







作品展示
背景需求:
前文将信息窗+主题知识的内容提取并优化结构
后续就是将19份WORD
1、word做成图片png——图片上传网页
2、word合并PDF——批量打印A4纸
设计过程
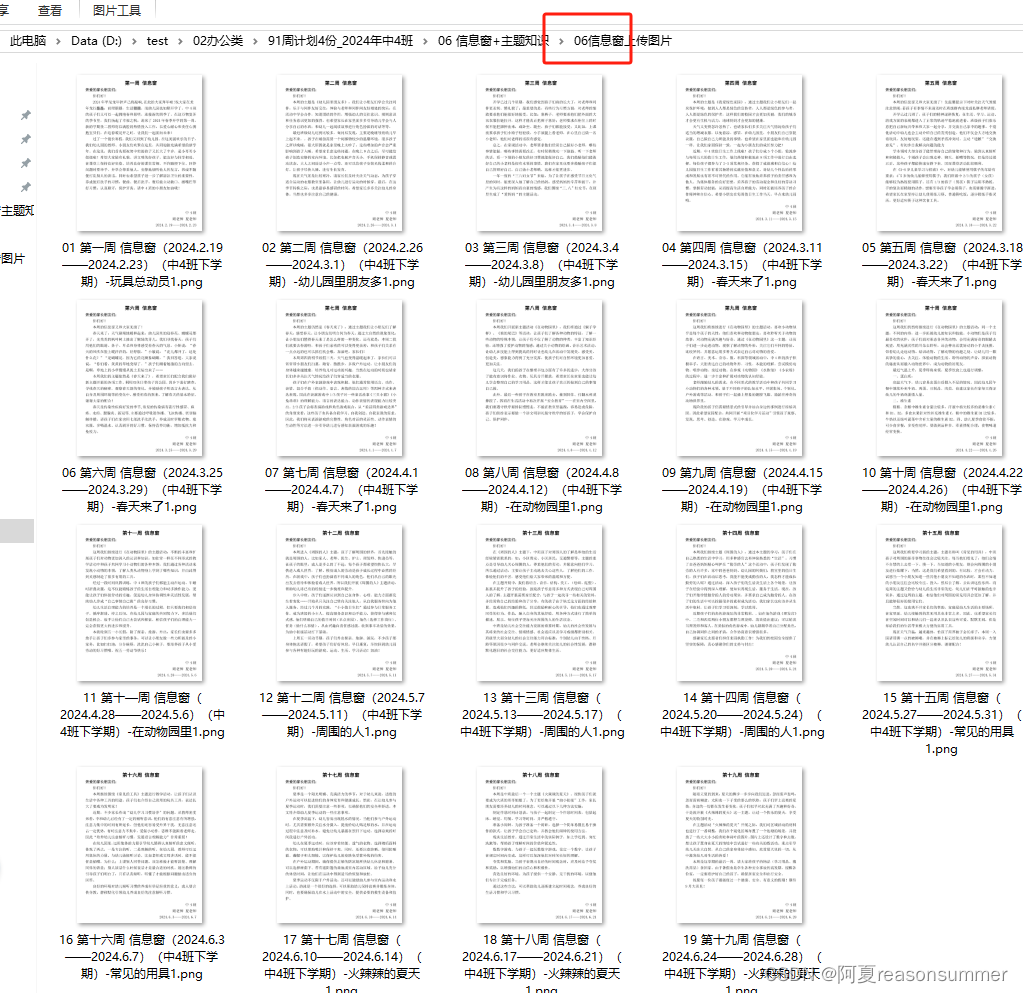
一、word做成图片png——图片上传网页
1、把“信息窗+主题知识”转为png格式(a4横板一页)
代码展示:

'''
作者:毛毛
性质:转载
原网址 https://zhuanlan.zhihu.com/p/367985422
安装python,确保以下模块已经安装:win32com,fitz,re
在桌面新建文件夹,命名为:word2pdf2png
将需要转换的word(只能docx格式,可以多个)放入文件夹word2pdf2png
复制以下代码并运行。
本代码只生成png 文件夹内只有一级,子文件不生成
说明:
1、
2、把“03 新周计划生成(原版)”的内容复制到“04 新周计划(没有反思的打印)”
3、把“04 新周计划(没有反思的打印)”内容复制到“05 新周计划(没有反思的jpg上传)”
4、然后“05 新周计划(没有反思的jpg上传)”文件夹删除并生成第一张无反思的图片20份
5、空余时间。把““03 新周计划生成(原版)”文件夹的内容复制到“08 新周计划生成(手动修改-准)”文件夹,手动修改
(1)周计划第一页反思(限定在一页内)
(2)教案等
'''
#coding=utf-8
from win32com.client import Dispatch
import os
import re
import fitz
wdFormatPDF = 17 #转换的类型
zoom_x=2 #尺寸大小,越大图片越清晰 5超大,这里改成2
zoom_y=2 #尺寸大小,越大图片越清晰,长宽保持一致
rotation_angle=0#旋转的角度,0为不旋转
# print(----'把"04合成新信息窗主题知识"文件夹里的资料复制到"05jpg上传"'-----)
import os
import shutil
def copy_docx_files(source_dir, dest_dir):
for filename in os.listdir(source_dir):
source_path = os.path.join(source_dir, filename)
dest_path = os.path.join(dest_dir, filename)
if os.path.isfile(source_path) and filename.endswith(".docx"):
shutil.copy(source_path, dest_path)
if os.path.isdir(source_path):
copy_docx_files(source_path, dest_dir)
# 指定源文件夹和目标文件夹
old_pat =r'D:\test\02办公类\91周计划4份_2024年中4班\06 信息窗+主题知识\04合成新信息窗主题知识(修改补充版)' # 要复制的文件所在目录
new_path = r'D:\test\02办公类\91周计划4份_2024年中4班\06 信息窗+主题知识\05jpg上传' #新路径
# 调用复制函数
copy_docx_files(old_pat, new_path)
#print(----生成PDF和第一页图片-----)
def doc2pdf2png(input_file):
for root, dirs, files in os.walk(input_file):
for file in files:
if re.search('\.(docx|doc)$', file):
filename = os.path.abspath(root + "\\" + file)
print('filename', filename)
word = Dispatch('Word.Application')
doc = word.Documents.Open(filename)
doc.SaveAs(filename.replace(".docx", ".pdf"), FileFormat=wdFormatPDF)
doc.Close()
word.Quit()
for root, dirs, files in os.walk(input_file):
for file in files:
if re.search('\.pdf$', file):
filename = os.path.abspath(root + "\\" + file)
print('filename', filename)
# 打开PDF文件
pdf = fitz.open(filename)
# 逐页读取PDF
for pg in range(0, pdf.pageCount):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=False)
# 开始写图像
pm.writePNG(filename.replace('.pdf', '') + str(pg+1) + ".png")
pdf.close()
doc2pdf2png(new_path)
# 删除生成文件PDF 和 生成文件docx
for parent, dirnames, filenames in os.walk(new_path):
for fn in filenames:
if fn.lower().endswith('.pdf'):
os.remove(os.path.join(parent, fn))
if fn.lower().endswith('.docx'):# 删除原始文件docx 正则[pdf|docx]套不上,只能分成两条了
os.remove(os.path.join(parent, fn))
# 删除png中,尾号是2-8的png(Word只要第一页,后面生成的第二页图片不要
for parent, dirnames, filenames in os.walk(new_path):
for fn in filenames:
for k in range(2,9): # png文件名的尾数是2,3,4,5,6,7,8 不确定共有几页,可以把9这个数字写大一点)
if fn.lower().endswith(f'{k}.png'): # 删除尾号为2,3,4,5,6,7,8的png图片 f{k}='{}'.formart(k)
os.remove(os.path.join(parent, fn))图片结果展示
先出现word和PDF
在出现一张图片
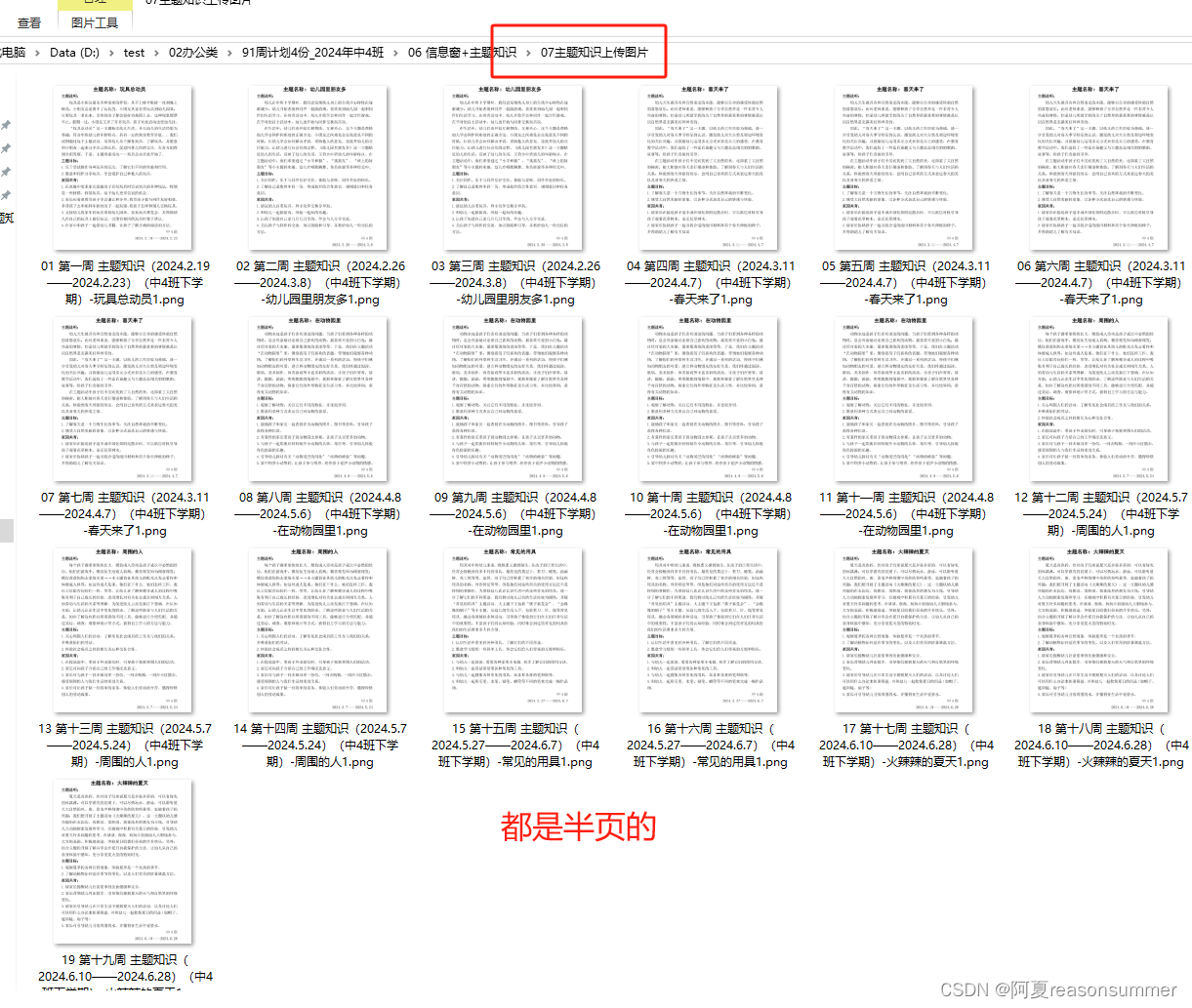
 图片版,便于直观了解 信息窗和主题说明是否正好半页
图片版,便于直观了解 信息窗和主题说明是否正好半页

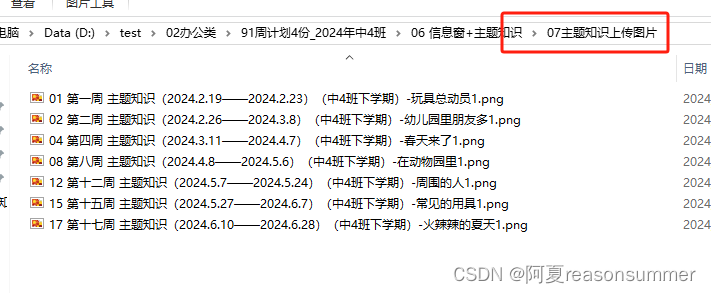
2、把png切割成两类图片,便于上传“班级主页”
由于信息窗和主题知识在一页上,但是上传班级主页时,需要拆分开来,所以要用坐标把图片切割。



代码展示
# 参考网址:https://blog.csdn.net/weixin_42182534/article/details/125773141?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E6%88%AA%E5%8F%96%E5%9B%BE%E7%89%87%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125773141.nonecase&spm=1018.2226.3001.4187
'''
功能:切割图片
'''
import os
import os.path
from PIL import Image
cood=[[30,85,842,1100],[830,85,1684,1100]]
# 左边距,上边距,右边距,下边距
# # # print('----------第2步:新建一个临时文件夹------------')
# # # # # 新建一个”装N份word和PDF“的文件夹
h=['']
name=['06信息窗上传图片','07主题知识上传图片']
ys=['信息窗','主题知识']
for i in range(len(name)):
imagePath1=r'D:\test\02办公类\91周计划4份_2024年中4班\06 信息窗+主题知识\{}'.format(name[i])
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath1) # 若图片文件夹不存在就创建
else:
pass
# 定义文件所在文件夹
image_dir = r'D:\test\02办公类\91周计划4份_2024年中4班\06 信息窗+主题知识\05jpg上传'
for parent, dir_name, file_names in os.walk(image_dir): # 遍历每一张图片
for filename in file_names:
# print(filename)
# 第19周 中4班 信息窗主题知识(2024.6.24——2024.6.28)1.png
pic_name = os.path.join(parent, filename)
image = Image.open(pic_name)
_width, _height = image.size
# print(_width, _height)
# 1684 1191
# print(newname1)
# newname2= split_str[1]# _的第0部分=序号
a=cood[i][0]
b=cood[i][1]
c=cood[i][2]
d=cood[i][3]
# 定义裁剪范围(left, upper, right, lower)1024
# # box = image.crop((0,0,123,123))
box = image.crop((a,b,c,d))
# 10 第十周 信息窗(2024.4.22——2024.4.26)(2024.4.8——2024.5.6)(中4班下学期)-在动物园里1.png
# 各种切割点
u= filename.split(' ')
v= filename.split(')')
w= filename.split('(')
# 第0空格左边是01 第1空格左边是第五周,ys是“信息窗或主题知识”
# w [1]=第1组()也就是信息窗的日期范围,(每周一份不同)
# w [2]=第2组()也就是主题说明日期范围(2-3周一份相同)
week=u[0]+' '+u[1]+' '+ys[i]+ '('+w[i+1]+'('+w[3]
print(week)
# 19 第十九周 信息窗(2024.6.24——2024.6.28)(中4班下学期)-火辣辣的夏天1.png
box.save(imagePath1+r'\\{}'.format(week))
# print('Done!') 
利用坐标切割图片,并保存在指定文件夹里,控制图片名称
(1)信息窗:上传图片


上传过程详见
(2)主题知识:上传图片

上传过程详见
结论:终于搞完了一套“周计划资料-信息窗主题说明”,耗费好久天,但是与去年相比,代码更周全,减少一些替换EXCEL的动作。更优化了代码。
在去年制作的基础上进一步优化
【办公类-22-01】周计划系列(1)-生成“信息窗”(提取旧docx内容,写入EXCLE模板,再次生成新docx)-CSDN博客文章浏览阅读232次。【办公类-22-01】周计划系列-信息窗的制作(提取旧docx内容,写入EXCLE模板,再次生成新docx)https://blog.csdn.net/reasonsummer/article/details/129843824![]() https://blog.csdn.net/reasonsummer/article/details/129843824【办公类-22-02】周计划系列(2)-生成“主题知识”(提取旧docx指定段落的内容,写入EXCLE模板,再次生成新docx)_从docx-tpl怎么:导入docx模板-CSDN博客文章浏览阅读583次。【办公类-22-02】周计划系列(2)-生成“主题知识”(提取旧docx指定段落的内容,写入EXCLE模板,再次生成新docx)_从docx-tpl怎么:导入docx模板https://blog.csdn.net/reasonsummer/article/details/129902271
https://blog.csdn.net/reasonsummer/article/details/129843824【办公类-22-02】周计划系列(2)-生成“主题知识”(提取旧docx指定段落的内容,写入EXCLE模板,再次生成新docx)_从docx-tpl怎么:导入docx模板-CSDN博客文章浏览阅读583次。【办公类-22-02】周计划系列(2)-生成“主题知识”(提取旧docx指定段落的内容,写入EXCLE模板,再次生成新docx)_从docx-tpl怎么:导入docx模板https://blog.csdn.net/reasonsummer/article/details/129902271![]() https://blog.csdn.net/reasonsummer/article/details/129902271
https://blog.csdn.net/reasonsummer/article/details/129902271
内容很多啊,我感觉还需要进一步厘清思路,继续优化设计一些可以通用的“周计划系列替换代码”
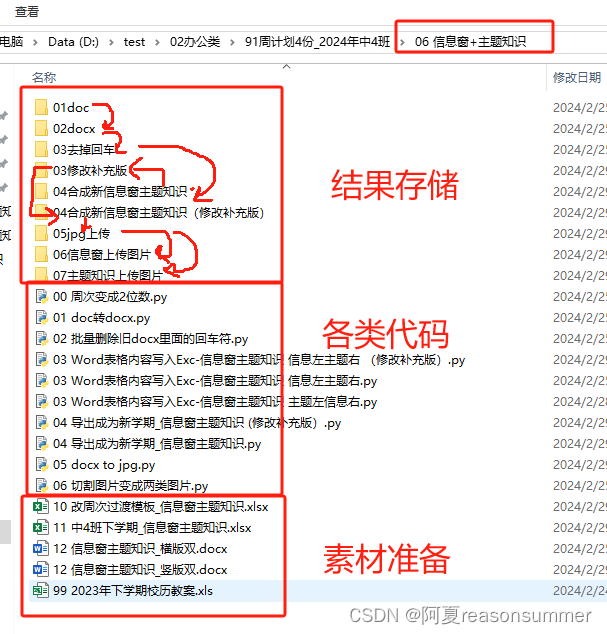
二、word合并PDF——批量打印A4纸

用AI对话大师写一段Python代码
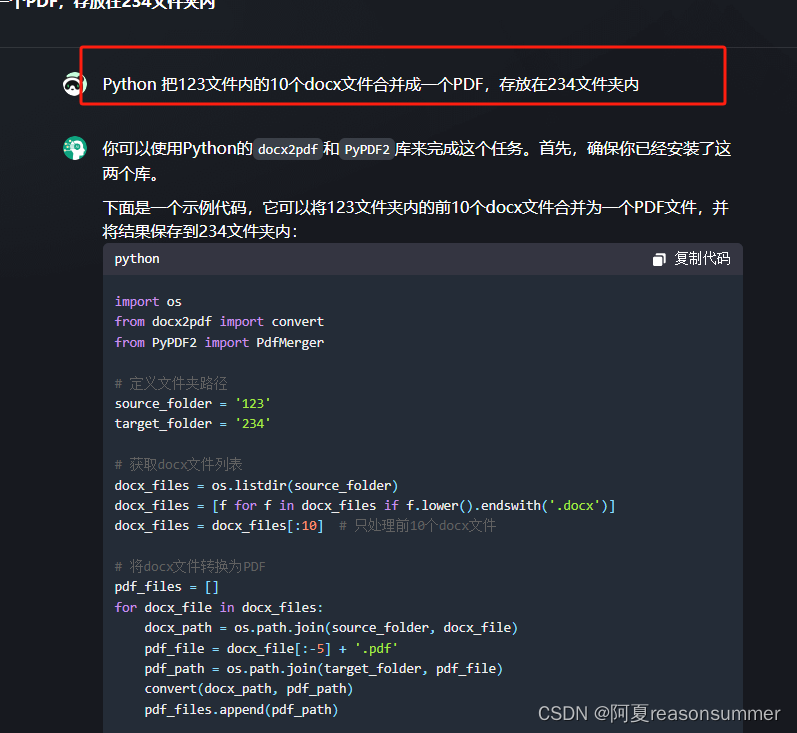

代码展示
# 19份docx合并成1个pdf
import os
from docx2pdf import convert
from PyPDF2 import PdfMerger
# 定义文件夹路径
source_folder = '123'
target_folder = '234'
print('-----复制修改过的文件“04合成新信息窗和主题知识”到03修改补充版,类似与再次放在“03去掉回车”-----')
path = r'D:\test\02办公类\91周计划4份_2024年中4班\06 信息窗+主题知识'
# 源文件夹路径
source_folder= path+r'\04合成新信息窗主题知识(修改补充版)'
# 目标文件夹路径
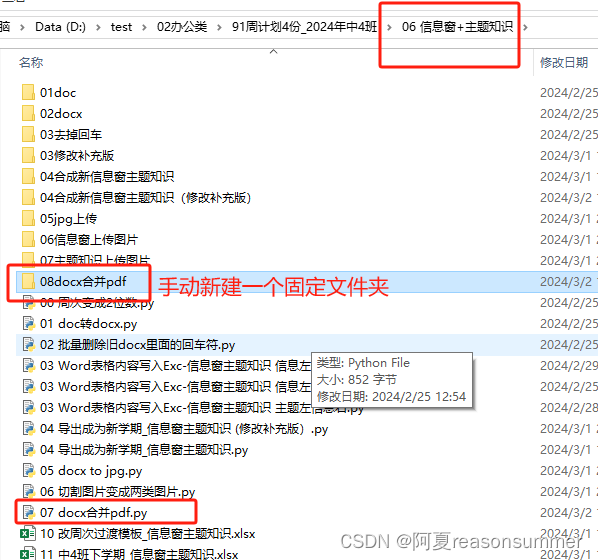
target_folder = path+r'\08docx合并pdf'
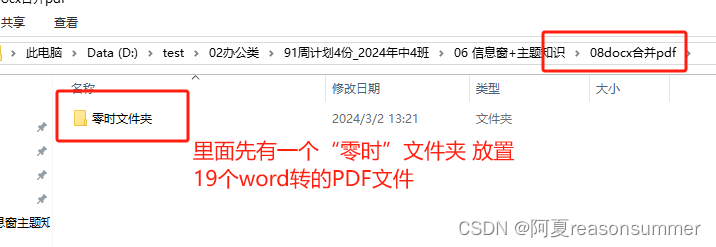
# 零时文件夹
t_folder = target_folder+r'\零时文件夹'
if not os.path.exists(t_folder): # 判断存放图片的文件夹是否存在
os.makedirs(t_folder) # 若图片文件夹不存在就创建
else:
pass
# 获取docx文件列表
docx_files = os.listdir(source_folder)
docx_files = [f for f in docx_files if f.lower().endswith('.docx')]
docx_files = docx_files[:] # 只处理前10个docx文件 所有文件都处理
# 将docx文件转换为PDF
pdf_files = []
for docx_file in docx_files:
docx_path = os.path.join(source_folder, docx_file)
pdf_file = docx_file[:-5] + '.pdf'
pdf_path = os.path.join(t_folder, pdf_file)
convert(docx_path, pdf_path)
pdf_files.append(pdf_path)
# 合并PDF文件
merger = PdfMerger()
for pdf_file in pdf_files:
merger.append(pdf_file)
# 保存合并后的PDF文件
output_file = os.path.join(target_folder, '(打印)2024年2月中4班信息窗主题知识合并版.pdf')
merger.write(output_file)
merger.close()
print('合并完毕,结果保存在{}'.format(output_file))
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(t_folder ) #递归删除文件夹,即:删除非空文件夹运行时,代码会生成一个零时文件夹,19份docx文件会转成19个PDF文件
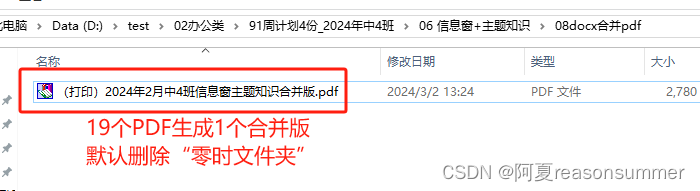


打印过程
日后展示……

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











