







概述
背景介绍
根据《服务器高可用恢复演练方案》文档介绍,验证基于 CLB 负载均衡下部署多台 CVM 的高可用。
目标要求
通过混沌演练故障注入,验证 A 系统的 RPO 不超过 4 小时,RTO 不超过 12 小时。
实施人员
* 演练实施组:小D
* 业务验证组:小E、小F
测试对象
A 系统的 prd1 生产环境
操作时间
2023-06-25 15:00 ~ 18:00
记录
Linux内核故障恢复演练
故障模拟
在 prd1 服务器节点注入Linux内核故障。
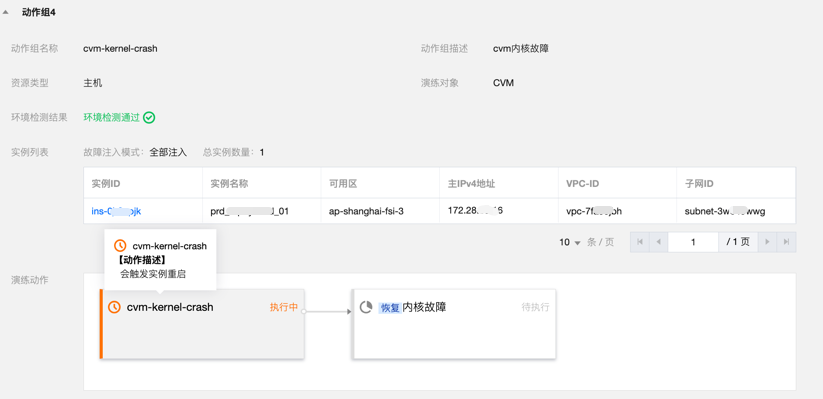
控制台显示 “执行中”。
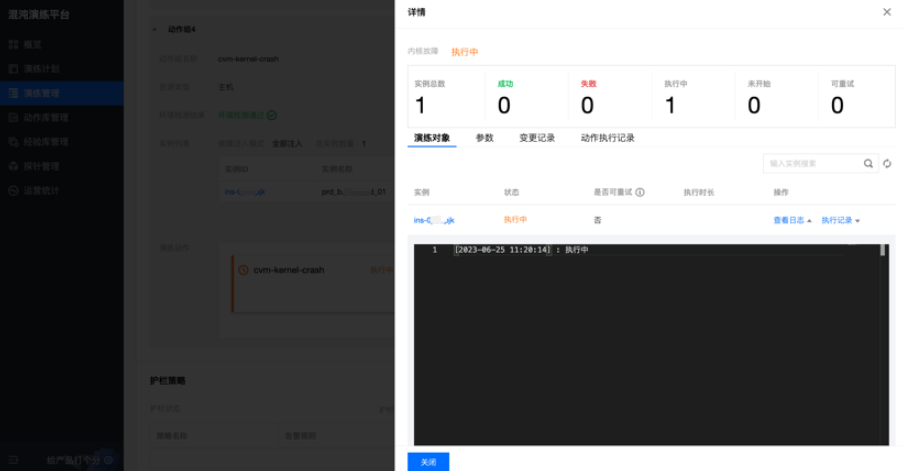
等待执行完成后,我们连接这台服务器的 ssh 会话自动退出,说明故障注入已生效。
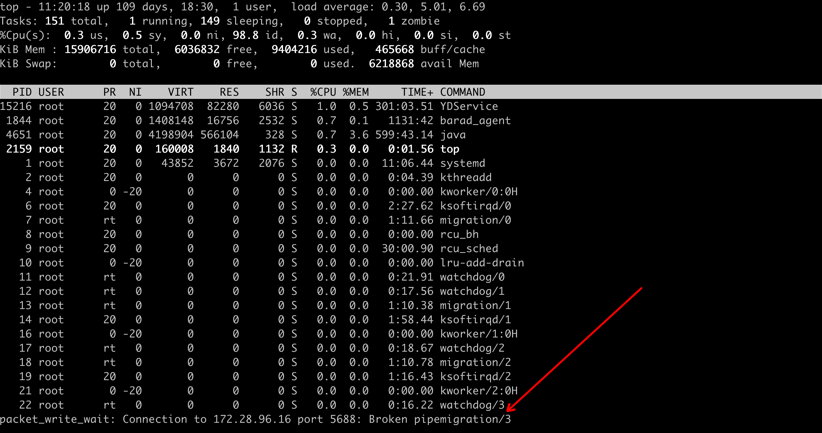
过程记录
Linux 内核故障注入总共持续了 30 分钟,表现如下:
持续访问生产环境,出现短暂几秒的接口报错。在 CLB 探测 prd1 环境端口异常之后,访问生产环境的接口不再出现报错。
短信收到系统告警,提示 prd1 服务器异常。
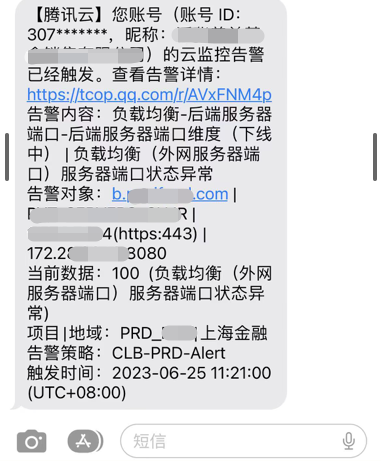
关闭故障注入,重启 prd1 服务器后,ssh 登录 prd1 服务器成功,但发现应用进程已经停止,没有再次启动,需要手动重启。
结果验证
- 首次故障注入后,业务接口出现短暂的报错,CLB 在几秒内检测到目标 CVM 不可用,业务请求随后恢复正常,符合预期。
- 系统自动告警,恢复服务器,因内核故障导致应用进程无法启动,手动执行脚本启动进程,切回 CLB,业务请求正常,符合预期。
现场还原
控制台执行 Linux 内核故障注入结束后,重启服务器即可。
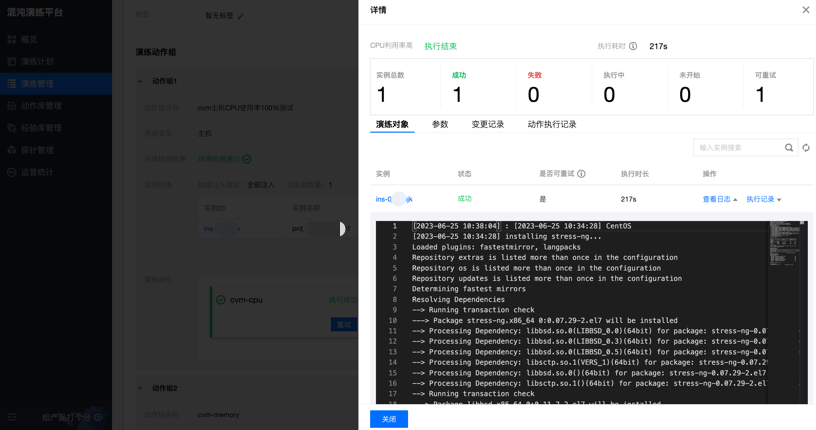
CPU利用率100%恢复演练
故障模拟
在 prd1 服务器节点注入CPU压力测试。
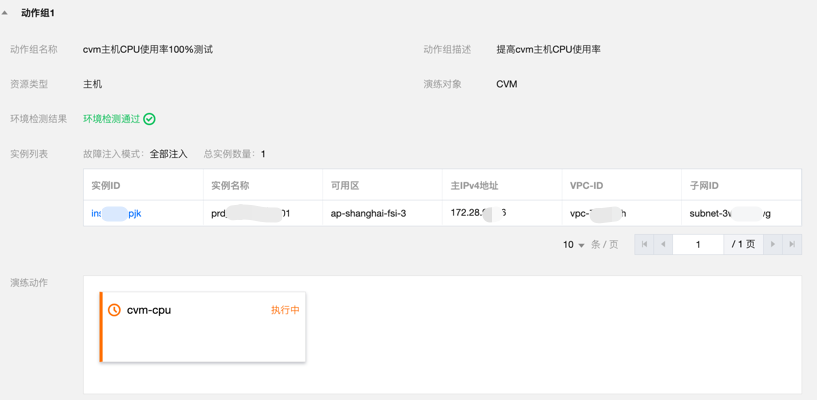
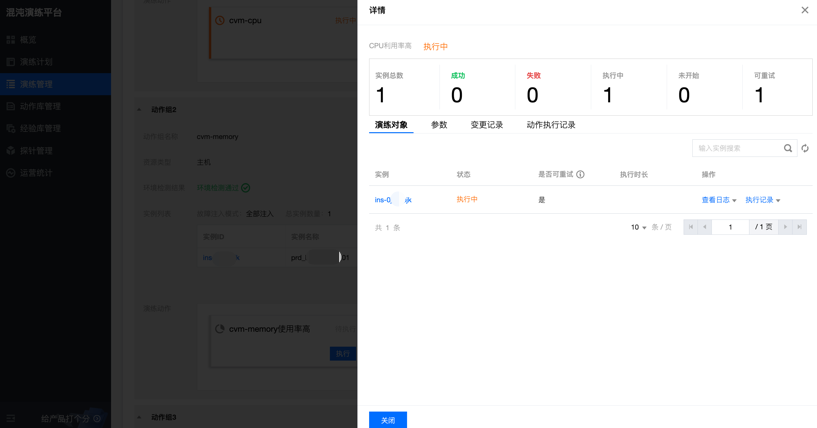
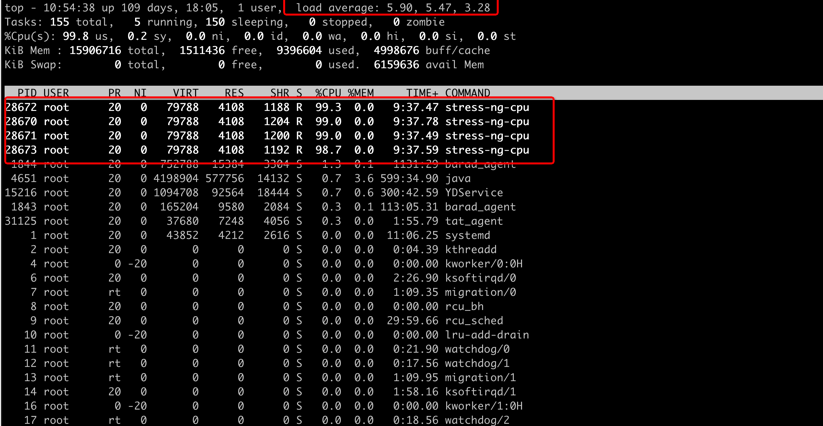
使用 ssh 登录服务器执行 Top 命令,查看产生了 4 个 stress-ng-cpu 进程(服务器的 CPU 规格为 4 核),CPU 的负载分别达到 5.90 5.47 3.28,说明故障注入已生效。
过程记录
CPU 故障注入总共持续了 10 分钟,系统仍然可以正常访问,原因是服务器只部署了 Nginx 进程,后端服务不在节点,而是部署在 K8s 集群。
结果验证
CPU 高负载对服务器 Nginx 进程的影响较低。
现场还原
使用 HTTP 发起 GET 查询请求,不会产生测试数据,不需要还原。
控制台执行完成后,stress-ng-cpu 驻留进程自动被清除,不会影响正常的应用访问。
内存利用率100%恢复演练
故障模拟
在 prd1 服务器节点注入内存压力测试。
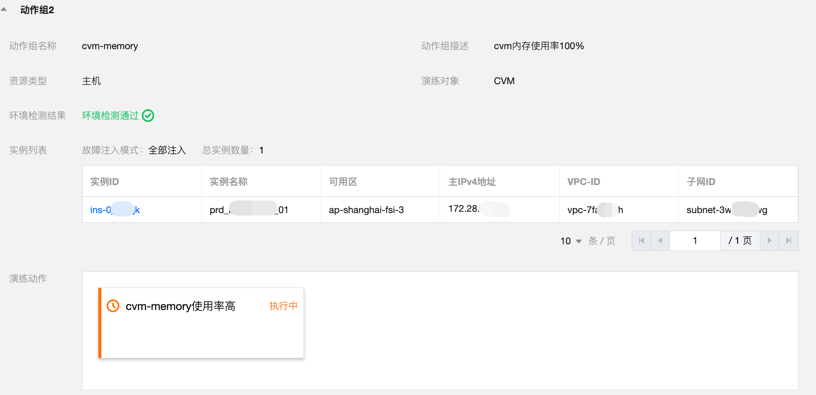
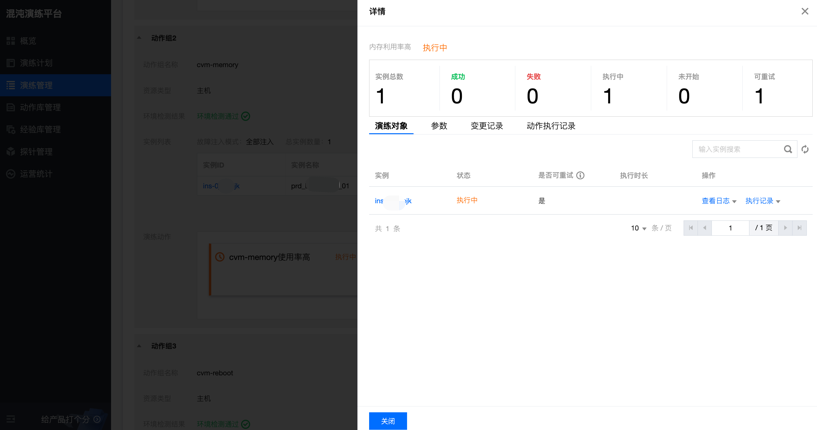
使用 ssh 登录服务器执行 Top 命令,查看产生了 1 个 stress-ng-vm 进程(服务器的内存规格为 8 GB),内存持续增长,导致进程 CPU 达到 100%,说明故障注入已生效。
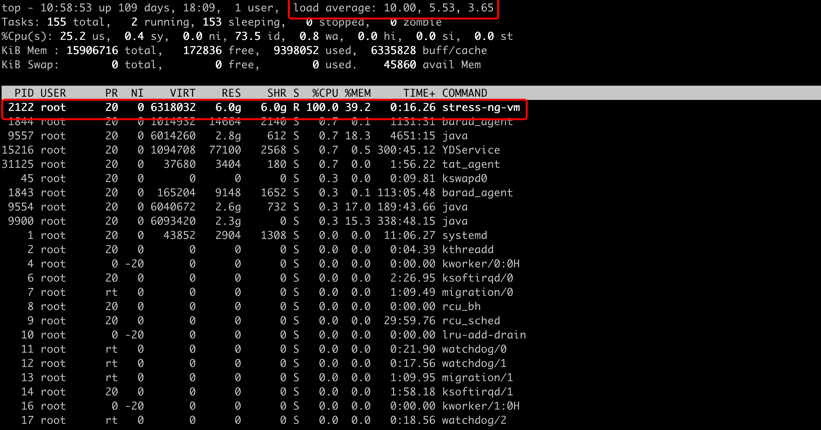
过程记录
系统响应延迟,接口返回超过 10 秒,从用户的层面来看,会认为系统卡顿。
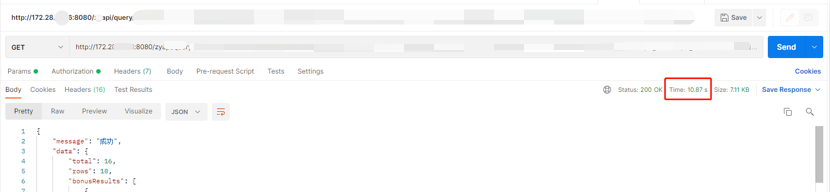
结果验证
当内存使用率达到 100%,系统响应时间会变长,CLB 心跳探测异常,将该节点从 CLB 中摘除,后续业务请求正常,符合预期。
现场还原
使用 HTTP 发起 GET 查询请求,不会产生测试数据,不需要还原。
控制台执行完成后,stress-ng-vm 驻留进程自动被清除,不会影响正常的应用访问。
机器重启恢复演练
故障模拟
在 prd1 服务器节点注入内存压力测试。
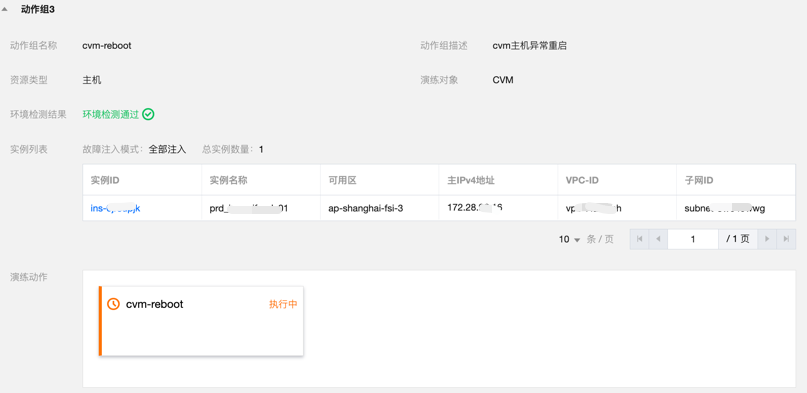
过程记录
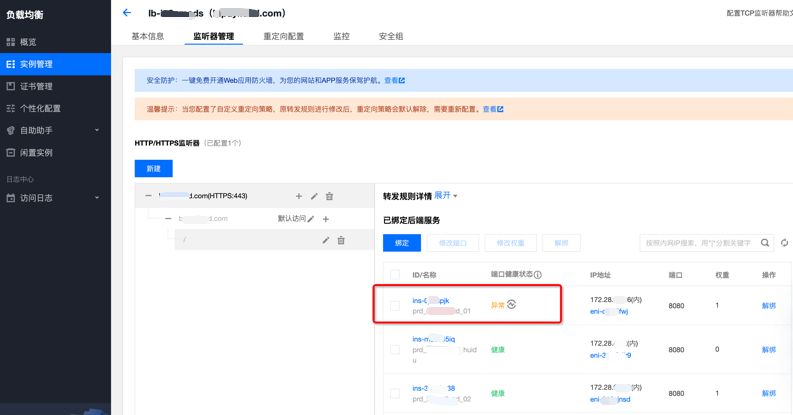
系统重启很快,从用户感官上没有出现接口报错。因 Nginx 进程未启动,导致 CLB 无法探测到该节点,后续业务请求会失败。CLB 显示后端服务端口异常,如下图。
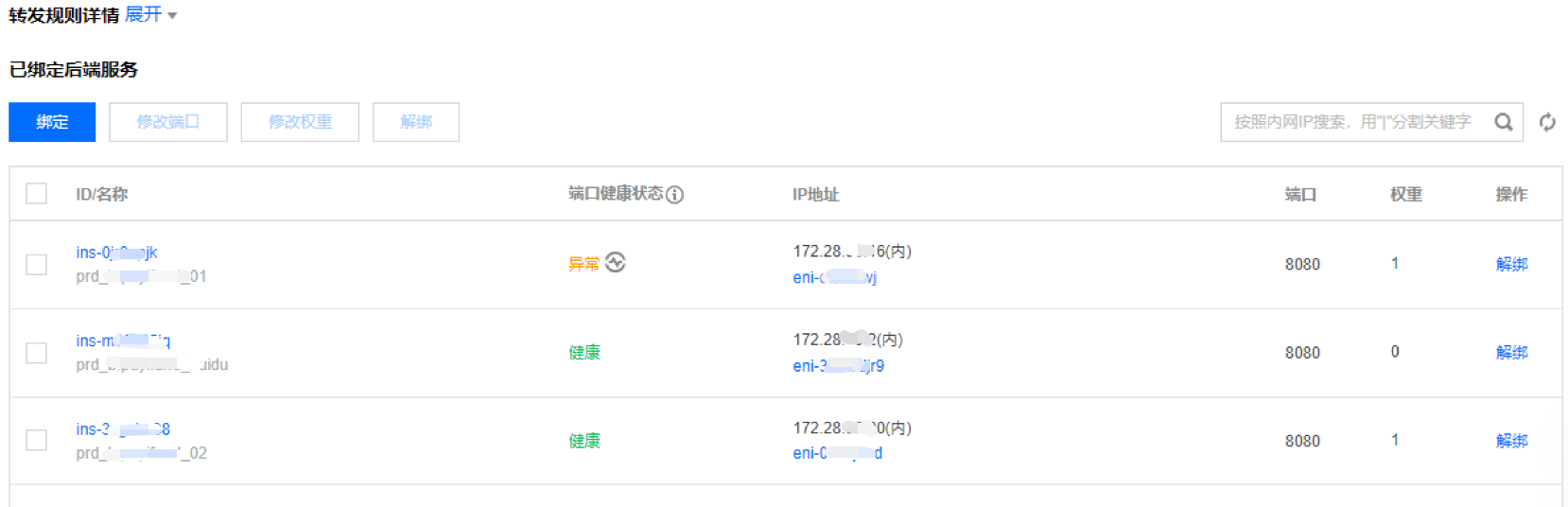
启动 Nginx 进程后,CLB 节点恢复正常。
结果验证
机器节点重启后,对业务的请求影响较小,符合预期。
现场还原
使用 HTTP 发起 GET 查询请求,不会产生测试数据,不需要还原。
总结
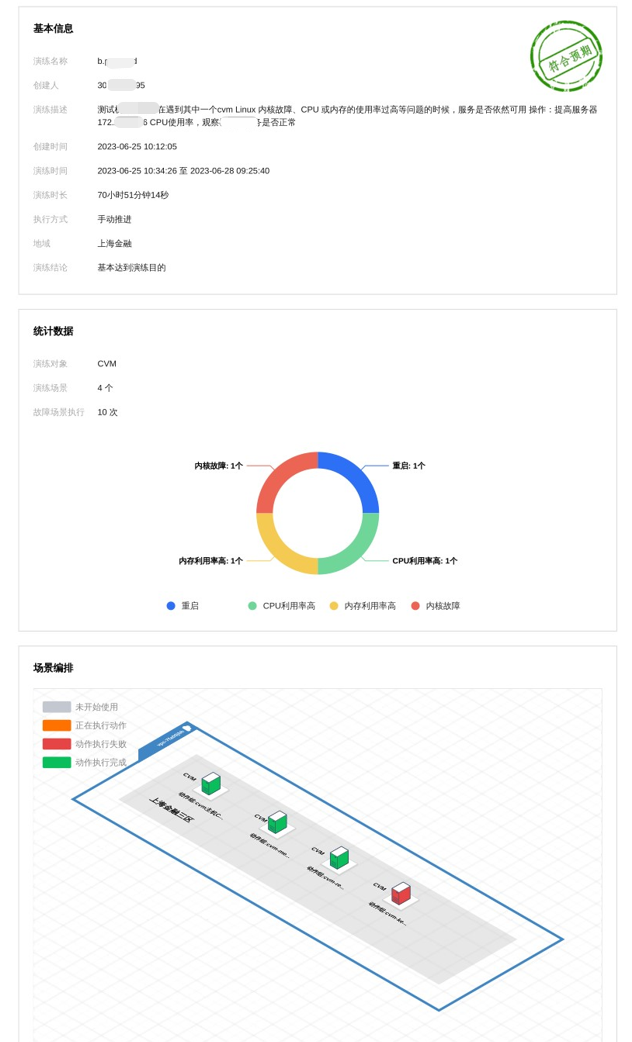




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











