





3. NUMA互联的价值
NUMA互联在节约成本,资源利用率,系统管理和程序员的工作效率方面有着无可比拟的优势。
根据长期使用大共享内存系统(SMPS)和集群的用户的体验,由于系统资源的灵活性,SMP系统具有更高的资源利用率。他们表明,在执行各种各样的工作中,大型主机可以很容易地保持在90%以上的利用率,而集群的利用率很少能达到60-70%以上。
对于系统的管理,NUMA芯片能够明显的减少操作系统的数量。在100Tflops计算能力的系统中,系统的的数量可以从约1 400减少至40个,减少了约35倍。即使40个 操作系统映像需要稍多的资源来管理,但比起1 400个操作系统的管理而言,其整体的节省是显著的。
集群中的并行处理,需要进行明确的消息传递编程,而共享内存系统可以利用专门为多核处理器而开发的编译器和其他工具。并行编程是一项复杂的任务,为消息传递编写的程序通常比共享内存的程序多50%-100%的代码。由于所有的程序都包含错误,因此,消息传递程序中的错误概率也比共享内存方案的多50%-100%。调试错误的时间占用了大量的软件开发的时间,进而,完成应用开发的时间就会增加。
原则上,服务器是多任务,多用户的机器,完全有能力在任何给定时间内运行多个应用程序。小型服务器具有很高的性价比,因为他们具有很高的量产,其组件可以使用许多与桌面电脑相同的组件。目前,一个CPU的价钱少于2000美金。然而,这些小型,中型的服务器是不能扩展的。最广泛的配置是2个CPU插座,每个插座安装具有4至16个核的CPU。如果不改变主板,他们不能升级,同时他们的功耗很高,需要额外的机箱来容纳电源。反过来,这意味着,需要仔细的容量规划来优化成本,如果计算要求提高,它可能需要一个更大和更昂贵的的服务器来代替以前的产品,导致成本的增加是线性的。对于最昂贵的服务器,每个CPU的价格范围是50,000 - 60,000美元。
Numa芯片包含所有必要的逻辑使得基于量产服务器组件可以构建大规模系统。这使得每个CPU的成本降低,而功能与大型机服务器提供的相同。
Numa芯片呈现了一个引人注目的情况,以高端集群的成本获得大型机的能力,这在IT预算中,体现的价格差异是显而易见的。昂贵的大型机还包括一些功能用来动态系统重构,Numa芯片系统在初始不会提供。这样的功能依赖于操作系统软件,并可以在基于Numa芯片的系统中实现。
4 技术
4.1 多核处理器和共享内存
针对多进程的共享内存编程提高了程序员的工作效率,因为它比消息传递方式更容易处理。共享内存方案所支持的编译工具,比其他方式需要更少的代码,从而缩短了开发时间和更少的程序错误。所有主要平台上的可用性,如多核的台式机和笔记本电脑,驱使更多的程序利用其增加的潜在性能。
从单一的处理器芯片的系统到超过1000个处理器芯片的系统,在相同的编程范式内,Numa芯片提供系统规模的无缝扩展。
其他的不提供CC-NUMA功能的互连技术,与Numa芯片能够有效运行任何程序相比,需要将消息传递写入应用程序中,导致程序的庞大,bug的增多和开发时间的增长。
4.2 虚拟化
在数据中心,对获得更高的资源利用率的强烈渴望,使得虚拟化的趋势越来越强。简单来说,它意味着任何应用程序应该能够运行在数据中心的任何服务器上;根据用户的加载,每个服务器动态结合更多的应用,使其被更好利用。
商业服务器技术在达到这一目标上,呈现出严重的局限性。一个主要的限制是,任何给定的应用程序对内存的需求,需要在任何给定的时间被物理服务器满足。反过来,这意味着,如果在数据中心的任何应用程序,要在不同的时间内在所有的服务器上被动态执行,那么,所有的服务器都必须被配置了最苛刻的应用程序所需的内存量,但实际上,只有运行这个应用的服务器才会使用这么大内存。而这是大型机的擅长,因为其有一个灵活的共享内存体系结构,在任何给定的时间,任何处理器可以使用的存储器中的任何部分,所以它们只需要一个实例被配置为能够处理最苛刻的应用。通过任何应用程序可以访问系统中的总体内存, Numa芯片提供了完全相同的功能。此外,通过操作系统提供的标准虚拟视图,所有应用程序能够访问系统中所有的I/ O设备。
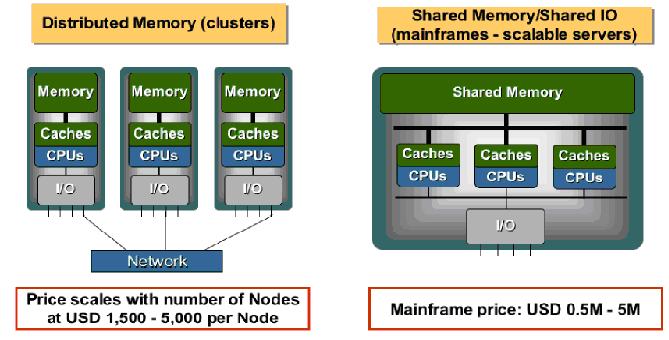
图1 集群架构 与大型机架构
图1是集群与大型机架构。在集群中,处理器通过网络,如以太网或infiniband耦合在一起。对于需要利用更多处理器或IO的应用,从一开始就必须被编程来实现。在大型机中,任何的应用可以使用系统中的任何资源作为虚拟资源,编译器能够产生运行在任何处理器上的线程。
在使用Numa芯片互联的系统中,所有的处理器可以访问系统中所有的内存和IO资源,其访问方式与大型机一样。Numa芯片提供一个完全的共享内存和IO的虚拟环境,提供与大型机一样的能力,来利用编译器产生并行进程和线程。
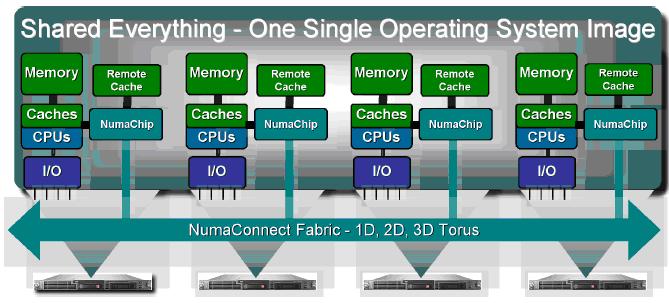
图2 NUMA互联系统架构
4.3 支持的操作系统
• Linux
• Windows Server
• Solaris
• Unix
Numascale公司提供了一个引导装载程序,上电后被激活,根据节点地址路由表执行系统初始化。
当标准的引导装载程序完成,系统将形成一个大的标准的共享内存系统。
4.4 连贯缓存的共享内存
NUMA互联与其他高速互联技术的最大不同是共享内存和缓存连贯机制。这些特性使程序可以高效访问多处理器系统中任何内存位置和任何内存映射的IO设备。并且提供了一个统一的编程模型来扩展系统,无论是小型的多核机器,还是大型机,其形式一模一样。
与集群相比,共享内存机器有许多的优点,
• 任何处理器通过直接加载和存储操作可以访问任何位置的数据,从而使编程更加容易,更少的代码和错误
• 编译器能自动利用循环级并行机制,从而更高效,更少的人力
• 作为一个标准的系统,而不是大量的独立系统映像来管理,从而便于管理
• 资源可以被系统中的任何处理器映射和使用,从而使虚拟环境中的资源更加优化的使用
• 通过单一的实时时钟同步的对进程调度,从而避免异步操作系统在集群调度的序列化和相应的效率损失。
在价格昂贵的大型机,IBM,Oracle(Sun),HP和SGI中,都具有这些特性。唯一美中不足的是,这些系统的价格,每个CPU核,比商用服务器高达30倍。在低端市场,英特尔和AMD的多处理器机器,其商品价格水平是非常受欢迎的。
4.5 可扩展性和鲁棒性
64位物理地址处理器设计的最初目的是,16为作为节点ID,48位作为节点内地址。对于皓龙处理器,目前的应用是48位的全局物理地址空间,12位用来定位4096个物理节点,总共的物理地址是256TB。
基于连续缓存协议的目录用来处理大规模的节点的数据共享,避免互联内节点的超载,因为这将会导致实时数据吞吐量的严重下降。
分布式交换的基本环形拓扑结构,允许一些不同的互连配置,比其他的互联架构具有更好的扩展性。这也减少了一个中心交换机的需要和包括固有的冗余的多维结构。
随着大量的节点增多,管理功能的鲁棒性,尤其是对数据完整性的高要求,在实时传输和管理上显得越发重要。
4.6 集成的分布式交换
在基于Numa芯片系统中,Numa芯片具有一个片上交换机用来与其他节点互联,这样就减少了对一个中心交换机的需要。片上交换机可以将系统连接成1,2或3维的互联方式。小系统可以使用一维,中型系统可以使用二维,大系统可以使用三维互联来提供有效的,可扩展的处理器间的互联。
与基于中心交换机的系统相比,二维和三维拓扑还具有内置冗余的优点,因为交换机是系统中的一个点,和其他节点一样,具有坏掉的可能性。
分布式交换架构降低了系统成本,因为没有多余的交换机成本。随着交换机的减少,相应的空间,散热,电源消耗需求都会降低。
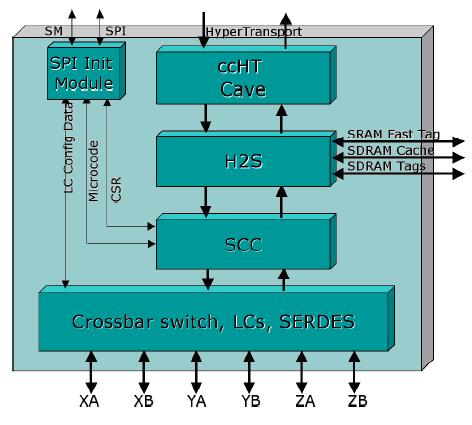
图3 NumaChip框图
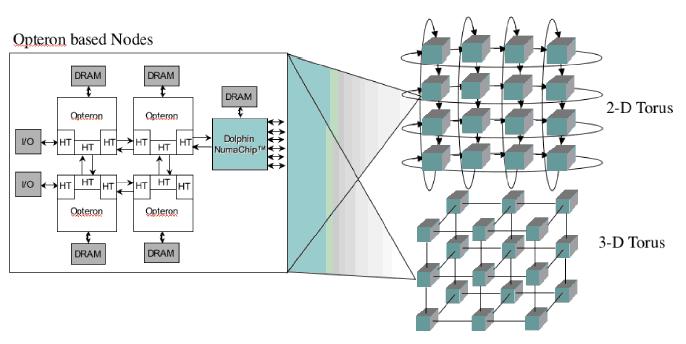
图4 系统拓扑结构
更多联系可参考公司网站www 。hxsolution 。com















 3802
3802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









