







1. 面对问题
1. 可见性
我们直到现代的CPU基本都是多核多Socket架构,如图所示,一个CPU上有两个物理核,每个物理核中又有2个逻辑核。分时操作系统将逻辑核的时间分片,用来执行不同的线程。线程的执行是依赖于CPU的一级、二级、三级缓存以及主内存(堆栈)。
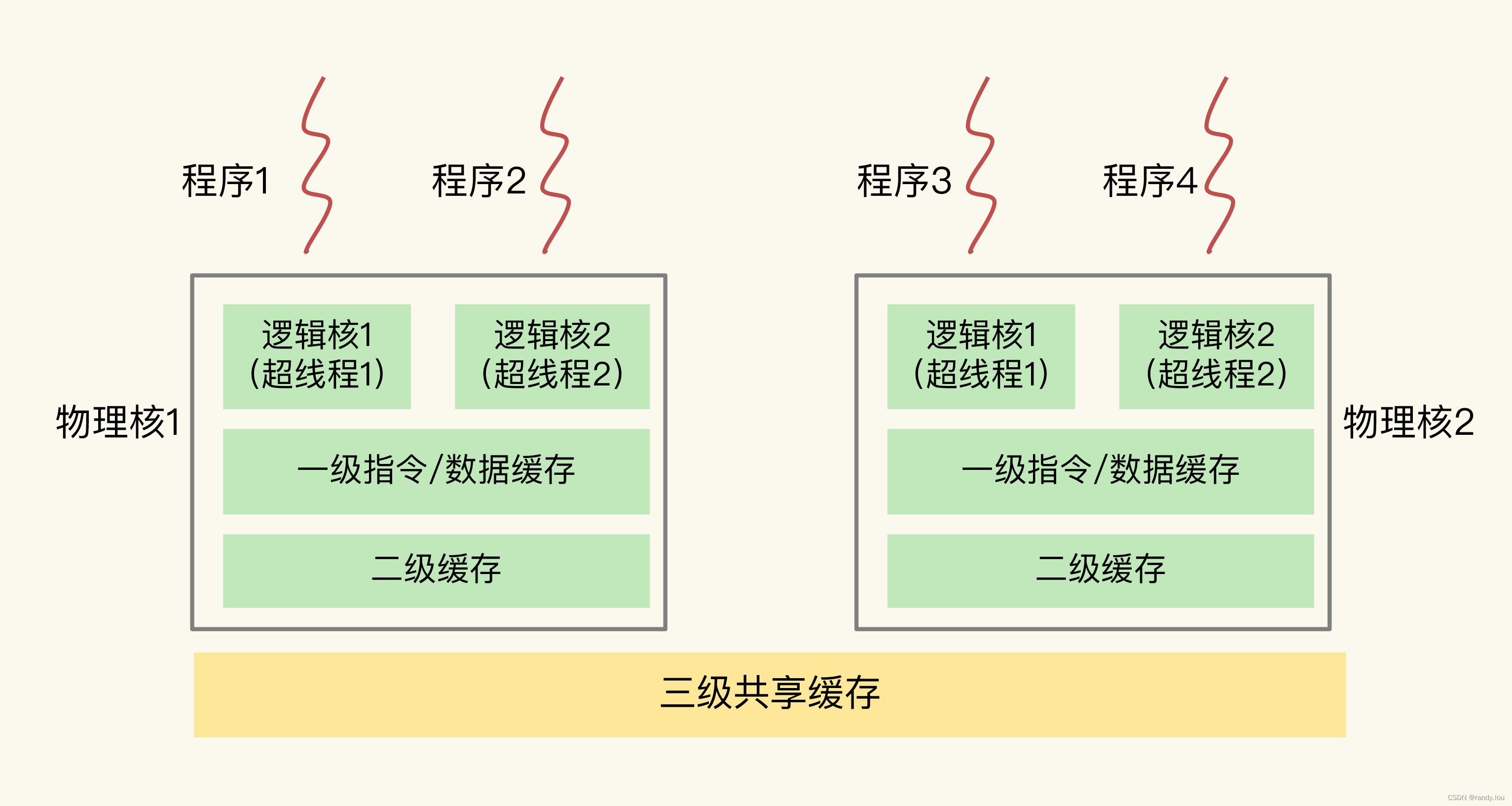
作为Java工程师对缓存的概念肯定特别熟悉,做Web服务的时候我们往往会将数据做Redis缓存,而实际数据存在MySQL,这么做确实让服务的运行效率大大提高了,同时也带来一个让人头疼的问题: 缓存数据的一致性问题。CPU缓存也遇到了同样的问题,JMM里把它称为可见性。
2. 原子性
对应用程序来说线程调度是没有规律可循的,看似一段简单的代码,可以在任意位置挂起。以一个例子来说,我们想要做的就是简单的递增
public int incrementAndGet() {
return id++;
}编译成字节码后并没有看起来这么简单,对应的字节码如下(删除了Code里部分字节码),它会被拆成4步,加载id的值(Code:2),加载常量1(Code:6),将id和1相加(Code:7),写入到id字段(Code:8)
public int incrementAndGet();
Code:
2: getfield #7 // Field id:I
6: iconst_1
7: iadd
8: putfield #7 // Field id:I我们假设两个线程同时运行在不同物理核,主内存中id值是1,CPU空缓存,它的执行顺序可能是这样的,调用了两次incrementAndGet但是生成了重复的id
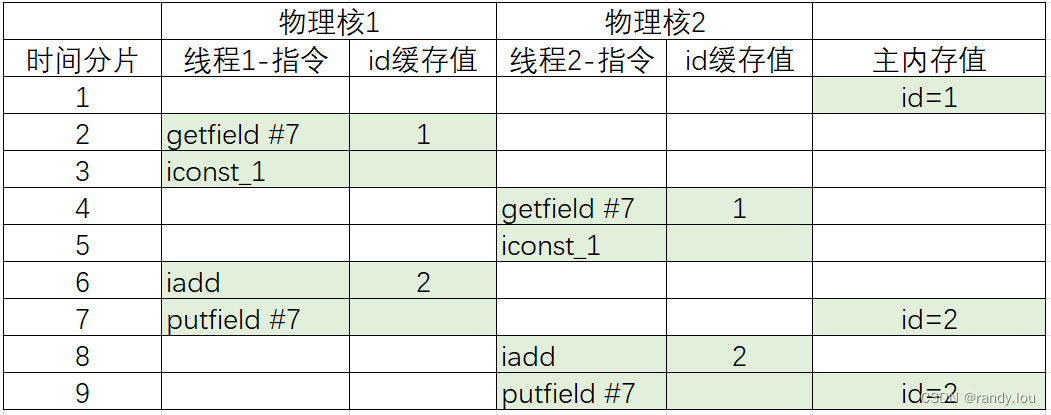
Java工程师对这类问题应该也很熟悉,做电商业务时下单后要对商品库存扣减,同样会遇到类似的问题,解决方案就两种: 悲观锁、乐观锁。在JVM层面也提供了这两种方式解决的,锁/同步块就是悲观锁,CAS就是乐观锁。
2. 解决方案
1. volatile
可见性问题的本质是线程在会从缓存读取变量值(读过期值)、写入会暂存在缓存后续在刷新到主内存(写入延迟),此外在不影响执行结果的情况下,虚拟机运行对指令进行重排。
我们用一个例子来讲一下指令重排的问题,假设我们有两个共享变量: finished和result
private boolean finished;
private int result;有一个Worker线程,先计算并修改result的值,设置完后,将finished修改为true,表示任务计算完成
public class Worker implements Runnable {
public void run() {
result = 1;
finished = true;
}
}有一个Reporter线程,判断任务是否完成,如果完成的话执行完成逻辑,如果未完成的话执行等待逻辑
public class Reporter implements Runnable {
public void run() {
if (finished) {
System.out.println("完成逻辑," + result);
} else {
System.out.println("等待逻辑," + result);
}
}
}
这里最违反直觉的是,即使我们在Reporter线程上读到finished=true时,也不保证能读到result=1,Worker.run中的命令可能会被重排序,先执行finished=true,然后再设置result=1。
volatile能完整的解决这一节提到的问题,根据不同的操作,volatile提供了3中保障
- 对volatile字段的写,不会把值暂存到寄存器,直接写入到主内存
- 对volatile字段的读,会清空寄存器缓存,重新重主内存加载数据
- 对volatile字段的写,编译器保证不会把volatile写之前的代码重排到volatile写之后,反之亦然
2. synchronized
volatile只能保证可见性,synchronized除了可见性还是先了原子性,可以将任意Java对象当做锁,一个线程进入synchronized同步块后,其他线程必须阻塞等待,直到前面的线程释放锁,释的条件是:
- 同步块执行结束
- 同步块抛出异常
- 同步块内调用了wait系列方法,导致释放锁
synchronized也提供了和volatile相同的内存语义,进入synchronized同步块时,清除寄存器缓存,直接从主内存读变量;退出synchronized同步块之前,将共享变量的修改刷新到主内存。
public synchronized int incrementAndGet() {
return id++;
}Java内置的ReentrantLock、ReentrantReadWriteLock都提供了synchronized同步块的类似的能力,更强大的是获取锁的时候,支持设置最长的等待时间,支持更细粒度的读写锁。
synchronized同步块对应我们在原子性里提到的悲观锁,没有获得锁的线程就会阻塞,导致当前线程挂起,操作系统重新调度。
3. compareAndSwap
compareAndSwap是JDK提供的乐观锁方案,通过现代CPU单指令支持cas保证了原子性,Java正是利用CPU的这个能力。Java通过Unsafe类对外暴漏能力,compareAndSwapInt是其中一个方法
public final boolean compareAndSwapInt(Object o, long offset,int expected,int x) 这4个参数定义如下,含义是如果对象o的字段offset当前值是expected,将字段值设置x
- o: 待修改的对象
- offset: 待修改的字段的偏移量
- expected: 预期的当前值
- x: 新的值
想想我们在数据库使用乐观锁时SQL是怎么写的,是不是感觉有异曲同工之妙呢,oldStock就是expected,newStock就是x,version一般都是单调递增的,提供了更强的保护,避免ABA问题
UPDATE product SET stock = #{newStock}, version = #{newVersion} WHERE id = #{id} and stock = #{oldStock} and version = #{version}关于ABA问题,我们举个例子来看,时间点1,线程1和线程3都读取到变量v的值1;时间点2,线程1将变量v改成了2;时间点4,线程2将变量再改回为1;时间点5的时候,线程运行cas(1,3),预期值依然正确,成功将变量v修改为3,线程3没有识别到时间点1到时间点4直接对变量v的修改。
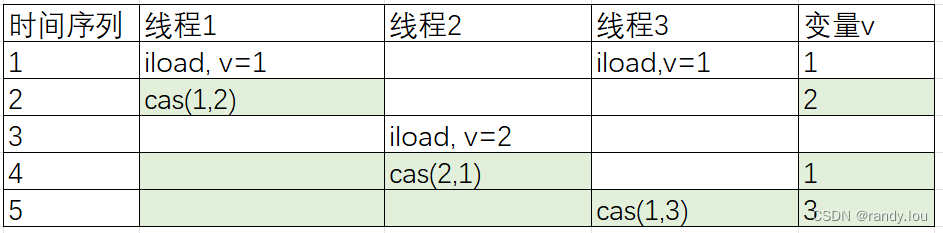
如果变量值是单调递增的,并不会有ABA问题,如果变量值不可避免的有环形转换,Java也提供内置类型AtomicStampedReference支持基于版本号的compareAndSwap。
我们拿一个例子来看AtomicStampedReference怎么使用,假设我们有一个商品,初始库存是10,基于cas提供一个方法来扣减库存,代码看起来是这样的
public static class Product {
private AtomicStampedReference<Integer> data = new AtomicStampedReference<>(10, 0);
public boolean buy(int count) {
int stock;
int version;
int remainStock;
do {
stock = data.getReference();
version = data.getStamp();
if (stock < count) {
return false;
}
remainStock = stock - count;
} while (!data.compareAndSet(stock, remainStock, version, version + 1));
return true;
}
}














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









