线程从accountA转账到accountB
public static class BrokenTransaction implements Runnable {
private volatile int accountA = 100;
private volatile int accountB = 100;
public void run() {
int cost = 30;
accountA -= cost;
sleep(60_000); // 模拟耗时的操作
accountB += cost;
System.out.println("transaction success, accountA: " + accountA + ", accountB:" + accountB);
}
}然后用一个服务触发,确保accountA转出后、accountB转入前调用stop方法结束线程,stop方法会导致线程立刻抛出已经被结束任务,导致数据不一致。
public static void testBroken() throws InterruptedException {
BrokenTransaction tran = new BrokenTransaction();
Thread t = new Thread(tran);
t.start();
sleep(10_000); // 等待accountA扣款完成
t.stop(); // 停止线程
System.out.println("immediate state: " + t.getState());
System.out.println("before join, accountA: " + tran.accountA + ", accountB: " + tran.accountB + ", state: " + t.getState());
t.join();
System.out.println("after join, accountA: " + tran.accountA + ", accountB: " + tran.accountB + ", state: " + t.getState());
TimeUnit.HOURS.sleep(1L);
}我们来看一下这个程序的输出,可以看到accountA转出执行了,accountB转入却没有
immediate state: TIMED_WAITING
before join, accountA: 70, accountB: 100, state: TERMINATED
after join, accountA: 70, accountB: 100, state: TERMINATED从实现机制上来看,还有一个特别要注意的问题是,如果在sleep方法上处理了Throwable异常(ThreadDeath继承自Error),会导致线程不想要stop请求,我们看一下catch(Throwable)的输出
immediate state: TIMED_WAITING
transaction success, accountA: 70, accountB:130
before join, accountA: 70, accountB: 130, state: RUNNABLE
after join, accountA: 70, accountB: 130, state: TERMINATED2. Thread.interrupt()
Thread#interrupt()的实现逻辑要简单的多,在Thread对象上保存了一个volatile的标志位,在我们的run方法里设置检查点,只有在检查点的时候才响应中断请求。我们来看一下转账的代码,这里的核心点是要做到一次转账过程中是不响应中断的(sleep方法不抛出InterruptedException),如果要响应中断的话,需要业务代码保证数据还是一致的。
public static class InterruptTransaction implements Runnable {
private volatile int accountA = 100;
private volatile int accountB = 100;
public void run() {
while (!Thread.currentThread().isInterrupted() && accountA >= 30) {
int cost = 30;
accountA -= cost;
sleep(60_000); // 模拟耗时的操作,这里不能响应interrupt请求,要处理InterruptedException
accountB += cost;
System.out.println("transaction success, accountA: " + accountA + ", accountB:" + accountB);
}
}
}还有个值得一提的问题是,检查是否中断的方法(Thread.currentThread().isInterrupted()),有的会清除中断标记,有的不会,使用的时候要自己跟踪进JDK源码确认一下。这里的:
- Thread.currentThread().isInterrupted(),不会清除中断标记
- Thread.interrupted(),会清除标记
3. 自建标志位
使用Thread的中断标志位的问题是有的方法会抛出InterruptedException,我们并不希望一个转账中间被中断,而是在检查点的时候在检查是否需要停止。下面是代码示例
public static class StopFlagTransaction implements Runnable {
private volatile boolean stop = false;
private volatile int accountA = 100;
private volatile int accountB = 100;
public void run() {
while (!stop && accountA >= 30) {
int cost = 30;
accountA -= cost;
sleep(60_000); // 模拟耗时的操作,这里不能响应interrupt请求,要处理InterruptedException
accountB += cost;
System.out.println("transaction success, accountA: " + accountA + ", accountB:" + accountB);
}
}
}3. 线程属性
线程常用的属性基本就是线程名称、优先级、是否守护线程,通过下面表格中的方法能进行设置
| 属性 | 代码 | 说明 |
| 守护线程 | Thread#setDaemon(boolean) | 设置为true表示线程是守护线程,当一个进程下只剩下守护线程的时候,进程会退出执行 |
| 线程名 | Thread#setName(String) | 设置线程名称,方便后续识别和处理 |
| 优先级 | Thread#setPriority(int) | 1~10整数,越大优先级越高,Thread.MIN_PRIORITY、NORM_PRIORITY、MAX_PRIORITY |
如果我们想在线程创建之后做通用的初始化流程,可以继承JDK提供ThreadFactory接口,见下面的代码,使用起来十分,这里就跳过讲解了
public interface ThreadFactory {
Thread newThread(Runnable r);
}3. 线程池
在背景知识里我们有讲过,创建一个线程需要初始化Java栈、PC寄存器、本地方法栈、内核栈、上下文等一堆资源,需要做系统调用,是一个成本相当高的操作。频繁的创建和销毁线程是极不明智的,线程池就是用来解决这种场景下所面临的问题的。
1. 工作原理
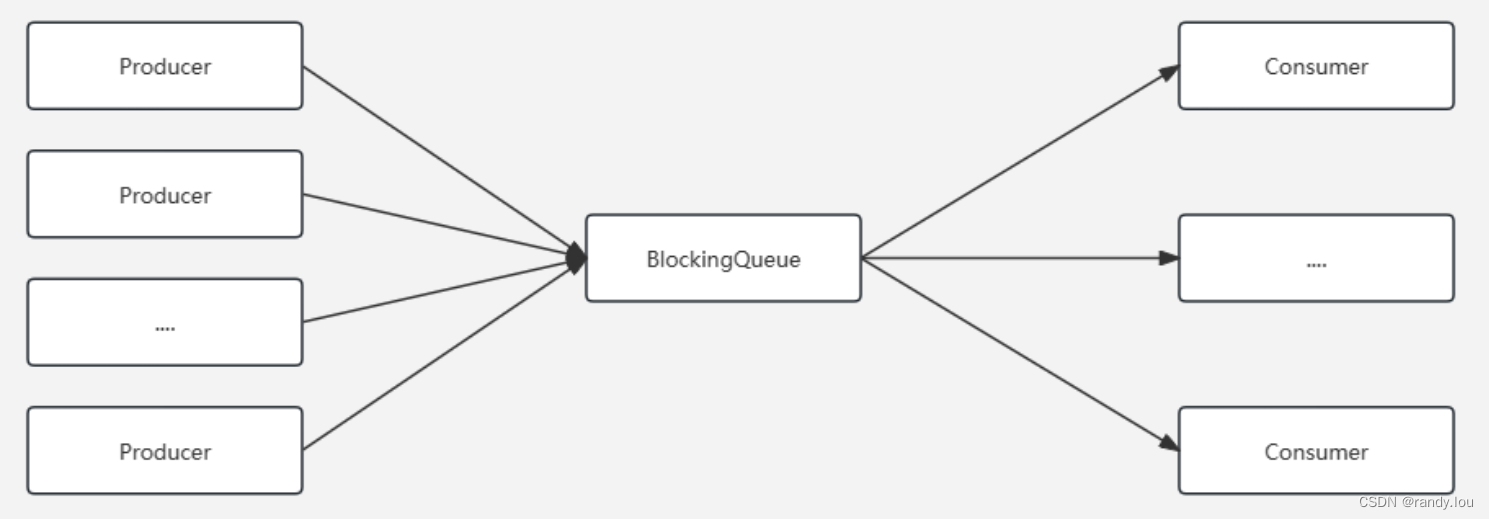
多线程的时候,如果上游生产很多数据,希望下游能自动负载均衡的处理这些任务,我们经常使用生产者消费者模式,它看起来大概是这样的,Consumer最后运行在不同的线程上,如果消费速度不够的话,通过调整Consumer对应的线程数来调节消费速度。
Java内建的ThreadPoolExecutor线程池基本遵循了这个逻辑,不同的是它比上面处理的细节会多很多
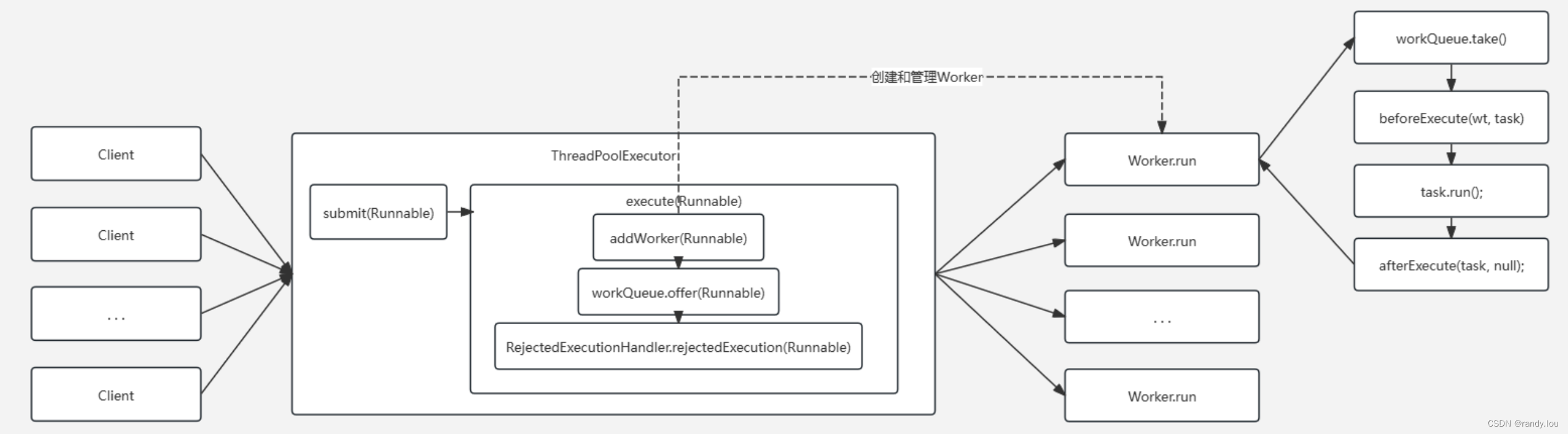
当我们提交任务(Runnable)给ThreadPoolExecutor时,它经过了如下步骤:
- 先检查当前的线程数(Worker的数量),如果线程数少于corePooSize,这时候会通过addWorker新建一个线程
- 否则,尝试将任务保存进workQueue,注意这里调的是Queue.offer,
- 如果加入workQueue失败,直接调用RejectedExecutionHandler处理任务
Worker其实就是线程池里的工作线程,Worker的执行流程如下:
- 创建Worker是会传入一个firstTask,如果firstTask为空(已经执行一轮),从workQueue里拿一个任务(workQueue.take())
- 执行ThreadPoolExecutor的beforeExecute方法
- 执行任务, task.run()
- 执行ThreadPoolExecutor的afterExecute方法
- 回到第一步,重新从workQueue里取一个任务并执行
Worker继承了AbstractQueuedSynchronizer,任务进行中会进行加锁/解锁操作,关于它的更多介绍参见另一篇笔记Java锁和同步,下面的代码是Worker.run的精华部分
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
task.run();
afterExecute(task, null);
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}我们使用线程池时有一个经典的疑虑是: 我提交给线程池的Runnable.run方法抛出异常,运行这个run方法的线程会怎么样?答案是异常会导致线程结束(Terminated),但线程池能正常回收线程,不至于出错,当然还是要尽量避免这种情况,否则线程池的存在的意义就不大了。
2. 内置实现
应该说实现一个线程池并不是一个轻松的任务,好在Java为我们提供了内置实现,正常情况下我们只需要使用即可。使用Executors工具类,我们能十分轻松的创建这些线程池
| 线程池 | 描述 |
| Executors.newCachedThreadPool | WorkQueue采用了SynchronousQueue,优先创建线程,idle线程60秒后回收 |
| Executors.newSingleThreadExecutor | WorkQueue使用的是LinkedBlockingQueue,只有1个工作线程 |
| Executors.newFixedThreadPool | 线程数固定(corePoolSize==maxPoolSize),线程数由参数指定,WorkQueue使用的LinkedBlockingQueue |
上面线程池都是基于ThreadPoolExecutor实现的,ScheduledThreadPoolExecutor是用于支持周期性/定时调度的线程池,内部维护了时间优先级的延迟队列
| 线程池 | 描述 |
| Executors.newSingleThreadScheduledExecutor | 固定线程数,只有1个工作线程 |
| Executors.newScheduledThreadPool | 固定线程数,线程数由入参指定 |
ForkJoinPool用于支持fork-join任务,十分适合于处理计算密集型任务,后续会专门讲解
| 线程池 | 描述 |
| Executors.newWorkStealingPool | 支持fork-join任务,任务内部能拆解任务为RecursiveAction子任务,并将这些子任务提交调度,等待结果做合并 |
3. 获取结果
1. FutureTask
在此之前我们说的都是将Runnable对象提交给线程执行,没有去跟踪执行后的结果。现实中很常见的一种的场景是,我提交一个异步的数据获取任务,后续会来查看这个任务的执行结果,拿结果数据。
Java通过Callabe和Future接口来支撑这类场景,FutureTask实现了Runnable和Future接口,内部持有一个Callable对象。通过线程执行FutureTask的时候,会执行FutureTask的run方法
public void run() {
try {
Callable<V> c = callable;
V result;
try {
result = c.call(); // 获取执行结果
} catch (Throwable ex) {
result = null;
setException(ex); // 设置FutureTask的为执行异常
}
set(result); // 保存执行结果
} finally {
// 设置状态为已结束
}
}上面是FutureTask.run做删减了,只留下核心逻辑的代码。线程执行时,会先调用Callable的获取执行结果,执行成功或者执行异常时修改当前FutureTask状态(set、setException方法),方法内部通过LockSupport.park、LockSupport.unpark实现了线程的挂起和恢复。我们来看一个简单的示例
public static class ReadDB implements Callable<String> {
public String call() throws Exception {
System.out.println("reading ...");
sleep(5_000);
System.out.println("finish...");
return "HelloBody";
}
}
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newCachedThreadPool();
Future<String> read = es.submit(new ReadDB());
System.out.print("business logic goes here.")
String text = read.get(10_000, TimeUnit.MILLISECONDS);
System.out.println("blockAtGet: " + text);
}将ReadDB提交后,可以去处理其他业务逻辑,等其他逻辑都处理完后,在回过头来查看提交的ReadDB的执行结果,如果此时ReadDB未完成,调用get方法的时候依然是会阻塞的。
2. ExecutorCompletionService
上一节的方案存在的问题是,如果我们一次性提交多个任务并等待执行结果,无法确定哪个任务先完成,我只能按顺序调用每个FutureTask上的get方法。Java通过ExecutorCompletionService解决这个问题,下图是ExecutorCompletionService的个执行过程,额外维护了一个completionQueue队列,FutureTask在set方法(set、setException)时会将执行成功的FutureTask插入到completionQueue中。通过FutureTask拿结果数据的用户代码,从completionQueue里获取FutureTask。
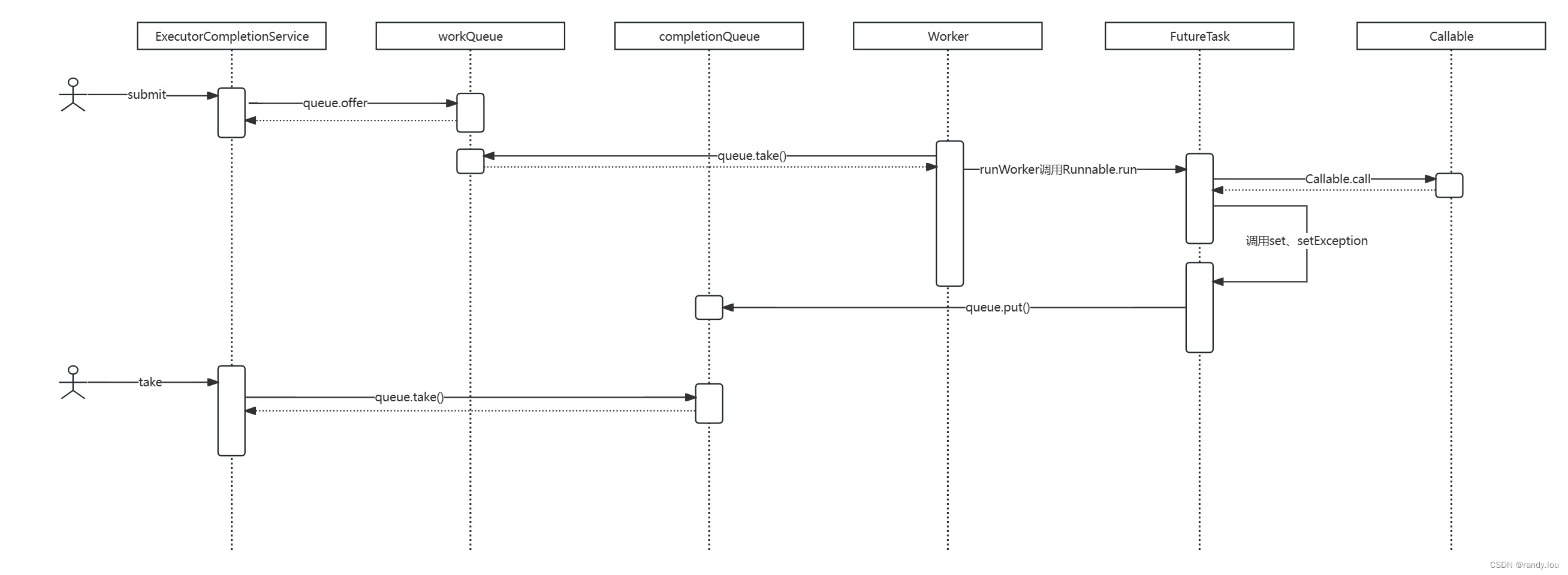
我们来看一个简单的示例,改造前面的ReadDB,这回按顺序提交2个任务: task1、task2,其中task1的执行时间要比task2长,我们期望按数据返回的顺序来处
public static class ReadDB implements Callable<String> {
private final int waitMs;
private final String taskId;
public ReadDB(String taskId, int waitMs) {
this.taskId = taskId;
this.waitMs = waitMs;
}
public String call() throws Exception {
System.out.println(taskId + " reading ...");
sleep(waitMs);
System.out.println(taskId + " finish...");
return "Hello " + taskId;
}
}
public static void main(String[] args) throws Exception {
ExecutorCompletionService<String> es = new ExecutorCompletionService<String>(Executors.newCachedThreadPool());
es.submit(new ReadDB("task1",10_000));
es.submit(new ReadDB("task2",5_000));
for(int i=0;i<2;i++) {
Future<String> fs = es.take();
System.out.println(fs.get());
}
}我们看一下输出,程序确实是按照预期执行的

3. CompletableFuture
ExecutorCompletionService可以让提交的多个任务,先运行结束的被先处理,但是仍然需要自己实现一个循环从completionQueue里取出执行结果并处理。CompletableFuture将这个过程也进行了抽象,使用回调函数处理响应结果,完全避免了程序中的同步。上面的例子,如果使用CompletableFuture实现,ReadDB不需要修改,仅仅修调用方的代码即可
public static void main(String[] args) {
ExecutorService es = Executors.newCachedThreadPool();
CompletableFuture.supplyAsync(new ReadDB("task1", 10_000)::call, es).thenAccept(System.out::println);
CompletableFuture.supplyAsync(new ReadDB("task2", 5_000)::call, es).thenAccept(System.out::println);
}CompletableFuture.supplyAsync支持传入ExecutorService,也可以不传,默认使用ForkJoinPool.commonPool()。CompletableFuture支持手动设置完成,大大降低了继承它的困难。用手动完成CompletableFuture实现ReadDB,代码是这样的,这种方式给我提供了极大的灵活性。
public static class CompletableReadDB implements Callable {
private final CompletableFuture<String> future;
private final int waitMs;
private final String taskId;
public CompletableReadDB(CompletableFuture<String> future, String taskId, int waitMs) {
this.future = future;
this.taskId = taskId;
this.waitMs = waitMs;
}
public String call() {
System.out.println(taskId + " reading ...");
sleep(waitMs);
System.out.println(taskId + " finish...");
future.complete("Hello " + taskId);
return "Hello " + taskId;
}
}
public static void main(String[] args) {
CompletableFuture<String> future = new CompletableFuture<>();
ExecutorService es = Executors.newCachedThreadPool();
es.submit(new CompletableReadDB(future, "taks1", 5_000));
future.thenAccept(System.out::println);
}
此外CompletableFuture提供了工具方法,让我们能组合CompletableFuture和函数式接口、多个CompletableFuture组合。
1. CompletableFuture组合函数式接口
假设在ReadDB读取数据后要把数据写入缓存,我们可以这么做:
CompletableFuture.supplyAsync(new ReadDB("task2", 5_000)::call).thenAccept(x->System.out.println("write in redis"));假设我们现在持有的是CompletableFuture<T>,为了简化表示,在说明里我把CompletableFuture简记为C<T>,其他操作支持包括:
| 方法名 | 函数X | 返回值 | 说明 |
| thenAccept | T->Void | C<Void> | 将C值传给函数X处理;返回C,值永远是null |
| thenApply | T->U | C<U> | 将C值传给函数X处理;返回C,值是入参函数的返回值 |
| thenCompose | T->C<U> | C<U> | 将C值传给函数X处理;返回函数X的返回值 |
| thenRun | Runnable | C<Void> | 在C运行结束后执行Runnable.run方法 |
| exceptionally | Throwable->T | C<T> | 在C异常时调用函数X,入参是异常对象,用函数X的返回值创建新的C |
| handle | (T,Throwable)->U | C<U> | 在C返回或异常时调用函数X,入参是C的值或捕获的异常;用函数X的返回值新建C |
| whenComplete | (T,Throwable)->Void | C<Void> | 和上面基本相同,只是函数X无返回值;方法返回C |
2. 多CompletableFuture组合
当我们有多个CompletableFuture要组合在一起使用时,比如我有两个CompletableFuture,分别是:
- CompletableFuture<String>,用于加载用户信息-用户名
- CompletableFuture<Long>,用户加载用户的账号信息-账户余额
我最终要将两份信息合并在一起,传递给前端现象,这个时候我们就会用到CompletableFuture的组合,下面是这种场景的一个极简示例
CompletableFuture<String> cName = CompletableFuture.supplyAsync(() -> "randy");
CompletableFuture<Long> cAccount = CompletableFuture.supplyAsync(() -> 10L);
cName.thenCombine(cAccount, (String n, Long c) -> n + c).thenAccept(System.out::println).get();假设我们现在持有的是CompletableFuture<T>,简记为C<T>,其他支持的操作包括:
| 方法名 | 组合C | 函数X | 返回值 | 说明 |
| thenCombine | C<U> | (T,U)->V | C<V> | 取C、C的值,传给函数X,返回C |
| thenAcceptBoth | C<U> | (T,U)->Void | C<Void> | 取C、C的值,传给函数X,返回C |
| runAfterBoth | C<?> | Runnable | C<Void> | 全部两个C执行完后,执行Runnable |
| runAfterEither | C<?> | Runnable | C<Void> | 任意一个C执行完后,执行Runnable |
| applyToEither | C<T> | T->V | C<V> | 其中一个C的结果,传递给函数X,函数X的返回值作为C的值,返回C |
| acceptEither | C<T> | T->Void | C<Void> | 同上,不过函数X返回Void |
3. CompletableFuture超时
通过设置CompletableFuture,可以超时未返回是提供一个默认值,或者抛出异常。比如通过设置completeOnTimeOut(defaultValue, timeNum, timeUnit),如果超过timeNum的时间CompletableFuture还没执行结束,会将defaultValue作为CompletableFuture的值。
CompletableFuture.supplyAsync(new ReadDB("task2", 5_000)::call).completeOnTimeout("NoData", 5, TimeUnit.MILLISECONDS).thenAccept(...);还有一种方式是,直接抛出异常
CompletableFuture.supplyAsync(new ReadDB("task2", 5_000)::call).orTimeout(5, TimeUnit.MILLISECONDS).thenAccept(...)4. allOf、anyOf
如果我们有多个CompletableFuture,我们希望等待所有CompletableFuture或其中任意一个CompletableFuture运行结束后,再继续。假设有两个CompletableFuture
CompletableFuture<String> cName = CompletableFuture.supplyAsync(() -> "randy");
CompletableFuture<Long> cAccount = CompletableFuture.supplyAsync(() -> 10L);如果我们要等两个CompletableFuture都运行结束,就需要使用allOf
CompletableFuture.allOf(cName, cAccount).get();如果我们要等两个CompletableFuture中任意一个运行结束
CompletableFuture.anyOf(cName, cAccount).get();4. fork-join
Java7开始引入fork-join框架,适用用计算密集型的大型任务,核心思想是将一个大任务拆解为多个小任务,收集每个小任务的结果,最后组装成完整的结果,分而治之是大规模系统的常见方案。
我们来看一个例子,假设我们有100个数字,对每个数字都要进行复杂的计算后得到一个结果,我们用fork-join来统计这些计算结果,包括总和、个数统计、均值。我们先定义一个类来存储结果
public static class Stat {
private int total;
private int count;
public Stat(int total, int count) {
this.total = total;
this.count = count;
}
public int getTotal() {
return total;
}
public int getCount() {
return count;
}
public double getAvg() {
return 1.0 * total / count;
}
}通过继承RecursiveTask、RecursiveAction类来实现fork-join的计算操作,简单代码如下:
public static class StatWorker extends RecursiveTask<Stat> {
private List<Integer> input;
private String name;
public StatWorker(List<Integer> input) {
this.input = input;
this.name = "Worker" + input.get(0);
}
protected Stat compute() {
if (input == null) {
return new Stat(0, 0);
} else if (input.size() < 10) {
int total = 0;
int count = input.size();
for (Integer item : input) {
total += veryHeavyCalculate(item);
}
return new Stat(total, count);
} else {
int middle = input.size() / 2;
List<Integer> half1 = input.subList(0, middle);
List<Integer> half2 = input.subList(middle, input.size());
StatWorker stat1 = new StatWorker(half1);
StatWorker stat2 = new StatWorker(half2);
invokeAll(stat1, stat2);
Stat s1 = stat1.join();
Stat s2 = stat2.join();
int total = s1.total + s2.total;
int count = s1.count + s2.count;
return new Stat(total, count);
}
}
private int veryHeavyCalculate(int i) {
sleep(1000); // 模拟耗时的操作
return i;
}
}最后通过fork-join框架来调度上面的计算任务
public static void main(String[] args) {
List<Integer> data = Stream.generate(new Supplier<Integer>() {
int i = 1;
public Integer get() {
return i++;
}
}).limit(100).collect(Collectors.toList());
var pool = new ForkJoinPool();
StatWorker worker = new StatWorker(data);
pool.invoke(worker);
Stat result = worker.join();
System.out.println("total:" + result.getTotal() + " ,count:" + result.getCount() + " ,avg:" + result.getAvg());
}应该说在特定场景下,Fork-Join框架是还是很有用的。
5. 虚线程
Java 21开始正式提供虚线程的支持,在其他编程语言里它又被称为协程、纤程等。现在Java将线程区分为两类:
- Java 21的线程,现在被称为平台线程(platform thread),一个平台线程对应着一个本机线程(os thread),能支持的数量有限,一般不会超过几千
- 虚线程,Java运行时系统负责调度,虚线程不绑定本机线程
虚线程适合于调度IO密集型的程序,在IO阻塞后,Java运行时会将当前虚线程的本机线程用以执行其他虚线程,虚线程核心目标是提高系统的吞吐量和扩展性。
平台线程是由操作系统调度的,而虚线程是由Java运行时调度的。当Java运行时调度一个虚拟线程时,会将一个平台线程和它绑定,然后操作系统正常的调度这个平台线程。被绑定的平台线程有个名字叫carrier。当虚拟线程运行到阻塞节点(如阻塞IO)后,会解除和carrier的绑定。这时候carrier就空闲了,Java运行时会将其他虚线程调度到这个carrier上。Pinned虚线程禁止和carrier解除绑定,导致长期占用要给carrier,要尽量避免。
Pinned虚线程正在运行特殊代码的虚线程,分别是: 1. 当前正在执行synchronized模块或方法的虚线程; 2. 当前正在执行native方法、外部方法(foreign function)的虚线程
1. 如何使用
1. 直接创建
我们可以通过Thread API创建虚拟线程,通过Thread.Builder能修改线程的属性信息,除了Thread.ofVirtual()外,可以通过Thread.ofPlatform()来创建平台线程
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Hello"));
thread.join();
Thread.Builder builder = Thread.ofVirtual().name("worker-1"); // 指定线程名
Runnable task = () -> System.out.println("Running thread");
Thread t = builder.start(task);
t.join();2. ExecutorService
Java为虚线程提供了ExecutorService实现,通过调用Executors.newVirtualThreadPerTaskExecutor()来创建对应的ExecutorService实现。每次调用submit都会自动创建一个虚线程,Future.get()会阻塞到任务运行完,这些和虚线程之前的实现都并无不同。不同的是ExecutorService实现了Autocloseable,并使用try-with-resource创建和自动关闭ExecutorService,调用close方法后ExecutorService会等待自己创建的Virtual Thread都执行完毕会回收。
try (ExecutorService es = Executors.newVirtualThreadPerTaskExecutor()) {
Future<?> future = es.submit(() -> System.out.println("hello"));
future.get();
}2. 使用指南
虚线程和平台线程最大的区别是,我们甚至能在一个进程内创建百万级虚线程,我们可以在服务端为每个请求创建一个虚线程,来提高服务的吞吐量,充分利用硬件资源。虚线程遵循了平台线程的抽象,依然使用Thread的API,所以我们并不需要为了使用虚线程学习额外的API。因为虚线程和平台线程的实现不同,部分适用于平台线程的最佳实践并不适用于虚线程。
1. 使用同步的BIO,不用异步的回调
拿Web容器举例来说,在虚线程之前,一般是使用线程池来处理用户请求,而这个线程池中线程的数量是极其有限的,一般也就是千这个数量级的。因此会尽可能避免阻塞这些线程。所以在服务器变成中进程看到异步/回调的代码,使用CompletableFuture、NIO等等。比如Oracle官网给的这个例子,先尝试获取url,用url读取页面,找页面中的图片url,用图片url获取图片。
CompletableFuture.supplyAsync(info::getUrl, pool)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofString()))
.thenApply(info::findImage)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofByteArray()));使用虚线程后服务器端一般都用thread-per-request模式,阻塞虚线程成本很低,可以直接用同步API,这样的代码更容易理解,也更容易DEBG和监控
try {
String page = getBody(info.getUrl(), HttpResponse.BodyHandlers.ofString());
String imageUrl = info.findImage(page);
byte[] data = getBody(imageUrl, HttpResponse.BodyHandlers.ofByteArray());
} catch (Exception ex) {
t.printStackTrace();
}2. 每个任务创建一个虚线程,不要使用虚线程池
平台线程创建成本是高昂的,因此过去我们一般都使用线程池来避免频繁的创建和消耗线程。使用虚线程后,通过ExecutorService提交任务,这个ExecutorService都不应该被共享,每个任务每次执行都创建新的虚线程。Executors.newVirtualThreadPerTaskExecutor并不会创建线程池,新建的ExecutorService是轻量级的,try-with-resource会调用ExecutorService的close方法,close方法会在由这个ExecutorService创建的所有虚线程结束后清理。
try (ExecutorService es = Executors.newVirtualThreadPerTaskExecutor()) {
Future<ResultA> f1 = es.submit(task1);
Future<ResultB> f2 = es.submit(task2);
}3. 用Semaphore限制并发
在使用平台线程的时候,我们往往会建立线程池,如果想要控制调用三方服务的并发,可以采用固定线程数的线程池,比如下面这段代码,因为线程的上限就是10,调用服务的并发上限不可能超过10
ExecutorService es = Executors.newFixedThreadPool(10);
var fut = es.submit(() -> callLimitedService());改用虚线程后就没法使用固定线程数线程池来控制了,需要使用Semaphore,执行调用三方服务的代码看起来应该是类似这样的
Semaphore sem = new Semaphore(10);
sem.acquire();
try {
return callLimitedService();
} finally {
sem.release();
}
4. 谨慎使用ThreadLocal
ThreadLocal在现代服务端开发中使用的很频繁,在用户请求服务端的时候,我们解析完登录状态,往往会把UserID保存在ThreadLocal中,方便后续的服务读取,在Spring中声明式事务中,就是通过ThreadLocal跨方法传递事务状态。在使用虚线程后,这两种场景依然可以通过ThreadLocal支持,Oracle开始引入ScopedValue来解决这类需求。
有一种特殊场景是,如果由创建成本高而又不是线程安全的类时,之前我们也是放到ThreadLocal中的比,比如SimpleDateFormat,为了避免它被重复创建
static final ThreadLocal<SimpleDateFormat> YFORMAT = ThreadLocal.withInitial(SimpleDateFormat::new);
void logic() {
YFORMAT.get().format(...);
}在基于平台线程的时候,这种方法确实是奏效的,因为平台线程的个数是有限的,而且往往会使用线程池,因此经过特定次数的初始化后,就不再需要创建新的SimpleDateFormat了。然而虚线程从来不缓存重用线程,每次都会新建虚线程,这个操作就没有任何实际意义,反而多浪费了一个ThreadLocal的操作。
A. 参考资料
- The Linux Thread Implementation,链接: CS249 Systems Programming: Linux Threads
- How an Operating System Loads and Executes a Program,链接: How an Operating System Loads and Executes a Program
- Operating System: What is a process ?,链接: https://www.cs.bham.ac.uk/~exr/teaching/lectures/opsys/15_16/lectures/os_09_processes.pdf
- Java Thread LifeCycle,链接: Life Cycle of a Thread in Java | Baeldung
- Virtual Thread,链接: Virtual Threads
- JEP 444,链接: JEP 444: Virtual Threads
- ScopedValue,链接: Scoped Values















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









