







 该篇博客介绍了如何用Python为小班幼儿设计一套6*6的连连看练习,旨在减少图案间的交叉,提高辨识度。通过随机抽取和排列图案,创建了适合小班的题量,并将图案填充到Word表格中,最后将Word转换为PDF并合并成打印合集。此外,还讨论了在练习中引入个人信息以培养幼儿的物权意识。
该篇博客介绍了如何用Python为小班幼儿设计一套6*6的连连看练习,旨在减少图案间的交叉,提高辨识度。通过随机抽取和排列图案,创建了适合小班的题量,并将图案填充到Word表格中,最后将Word转换为PDF并合并成打印合集。此外,还讨论了在练习中引入个人信息以培养幼儿的物权意识。
效果展示
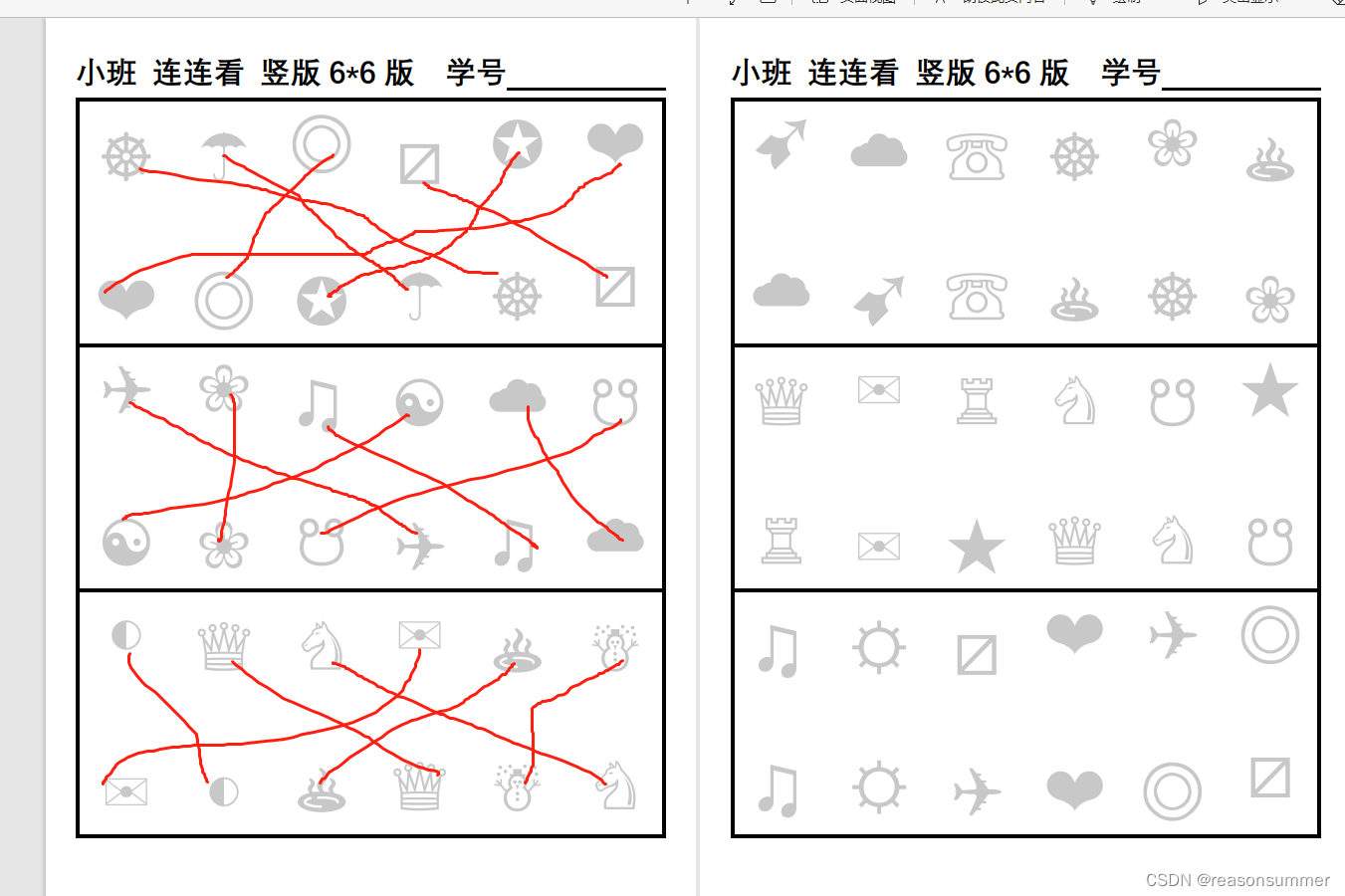
背景需求:
前期对A4横板的”练练看“进行了8*4、8*2的设置,感觉有时候线条之间也会有交叉,容易看不清。
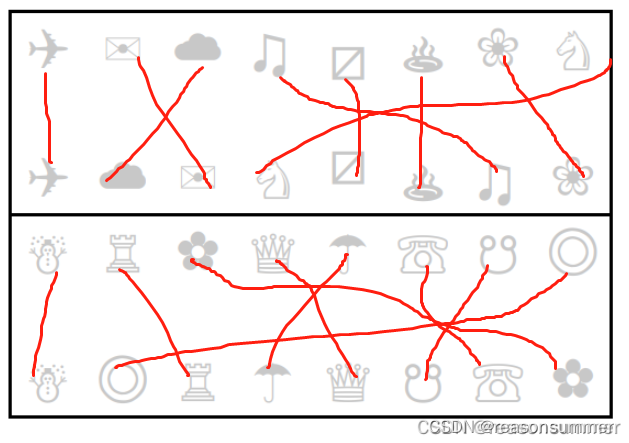
适用性思考——小班( 纵向排版)
1、如果图案少一点,交叉的情况会减少。更容易辨认连线的正确性。但图案少了,幼儿操作太快也是个问题。
2.我觉得可以为"小班”做一套适合的“连连看“(每套题目图形少一点、但题量多一点)1.
思路:

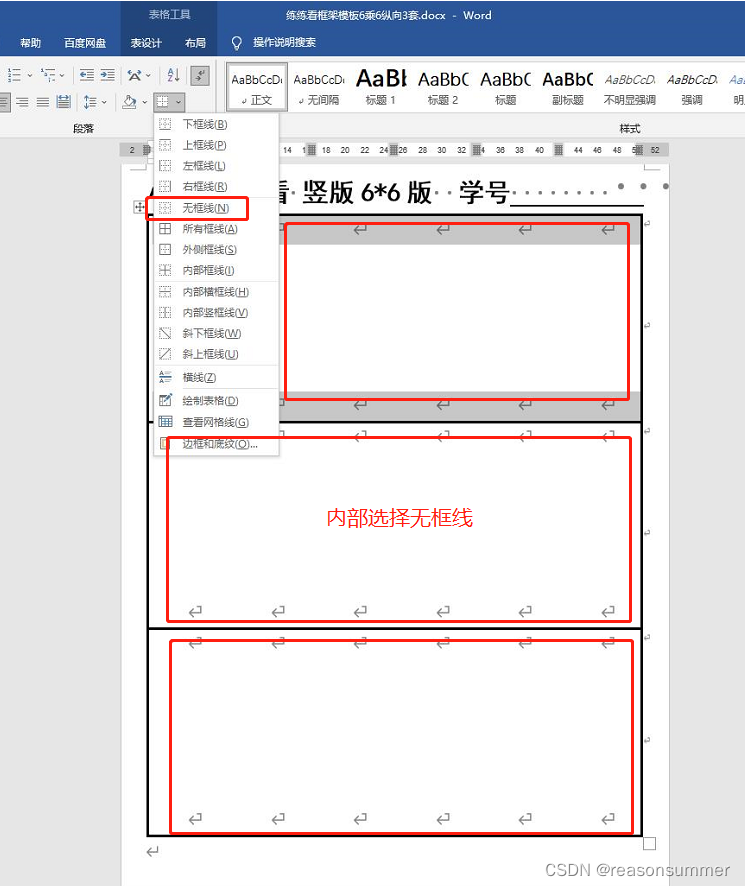
WORD表格制作(在纵向A4)
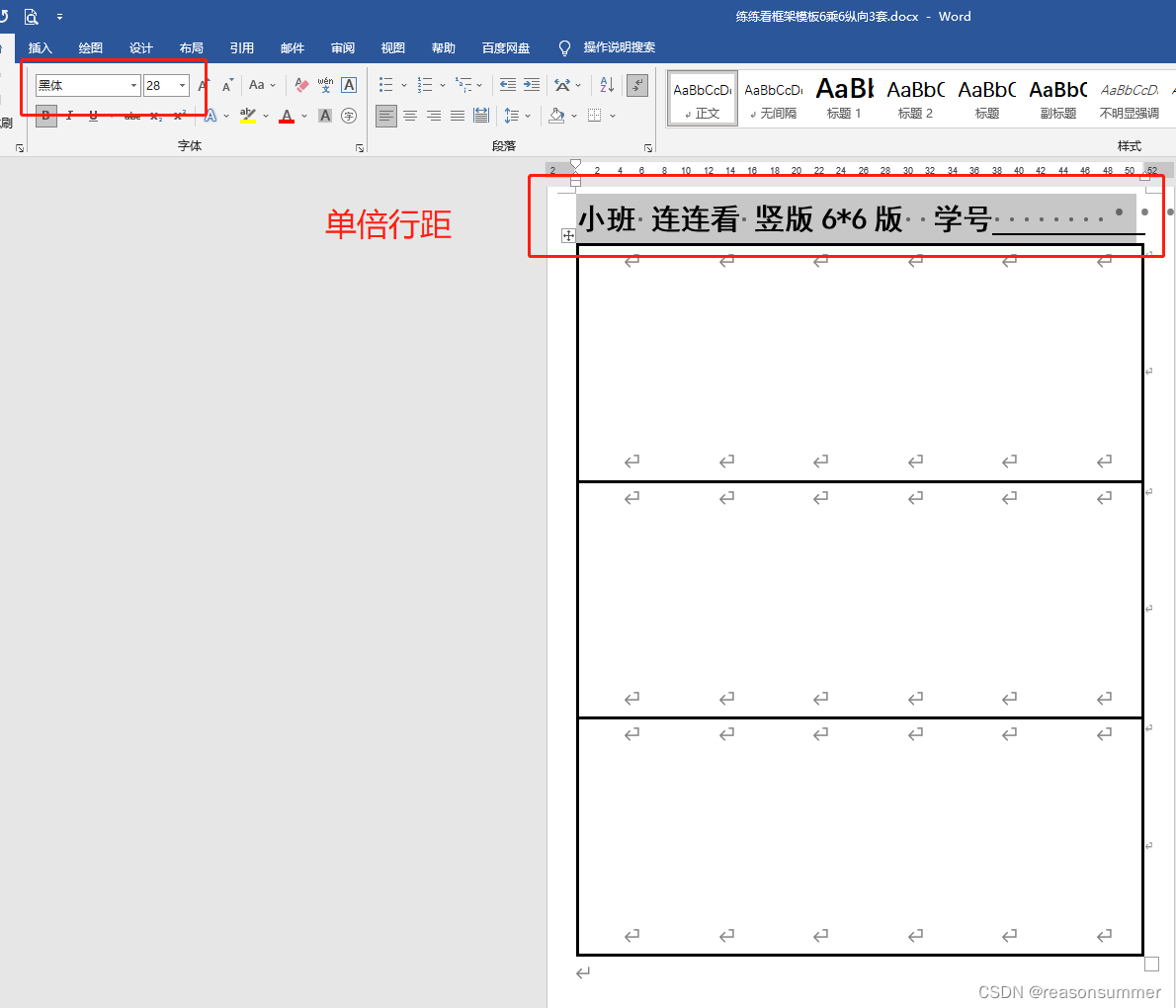 每个6*6每个单元格的高度宽度
每个6*6每个单元格的高度宽度 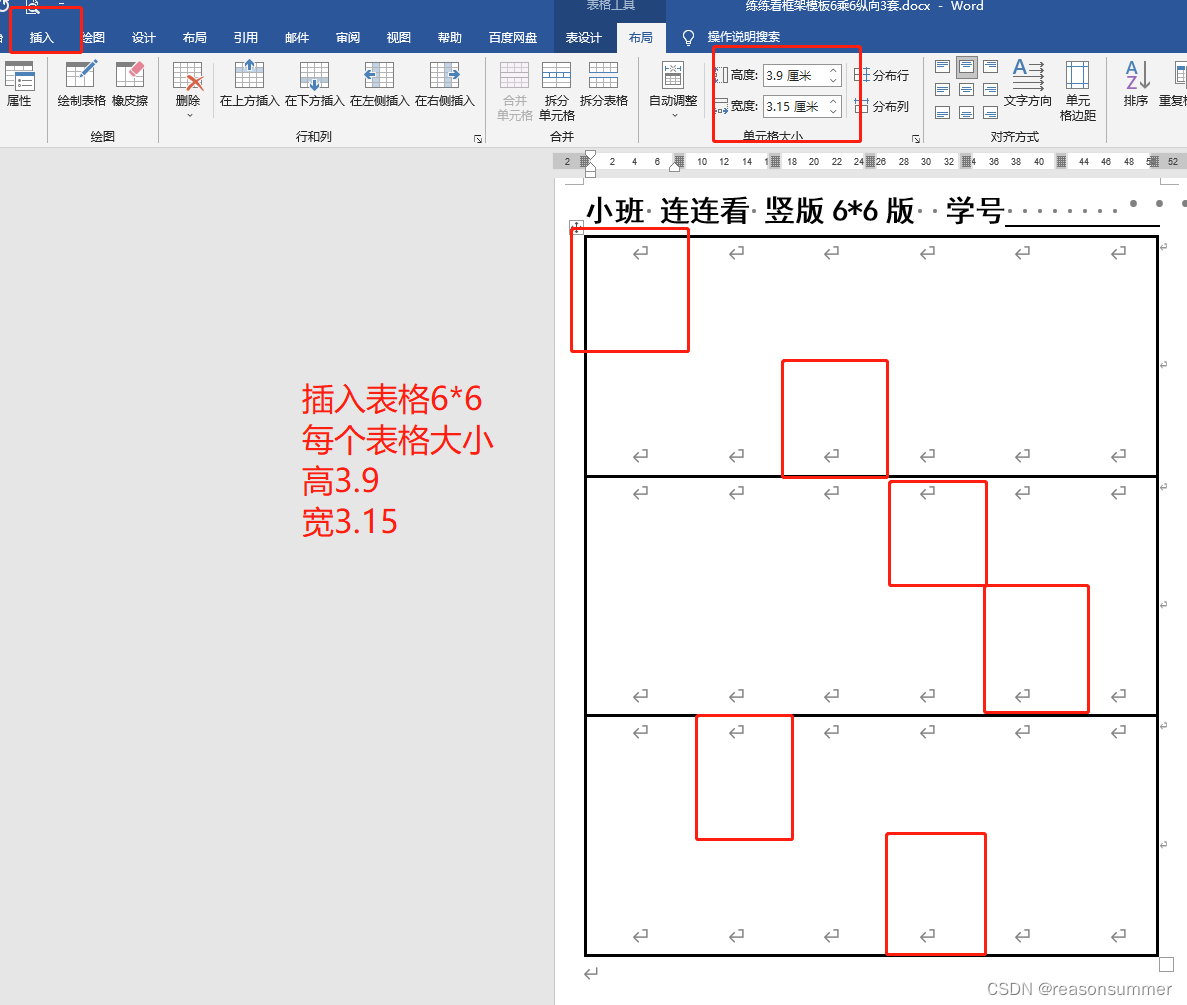
代码设计:
'''
作者:阿夏
时间:2022年11月7日连连看(A4竖板)6*6,3套题)
(A4竖排6*6小班 ))
'''
import os
num=int(input('生成多少份\n'))
Number=int(input('每页制作多少个(18个)\n'))
size=int(input('图案大小(6*6 建议60)\n'))
length=int(input('表格长度(6格)\n'))
weight=int(input('表格宽度(6格)\n'))
print('----------第1步:提取所有图案------------')
list=['✿','☸','✪','☁','➹','✈','☂','☃','◐','☼','☯','◎','❤','♨','☋','♘','★','♫','❀','〼','✉','☏','♕','♖']
print(len(list))# 一共24个图案
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\零时Word')
print('----------第3步:随机抽取8个不重复的图案 ------------')
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for z in range(0,num): #多少份
# word = gencache.EnsureDispatch('Word.Application')
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\练练看框架模板6乘6纵向3套.docx')
table = doc.tables[0]
# 先随机抽取8个一列
all=[]
n1=[]
n2=[]
n3=[]
n4=[]
n5=[]
n6=[]
n = random.sample(list, Number) # 24个里面随机抽取16个放入一个组nn
# print(n)
# 第1行:
for n1 in n[0:int(Number/3)]: # 16个里面的1-8个,提取单独数
n2.append(n1)
all.append(n1) # 第1轮8个添入总列表 (插入Word第1行)
# 第2行:
o1 = random.sample(n2, int(Number/3)) # 第1轮8个再随机打乱一次,不重复抽取
for b in o1:
all.append(b)#第1轮8个乱序排列不重复(插入Word第2行)
# print(all)
# 第3行:
for n3 in n[int(Number/3):int(Number/3*2)]: #16个里面的9-16个,提取单独数
n4.append(n3)
all.append(n3) # 做第4列的乱序用
# 第4行:
o2 = random.sample(n4, int(Number/3)) # 第2轮8个再随机打乱一次,不重复抽取
for bb in o2:
all.append(bb)#第2轮8个乱序排列不重复(插入Word第4列)
# print(all)
# 第5行:
for n5 in n[int(Number/3*2):int(Number)]: # 16个里面的1-8个,提取单独数
n6.append(n5)
all.append(n5) # 第1轮8个添入总列表 (插入Word第1行)
# 第6行:
o3 = random.sample(n6, int(Number/3)) # 第1轮8个再随机打乱一次,不重复抽取
for bbb in o3:
all.append(bbb)#第1轮8个乱序排列不重复(插入Word第2行)
print(all)
# ['☃', '〼', '❤', '♕', '♫', '✈', '✿', '☸', '♫', '❤', '〼', '✈', '☃', '✿', '♕', '☸', '✪', '☁', '✉', '◎', '♖', '☼', '★', '☋', '♖', '☁', '☼', '☋', '✉', '◎', '✪', '★']
# 确定8*4表格的表格单元格坐标(如第1行第1格是0,0 ,第2行第3格是(1,2)
bg=[]
for x in range(0,weight):
for y in range(0,length):
ww='{}{}'.format(x,y)
bg.append(ww)
print(bg)
# ['00', '01', '02', '03', '04', '05', '06', '07', '10', '11', '12', '13', '14', '15', '16', '17', '20', '21', '22', '23', '24', '25', '26', '27', '30', '31', '32', '33', '34', '35', '36', '37']
# 提取表格单元格坐标和图形的坐标
for t in range(0,len(all)): # 图案的长度为8*4=32个 遍历0-32(32个)
pp=int(bg[t][0]) # 提取表格bg里面每个元素的第0个数字==单元格X坐标 t=索引数字
qq=int(bg[t][1]) # 提取表格bg里面每个元素的第1个数字==单元格Y坐标 t=索引数字
k=all[t] # 提取all图案列表里面每个图形 t=索引数字
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.size = Pt(size) #输入字体大小默认30号
run.font.color.rgb = RGBColor(200,200,200) #设置颜色浅灰
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/连连看/(打印合集)连连看{}乘{}小班({}份).pdf".format(int(Number/3),int(Number/3),num))
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word') #递归删除文件夹,即:删除非空文件夹
重点说明:
终端运行

图案列表的数量(需要6个6个抽取3次,输入1、3、5行,把1、3、5的内容分别打乱,输入2,4,6行)

图案列表的生成Word表格单元格坐标(XY)的索引数的生成(只有两行)

如何将单个图案输入到指定的Word表格单元格内

效果再显示:

感悟:
1、竖版A4最大可容纳题量3套
6个图案的查找和连线较为适合小班幼儿操作。竖版A4最大可容纳题量6*6 :3套
2、幼儿练习写学号:
从小班开始就在每个Python批量A4学具上保留”个人信息“的位置,让幼儿逐步从”学号(小班)、转向“学号+一个姓名”(中班)、学号+全名(大班)的强化练习。书写学号、姓名,可以便于确定物权归属。提高课堂教学效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











