







一、PartB:优化矩阵转置
最简单的矩阵转置实现:
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < M; ++j)
{
dst[j][i] = src[i][j]
}
}
注意事项:
- 最多只能定义12个局部变量。
- 不允许使用位运算,不允许使用数组或者malloc。
- 不能改变原数组A,但是可以修改转置数组B。
- 只需要正确处理32×32(不命中次数m < 300)、64×64(m < 1300)以及61×67(m < 2000)三种矩阵即可,针对输入的大小,可以分别处理这三种情况。
思路及实现要点:
- block的大小为32byte,即可以放下8个int,即miss的最低限度是1/8。
- cache的大小为32*32,即32个block,256个int。
- blocking是一种很好的优化技术,这次实验基本就靠他了;)其大致概念为以数据块的形式读取数据,完全利用后丢弃,然后读取下一个,这样防止block利用的不全面。可以参考卡耐基梅隆的一篇文章: waside-blocking
- 尽量将一个block读入完全或者写入完全,例如假设一个block可以放两个数,进行如下转置操作,其读取时“尽力”读取,完全利用了一个block,但是在写入的时候浪费了1/2的空间。
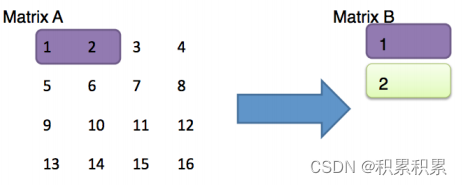
- 尽量使用刚刚使用的
block(还是“热乎的”),因为它们很可能还没有被替换,hit的概率会很大。 - 读出和写入的时候注意判断这两个位置映射在cache中的位置是否相同,(我们这个cache是直接映射,一个set只有一个block,所以绝大部分的miss伴随着替换),也可以说,我们要尽量避免替换的发生。
二、PartB:32*32
题目要求miss<350
-
在32*32的情况中,一行是32个int,所以cache可以存8行,也就是每8行会消耗一个cache。
-
由此可以推出映射冲突的情况:只要两个int之间相差8行的整数倍,那么读取这两个元素所在的block就会发生替换,比如(0, 0)、(8,0)、(16,0)、(24,0)是冲突的。但是这种冲突在转置的情况下不大容易发生。水平方向每个格子代表一个cacheline(8个int)。每个格子里面存在8个cacheline。对于非对角线的部分而言不会存在A和B读写导致的缓存冲突
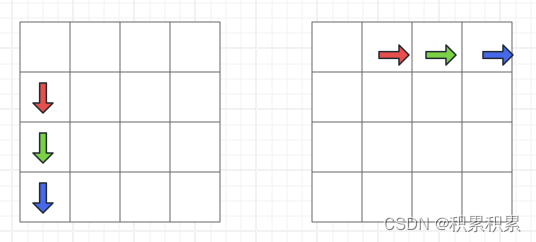
- 我们取分块矩阵的大小为8*8,如果存在某个点A[i][j],且i==j,那么B[i][j]和A[i][j]会映射到同一个cacheline当中,从而产生cacheline的访问冲突,这里有两种方法可以解决访问冲突:
- 由于我们可以使用12个局部变量,所以我们可以用8个局部变量一次性将包含对角线int的cacheline全部读出,这样即使写入的时候替换了之前的block也不要紧,因为我们已经全部读出了。
- 我们用一个局部变量暂时先保存这个对角线元素,并用另一个变量记录它的位置,待block的其他7个元素写完以后,我们再将这个会引起替换的元素写到目的地。
2.1 版本1
// 没有对于对角线进行优化
void trans(int M, int N, int A[N][M], int B[M][N])
{
int i, j;
for (i = 0; i < N; i+=8) {
for (j = 0; j < M; j+=8) {
for(int ii=i; ii < i+ 8; ii++){
for (int jj=j; jj < j+8; jj++){
B[jj][ii] = A[ii][jj];
}
}
}
}
}
运行结果:
// func 1 (Simple row-wise scan transpose): hits:1709, misses:344, evictions:312
分析:
// A read(0,0) miss => load A0_line
// B write(0,0) miss => evict A0_line, load B0_line
// A read (0, 1) => evict B1_line, load A1_line
// B write(0, 1) => evict A1_line, load B1_line
----------------------------------------
// 对于cacheline1而言, 但是后面两个miss只要我将A的cacheline中的内容进行缓存就可以避免
// B write(1, 0) load B1_line
// A read (1, 0) evict B1_line, load A1_line
// A read (1, 1) hit
// B write(1, 1) evict A1_line, load B1_line
// A read (1, 2) evict B1_line, load A1_line
// B write(2, 1) (3, 1)...
// B write (1, 2) evict A1_line, load B1_line
2.2 版本2
void trans(int M, int N, int A[N][M], int B[M][N])
{
int i, j;
int a, b, c, d, e, f, g, h;
for (i = 0; i < N; i+=8) {
for (j = 0; j < M; j+=8) {
for(int ii=i; ii < i+ 8; ii++){
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
e = A[ii][j + 4];
f = A[ii][j + 5];
g = A[ii][j + 6];
h = A[ii][j + 7];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
B[j + 4][ii] = e;
B[j + 5][ii] = f;
B[j + 6][ii] = g;
B[j + 7][ii] = h;
}
}
}
}
三、PartB:64*64
- 数组一行存在64个int也就是8个
cacheline,所以每四行就会填满一个cache。这就会导致直接行转列的话,前4行会被后4行顶出来。这里可以将8*8的矩阵分成4个4*4来处理
步骤一:将A的区域1转置到B的区域1;将A的区域2转置到B的区域2,这样可以充分利用B的cacheline,此时B2的应该在B3
步骤二:用同样的方式对于区域3、4进行操作。然后交换B2和B3,即可
但是,测试以后并不能满足优化的要求,说明我们将23转换的时候(或是之后)又发生很多miss,我们可以尝试在区域3、4转化的过程中,对于B2区域进行复原。
这里的复原是整个实验中最具技巧性的,由前面的要点5:尽量使用刚刚使用的block(还是“热乎的”),因为它们很可能还没有被替换,hit的概率会很大。我们在转换2的时候逆序转换:
同时在读取区域34的时候按列来读,这样的好处就是把2换到3的过程中是从下到上按行换的,因为这样可以先使用“最热乎”的block:
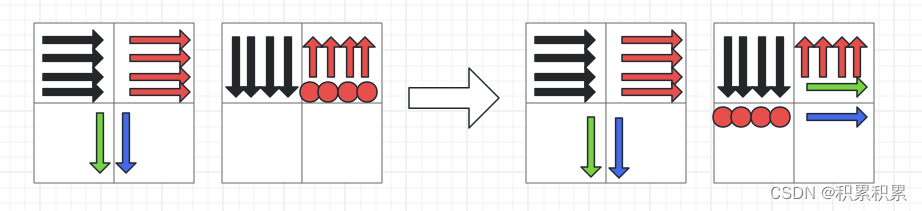















 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









