






 文章探讨了Kd-树在多维空间中的应用,特别是在高维环键向量中的搜索加速。通过构建KDTree并进行耗时测试,展示了其在最临近搜索中的效率。同时介绍了如何使用ICP和Gaussian-Newton法进行位姿初始化,强调了初始位姿估计的精度对算法性能的影响。
文章探讨了Kd-树在多维空间中的应用,特别是在高维环键向量中的搜索加速。通过构建KDTree并进行耗时测试,展示了其在最临近搜索中的效率。同时介绍了如何使用ICP和Gaussian-Newton法进行位姿初始化,强调了初始位姿估计的精度对算法性能的影响。
我上周做了kdtree加速搜素的耗时实验。添加到了第三章的部分。
然后就是把论文第三章的大体内容写了,
同时使用了icp初始化
Kd-树实现快速最临近搜索的原理。
Kd-树是K-dimension tree的缩写,他是对数据点在k维空间(如二维(x,y),三维(x,y,z),k维(x,y,z,…) )中划分的一种数据结构,把整个空间划分为特定的几个部分,主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。本质上说,Kd-树就是一种平衡二叉树与空间划分树。
KDtree 数据结构对空间的划分是通过垂直于对应轴的超平面将所有元素分在两侧,然后按照垂直方向选取轴点再做超平面,将上述半平面的点再做细分,重复以上述操作,不停迭代,将所有点位置信息存储在 KDTree 中。以三维空间为例,为了保证点云分割结果均匀,把跨度最大的方向上作为起始分割维度,然后选取该维度中间点作为下一个分割维度的轴点,继续做二分。三维空间可以按照 x,y,z 轴顺序做分割,直到分割区域只有一个点,此三维空间点作为叶节点。如图所示,空间划分平面的颜色依次为,红色,绿色,蓝色。
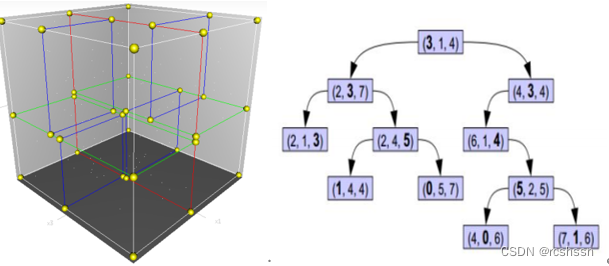
最后确定最近邻点,计算最近邻点的依据是点之间欧式距离或其他计算公式,通过KDTree 可以逐步缩小寻找范围。首先比较待查询节点和搜索点云KDTree 划分维度方向值大小,查询节点小于轴点进入左子树,否则进入右子树,直到 最后一层,就可以得到最近邻近似点,然后沿着搜索路径计算各个节点和查询点的距离,最小距离的点就是最近邻点。
具体应用于高纬度的ringkey向量。
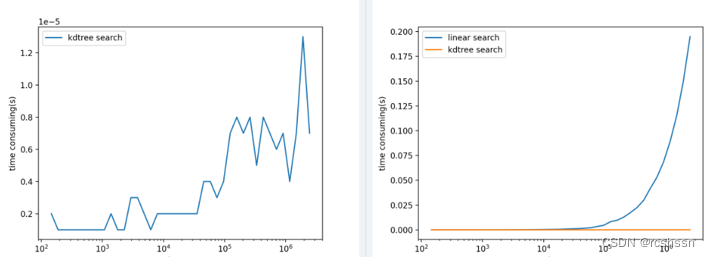
这一部分进行构造kdtree搜索与直接线性搜索的耗时测试,Ringkey为一个
维向量,此处取特征矩阵行数 为20(与scancontext论文中保持一致)。通过超平面划分20维空间,将数据集中全部点云数据对应的ringkey存储为KDtree 数据结构。在进行最临近搜索时,
之间的距离

使用Python的scikit-learn库来实现KD树,将最临近搜索的候选集数据量从小到大进行耗时测试,实验结果如下:
位姿初始化方法设计



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









