






本文首次发布于今日头条和微信公众号。 头条账号: yuanyeex; 微信公众号: 元本一兀
Apache Calcite的前身是optiq,是Hive中做CBO(Cost Based Optimization, 基于成本的优化)的一个模块。2014年5月从Hive项目中独立出来,成为Apache社区的孵化项目,同年9月正式改名为Apache Calcite。Calcite的作者是Julian Hyde,是数据处理与架构方面的专家,在数据平台方面的工作经历非常多,曾是Oracle、Broadbase公司SQL引擎的主要开发者、SQL Streaming公司的创始人和架构师、Pentaho BI套件中OLAP部分的架构师和主要开发者。
Apache Calcite是目前很火的一个Apache开源项目,其定位是动态数据管理框架。和传统的DBMS系统比,Apache Calcite舍弃传统数据库系统的几个关键特性,数据存储(storage of data)、数据处理算法(algorithm to process data)、元数据仓储(repository for storing metadata)。可以看到,Apache Calcite本身不涉及任何物理存储信息,也不做具体的物理数据操作,而是专注在SQL解析、基于关系代数的查询优化,通过扩展的方式来对接底层存储。
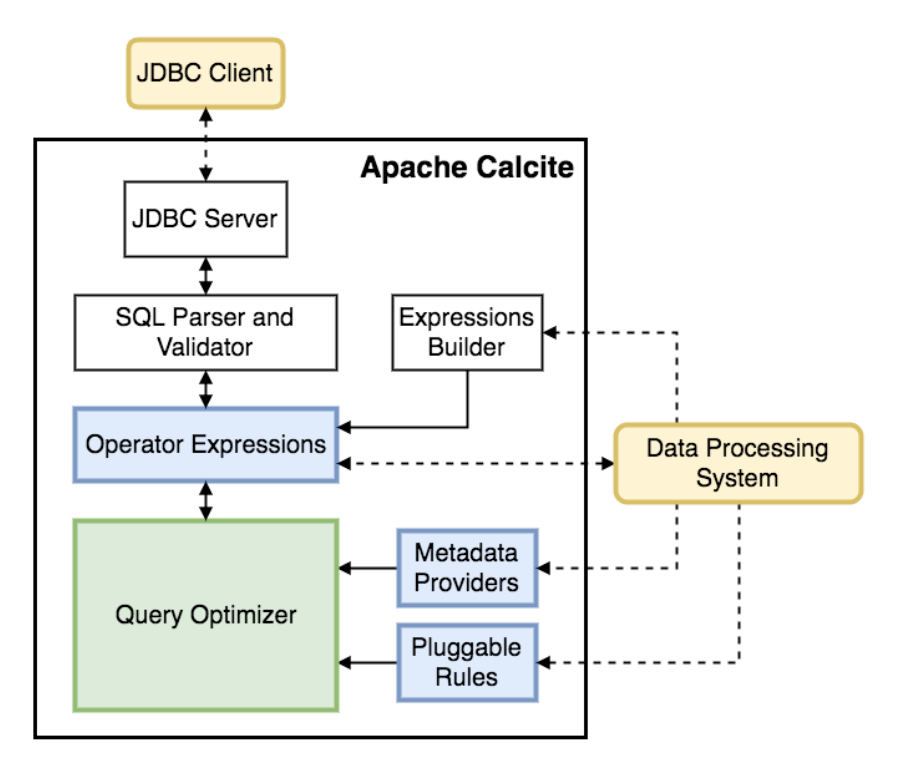
因此,Apache Calcite可以更好的被其他项目集成, 能够在异构存储、异构引擎上,提供统一的数据管理能力,同时还支持基于关系代数的优化器。正如Apache Calcite的设计目标”One planner fits all” 说的那样,我们只需要一个SQL接口,就能支持任何数据存储、计算引擎。目前,Apache Caclcite被广泛应用于众多的开源项目中,如Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza 和 Apache Flink等。
Apache Calcite的能力
Apache Calcite有几个特性:
- 可扩展:适配不同的存储、计算引擎
- 查询优化:基于关系代数,提供强大的优化器
- 支持物化视图
- 支持OLAP
- 支持流式查询
强大的扩展性
刚才提到,Apache Calcite本身不提供物理存储(报错数据、元信息,以及数据的处理算法),这些减法,但是它提供了一个扩展机制(schema adapter),能够定义外部物理引擎中的table、view等信息。
Apache Calcite官网列出了大量adapter:
- Cassandra adapter (calcite-cassandra)
- CSV adapter (example/csv)
- Druid adapter (calcite-druid)
- Elasticsearch adapter (calcite-elasticsearch)
- File adapter (calcite-file)
- Geode adapter (calcite-geode)
- InnoDB adapter (calcite-innodb)
- JDBC adapter (part of calcite-core)
- MongoDB adapter (calcite-mongodb)
- OS adapter (calcite-os)
- Pig adapter (calcite-pig)
- Redis adapter (calcite-redis)
- Solr cloud adapter (solr-sql)
- Spark adapter (calcite-spark)
- Splunk adapter (calcite-splunk)
- Eclipse Memory Analyzer (MAT) adapter (mat-calcite-plugin)
- Apache Kafka adapter
Apache Calcite提供了强大的Sql Parser,支持标准SQL,并支持扩展。另外,由于Calcite的底层优化器是基于关系代数的,前端语言可以是SQL也可以是其他语言,比如Pig等,只需要通过Calcite的接口解析成抽象语法树即可。目前有很多项目基于Apache Calcite做SQL解析、查询优化、数据虚拟化/数据联邦、SQL重启等。

查询优化
查询优化是Apache Calcite框架中的主要模块之一。首先,什么是查询优化呢?对任意一个查询,我们可以通过不同的算法对查询进行重写,得到一个语义等价的查询。那么查询优化就是在所有语义等价的查询中,找到最优的查询,并完成重写。
以下面的查询为例:
SELECT * FROM fact
WHERE event_date BEWEEN ? AND ?
最粗暴的方式,就是全表扫描,然后做过滤。当然,我们可以利用属性event_date的索引,把扫全表再过滤,变成成一个索引查询。很明显,第二个查询效率要高很多。
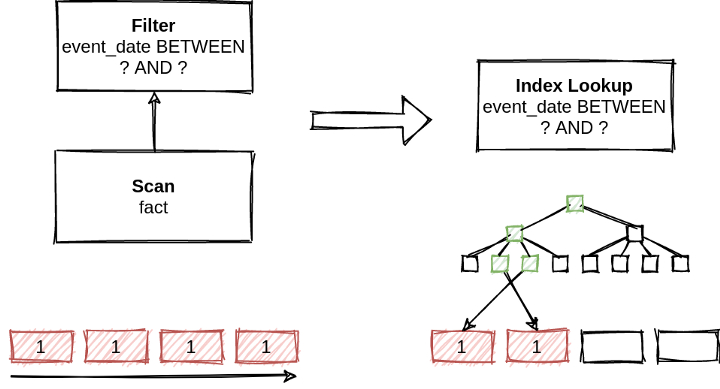
刚才提到,查询优化就是在所有语义等价的查询中,找到最优的查询。判断一个查询的优劣,本质就是在保证记过正确的前提下,降低成本。
优化这部分,后面单独写一篇文章来展开讨论,这里先不展开讨论。
物化视图
在大规模数据查询中,物化视图是加速查询的核武器。
很多Calcite Adapters和基于Calcite的项目都支持物化视图。例如:Cassadra就允许用户在现有表的基础上定义物化视图。通过将物化视图注册到Calcite中,Calcite优化器能够对原有查询进行重写,把对原表的查询改写成对物化视图的查询。
举一个经典的物化视图实现查询加速的例子,它按部门、性别统计出相应的员工数量和工资总额:
CREATE MATERIALIZED VIEW emp_summary AS
SELECT deptno, gender, COUNT(*) AS c, SUM(salary) AS s
FROM emp
GROUP BY deptno, gender;
物化视图本质上也是数据表,所以你可以直接查询它,比如查询男员工人数大于 20 的部门:
SELECT deptno FROM emp_summary
WHERE gender = ‘M’ AND c > 20;
更重要的是,优化器可以对查询改写,将对原表的查询,改写成对物化视图的查询。由于物化视图数据量比原表少,一般存在缓存或内存中,处理的数据更接近结果,所以查询速度会大大加快。
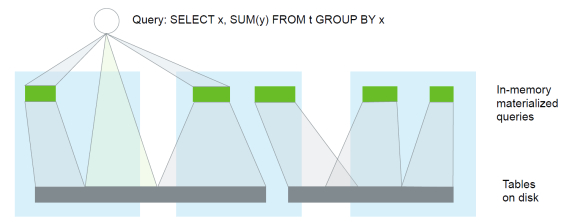
比如下面这个对员工表(emp)的查询(女性的平均工资):
SELECT deptno, AVG(salary) AS average_sal
FROM emp WHERE gender = 'F'
GROUP BY deptno;
通过Calcite优化器,SQL被改写成查询物化视图(emp_summary):
SELECT deptno, s / c AS average_sal
FROM emp_summary WHERE gender = 'F'
GROUP BY deptno;
我们可以看到,多数值的平均运算,即先累加再除法转化成了单个除法。
快速Demo
这里给一个Demo,让大家熟悉下Calcite的使用方式。一般来说,在Calcite中SQL的执行分为下面几步:
- SQL解析
- 语法校验
- 语义分析
- 优化
- 执行
Apache Calcite涵盖了前面4步,而第5步需要提交到目标物理引擎上执行。
以这个SQL作为原始SQL:
select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age
from users u join jobs j on u.name = j.name
where u.age > 30 and j.id > 10
order by user_id
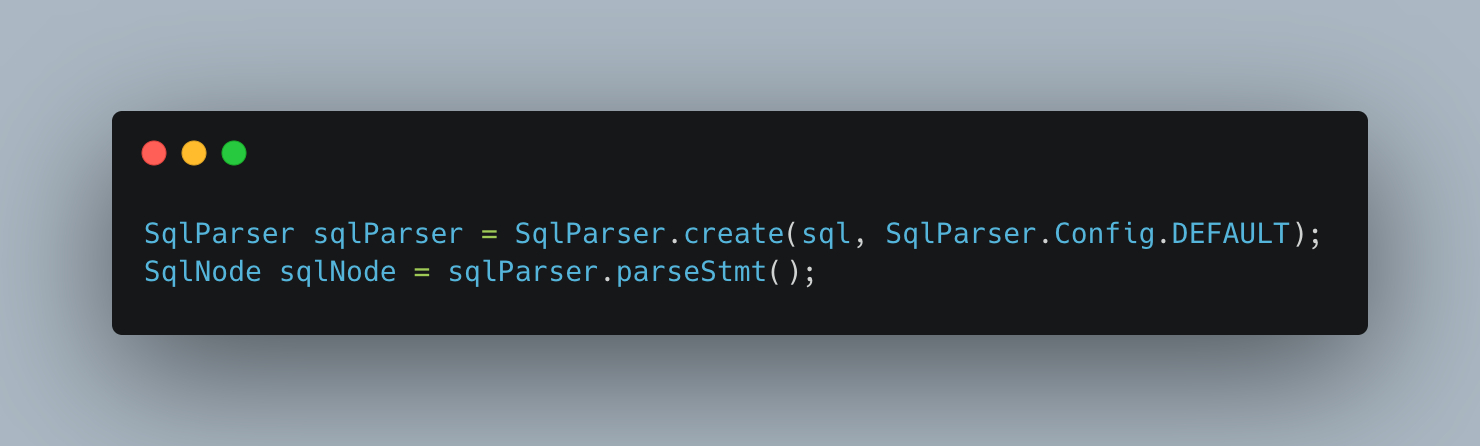
使用Calcite做SQL解析
SQL解析阶段,Calcite对SQL做词法分析,并转换成抽象语法树(AST),在Calcite中使用SqlNode来表示:
语法校验
因为Calcite没有物理存储的元信息,需要注册,这里通过下面的代码,简单注册了两张表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p4RpVIWn-1665321152100)(https://tvax4.sinaimg.cn/large/b33b5450ly1h6up3j1qf8j21kw13c4np.jpg)]
有了元数据信息后,就可以做语法校验了,包括表、字段、函数存在性检查,函数入参出参类型校验,字段类型校验等:
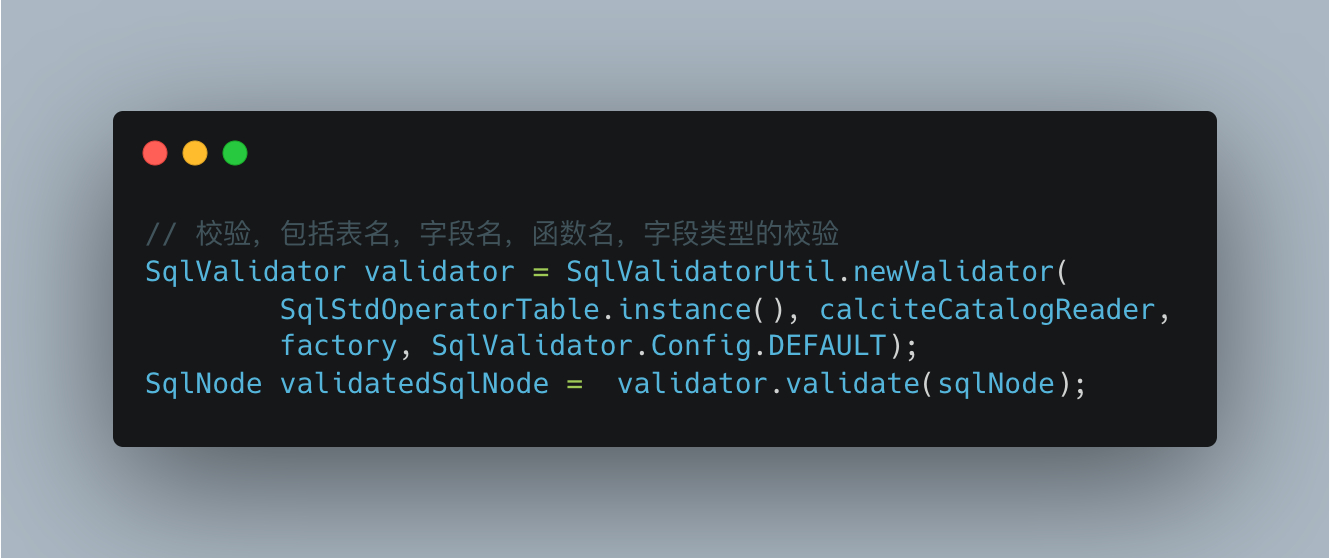
语义分析
语义分析阶段,Calcite会将AST转换成关系表达式,即RelNode,可以理解成最开始的逻辑执行计划:
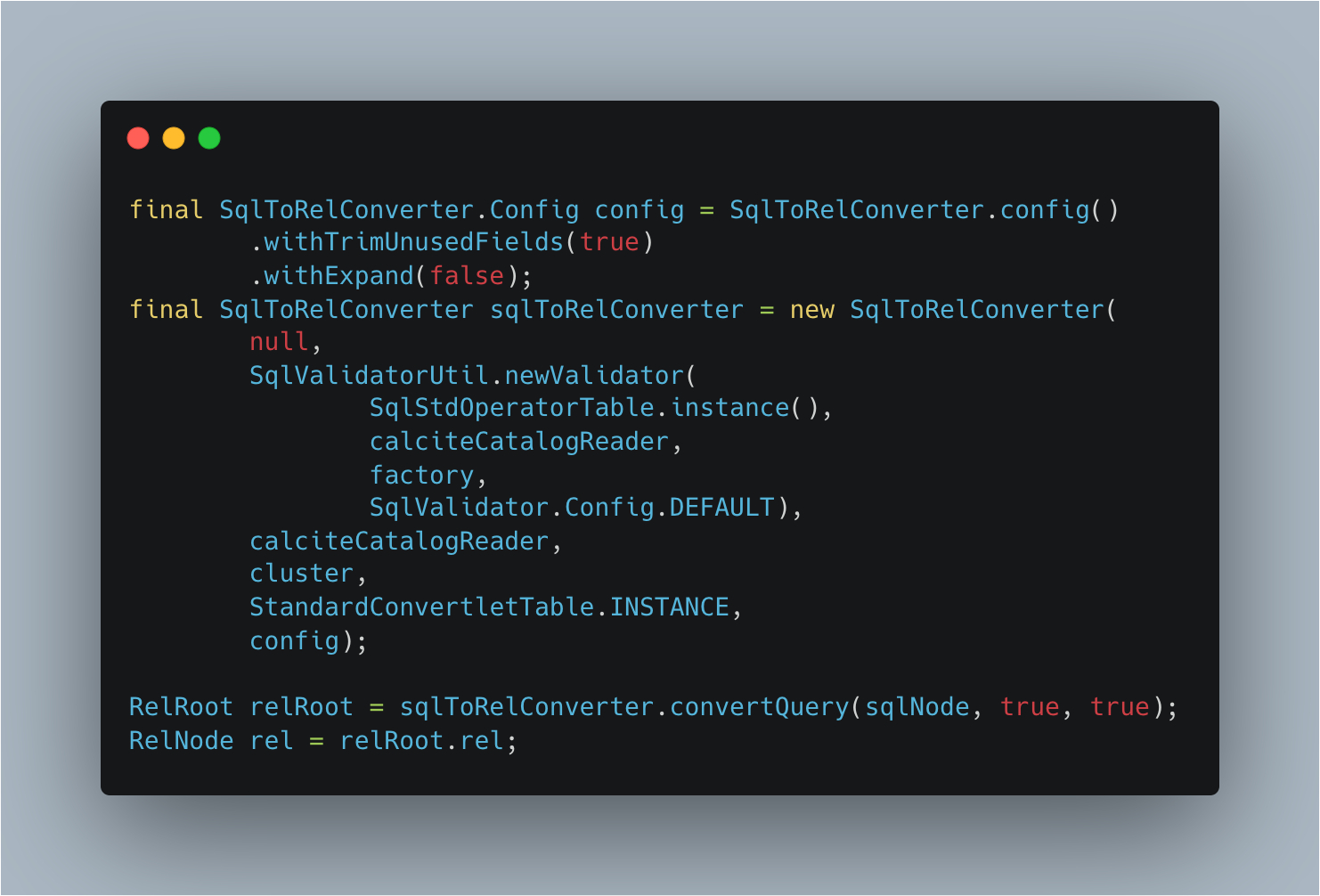
打印出分析后的逻辑执行计划:
LogicalSort(sort0=[$0], dir0=[ASC])
LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])
LogicalFilter(condition=[AND(>($2, 30), >($3, 10))])
LogicalJoin(condition=[=($1, $4)], joinType=[inner])
LogicalTableScan(table=[[USERS]])
LogicalTableScan(table=[[JOBS]])
优化
对语义分析生成的逻辑执行计划进行优化:
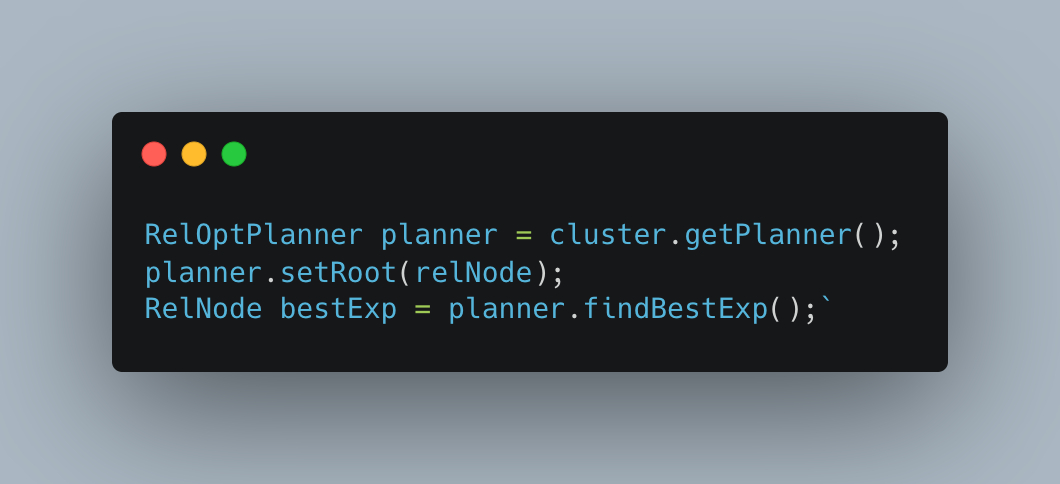
输出优化后的逻辑执行计划:
LogicalSort(sort0=[$0], dir0=[ASC])
LogicalProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])
LogicalJoin(condition=[=($1, $4)], joinType=[inner])
LogicalFilter(condition=[>($2, 30)])
LogicalTableScan(table=[[USERS]])
LogicalFilter(condition=[>($0, 10)])
LogicalTableScan(table=[[JOBS]])
可以发现,原来的执行计划是先join后过滤,而优化后,过滤条件被下推到了TableScan之后。
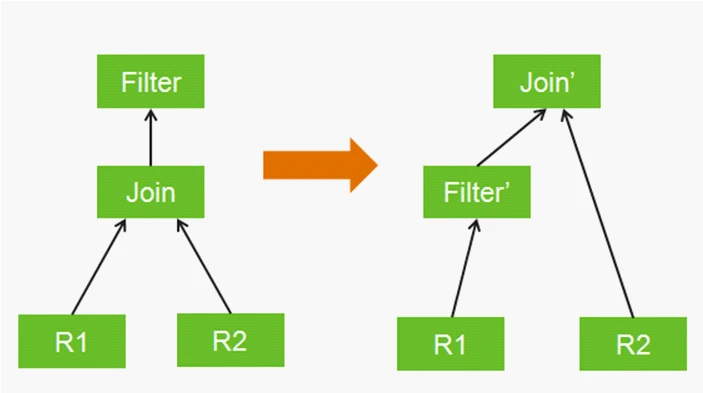
总结
Apache Calcite是十分强大的开源动态数据管理系统,舍弃传统数据库系统的数据存储、元数据仓储、数据处理算法,专注于对异构存、算引擎提供SQL解析、优化,瞄准了海量数据背景下,单数据引擎(one size fits all)无法满足需求,异构存储、异构计算成为趋势,提供了“one plan fits all”的解决方案。目前有很多开源项目在使用,国内外大厂也都在使用。
后续会推出更多文章,深入理解Calcite的原理,以及在目前主流的项目中,Calcite的定位和解决的问题。
文中Demo代码地址: https://gist.github.com/yuanyeex/c127c20d02c082646556847e74b4cc60
扫一扫关注我
















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











