






 这篇博客介绍了一种通过HTML和Python自动化创建漫画阅读网页的方法。通过批量生成HTML代码,结合漫画文件名的规律(000~999),可以方便地用鼠标滚轮浏览漫画,并通过CTRL+F快速跳转页面。Python脚本根据设定的文件路径、文件类型、输出HTML文件名以及起始和结束页码,自动生成对应的HTML代码,极大地提高了漫画阅读的便利性。
这篇博客介绍了一种通过HTML和Python自动化创建漫画阅读网页的方法。通过批量生成HTML代码,结合漫画文件名的规律(000~999),可以方便地用鼠标滚轮浏览漫画,并通过CTRL+F快速跳转页面。Python脚本根据设定的文件路径、文件类型、输出HTML文件名以及起始和结束页码,自动生成对应的HTML代码,极大地提高了漫画阅读的便利性。
一般从nyaa等网站下载得到的漫画、轻小说等资源都是像这样图片的格式,而是用系统自带的图片浏览器观看时,翻页、缩放等都非常麻烦,效果并不好。
但是可以看出,一般文件名都比较规律,从000~999这样。
其实看漫画最好的方式,漫画网站已经给我们答案了,就是在浏览器上用鼠标滚轮往下翻(bilibili漫画),下面提供一种使用HTML、Python实现的思路。

HTML代码
<html>
<style>
div {
margin: auto;
width: 900px;
}
img {
width: 95%;
}
</style>
<body>
<div>
<img src="./manga 01/00001.jpeg">001
<img src="./manga 01/00002.jpeg">002
<img src="./manga 01/00003.jpeg">003
</body>
</html>
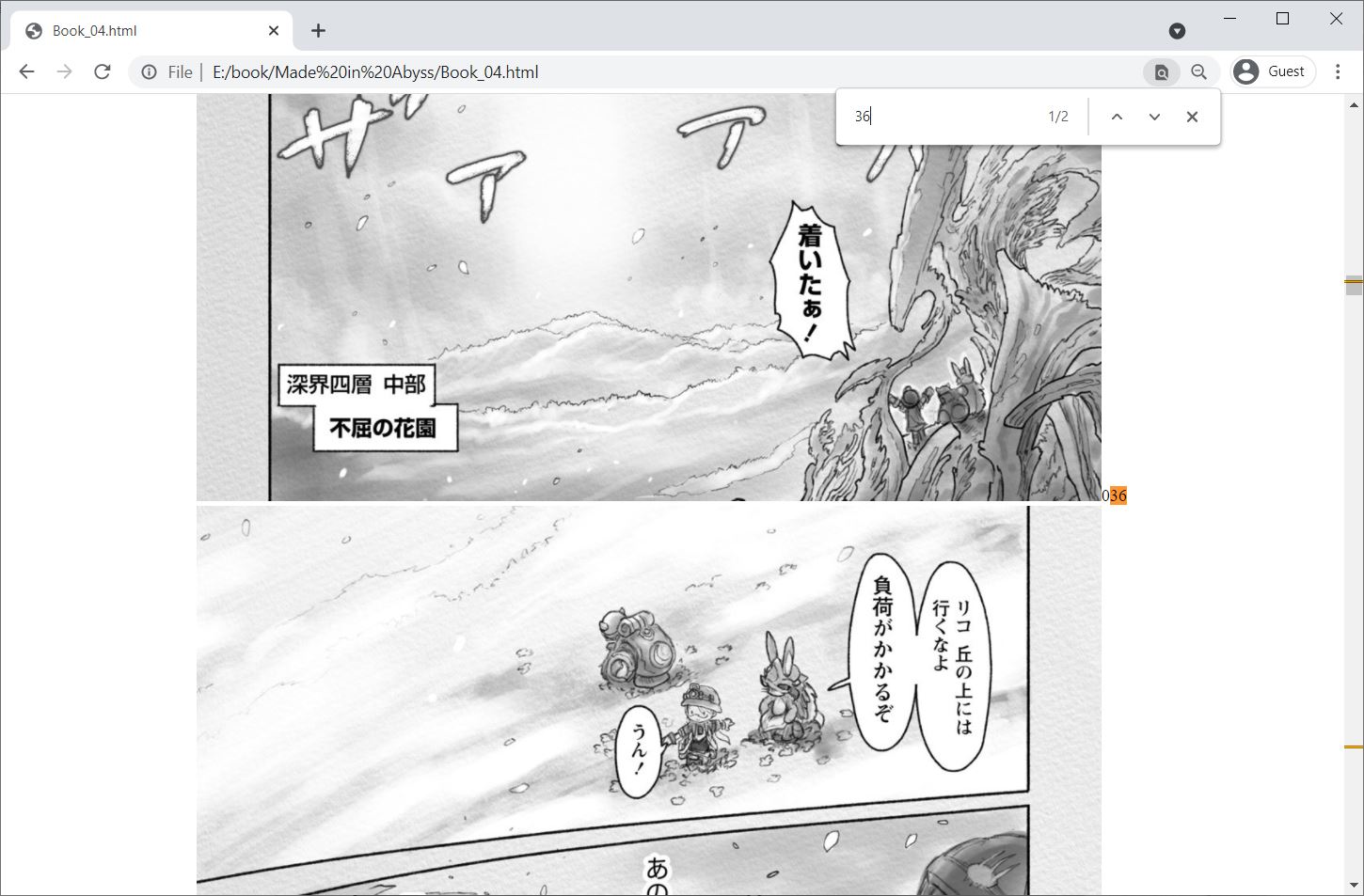
效果如图。可以一滚到底。

在图片旁边加上数字,一来可以查看页码,最重要的是可以用CTRL+F来搜索页面来实现快速跳转。
Python实现
接下来的问题就是如何批量生成HTML代码。毕竟一部漫画得有几百页,不能用手输。
# src, file_type, output, strat, finish
data = [
["./Made in Abyss v01/", ".jpg", "Book_01.html", 1, 169],
["./Made in Abyss v02/", ".jpg", "Book_02.html", 0, 165],
["./Made in Abyss v03/", ".jpg", "Book_03.html", 0, 164],
]
for d in data:
src = d[0]
file_type = d[1]
output = d[2]
strat = d[3]
finish = d[4]
with open(output, 'w', encoding='utf-8') as f:
f.write("<html><style>div {margin: auto;width: 900px;}img{width: 95%;}</style><body><div>")
for i in range(strat, finish):
f.write("<img src=\"" + src)
f.write("%03d" % i)
f.write(file_type + "\">")
f.write("%03d" % i)
f.write("</div></body></html>")
data 数组中分别存有文件名前半、文件名后半(图片类型)、生成HTML的文件名、开始页码、结束页码。
比如 "./manga 01/00002.jpeg"这个路径,可以分为 "./manga 01/00" 和 "%03d" % 2 和 ".jpeg" 三部分。
注意这里文件一定要用 encoding='utf-8' 模式打开,不然遇到汉字就会报错。
运行后便可批量生成,不用手动输入了。

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









