







背景需求:
又到了期末,各种班级资料需要提交。
有一份自主游戏观察记录需要写19周(每周2次)的观察记录,并根据参考书填写一级、三级、五级的评价指标。

去年中六班的时候,我很认真的手写了21周的户外游戏活动内容,主动成为2个需要提交文本资料的班级。
今年组长选了中二和中五提交打印资料。因此中四班的游戏观察资料可以不那么“优质”,所以本学期我想“偷个懒”,再次使用去年的内容做电子稿提交。
考虑到这套资料也给过其他班级,我担心会出现重复,所以有两个调整的思路:
1、将每个周次的内容进行替换,如原来第1周的内容放到第15周,第13周内容调到第2周。
2、虽然内容没有修改,但至少将孩子的名字替换成新的名字(中四班孩子的小名)
设计过程。
1、原素材


2、模板
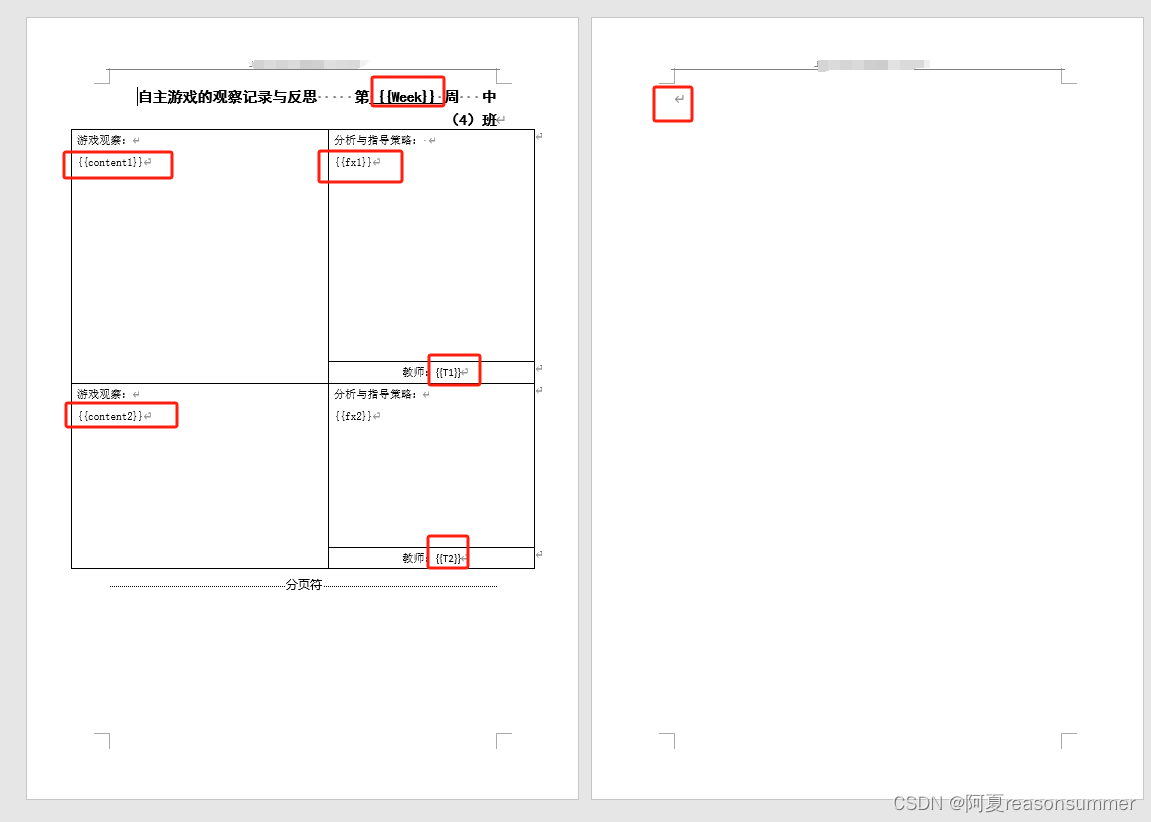
3、代码思路
(1)读取原素材表格中各个单元格里面的内容,新建一个excel并保存这些内容


(2)手动更改小名:因为不确定出现哪些名字,需要把表格拉宽,查看里面的名字。这里程序要会暂停。

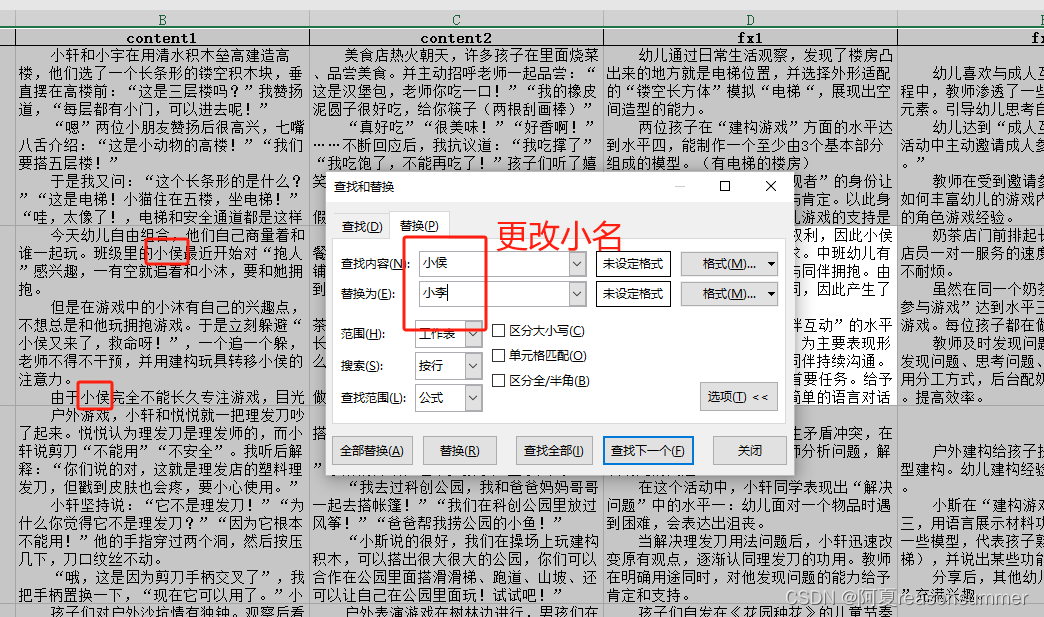
(3)改完以后,打乱行的顺序,把文字内容重写排列,
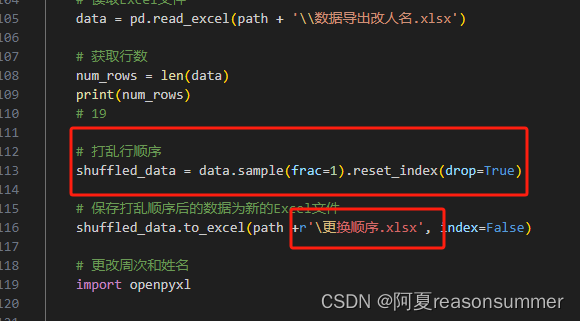
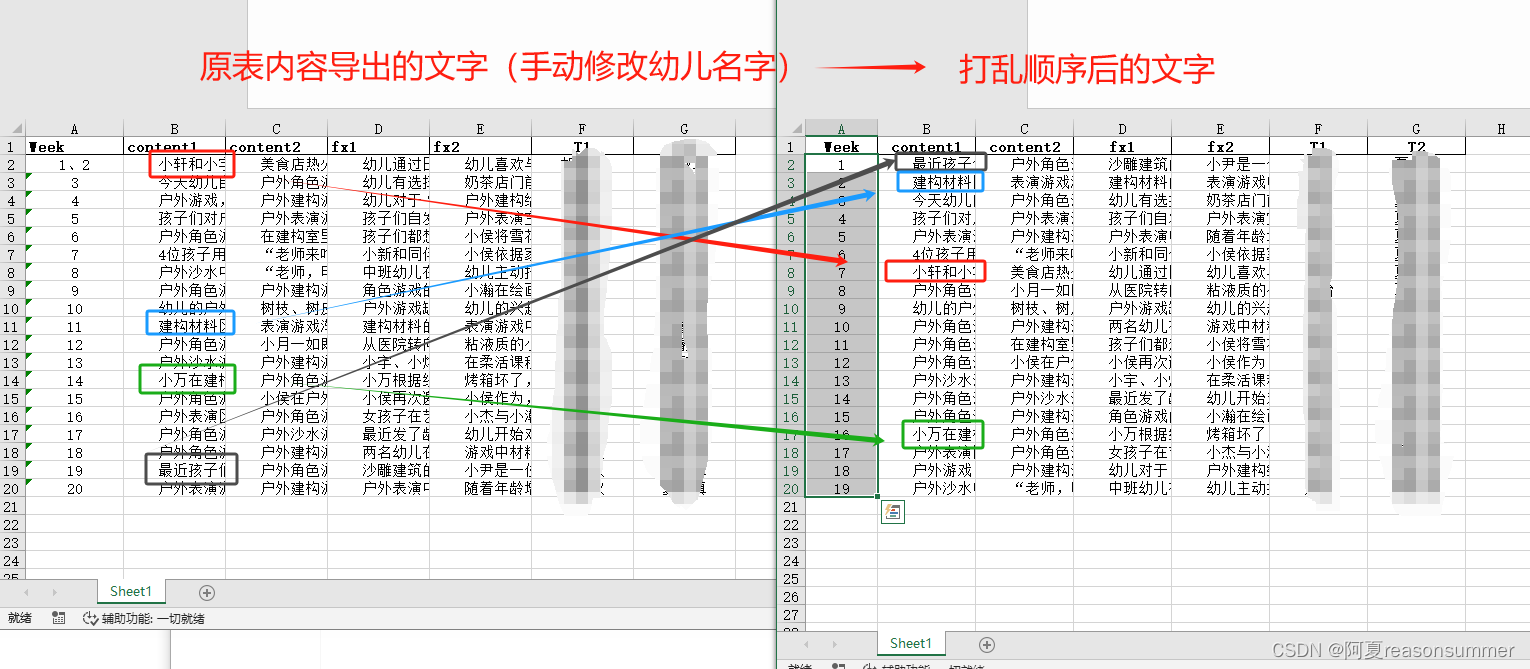 (4)把excel每行内容生成一个docx,把所有doc合并在一起
(4)把excel每行内容生成一个docx,把所有doc合并在一起
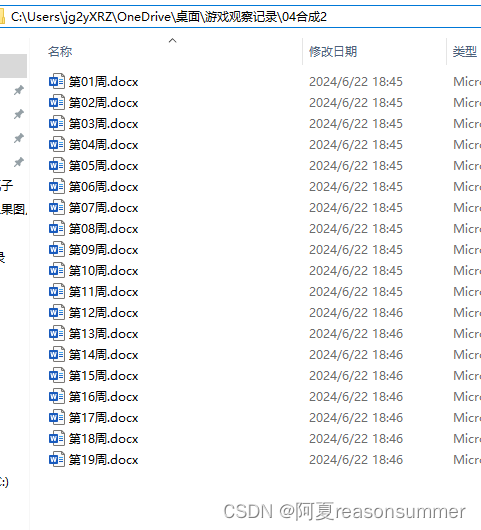

然后程序把所有的docx合并在一个docx内

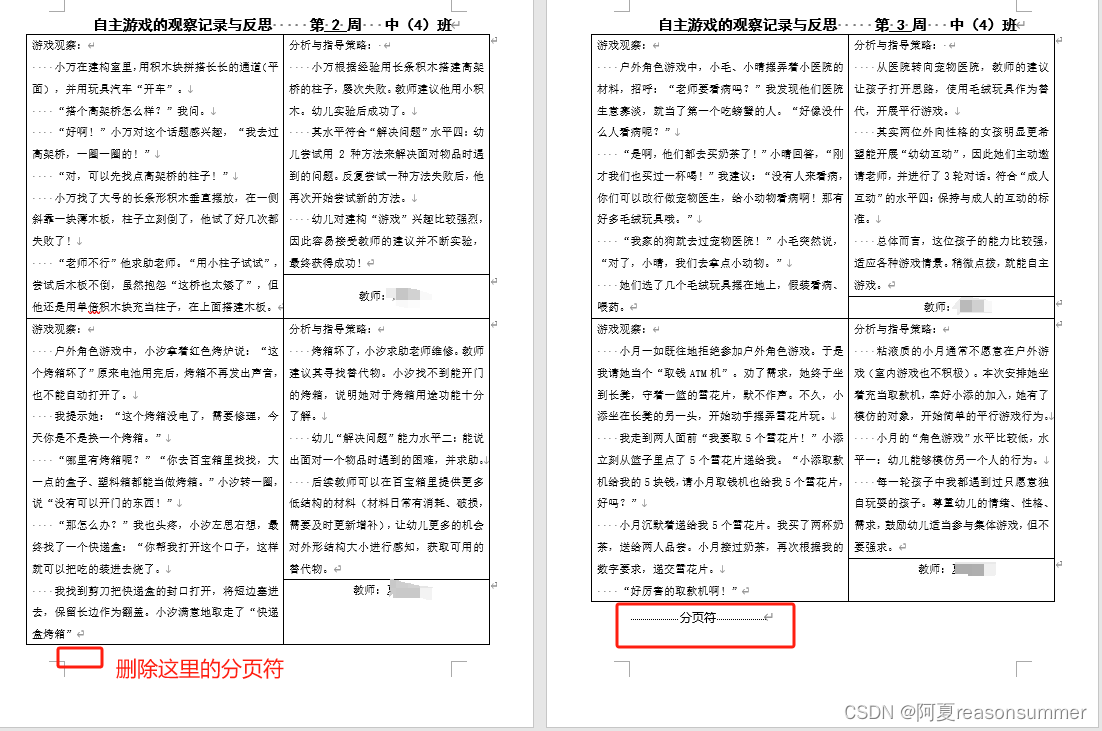
部分表格手动调整(删除回车符),确保每个表格内容都在一页上。


代码展示:
'''
项目:期末资料:19周游戏观察记录内容周次调换
工具:星火讯飞、阿夏
时间:2024年6月20日
'''
import re
import pandas as pd
from docx import Document
import time
for y in range(5):
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\游戏观察记录'
# 读取1.docx文件
doc = Document(path + r"\中(6)班自主游戏观察记录(202302-202306)全部户外.docx")
weeks=19 # 一共几周
name1='张三'
name2='李四'
print('---1、提取原来的游戏观察记录内容-----')
# 提取所有段落中“第”和“周”之间的内容
results = []
for paragraph in doc.paragraphs:
content = paragraph.text
pattern = r"第(.*?)周"
result = re.findall(pattern, content)
if result:
results.extend(result)
# 缩进2字符
b=' '
table_data1 = []
for table in doc.tables:
cell_value1 = table.cell(0, 0).text.replace(" ", "") # 清除缩进
lines1 = cell_value1.split('\n')
del lines1[0] # 删除第一行
new_lines1 = [b + line for line in lines1] # 在每行前面加四个空格
new_cell_value1 = '\n'.join(new_lines1)
table_data1.append(new_cell_value1)
print(new_cell_value1)
table_data2 = []
for table in doc.tables:
cell_value2 = table.cell(2, 0).text.replace(" ", "") # 清除缩进
lines2 = cell_value2.split('\n')
del lines2[0] # 删除第一行
new_lines2 = [b + line for line in lines2] # 在每行前面加四个空格
new_cell_value2 = '\n'.join(new_lines2)
table_data2.append(new_cell_value2)
print(new_cell_value2)
table_data3 = []
for table in doc.tables:
cell_value3 = table.cell(0, 1).text.replace(" ", "") # 清除缩进
lines3 = cell_value3.split('\n')
del lines3[0] # 删除第一行
new_lines3 = [b + line for line in lines3] # 在每行前面加四个空格
new_cell_value3 = '\n'.join(new_lines3)
table_data3.append(new_cell_value3)
print(new_cell_value3)
table_data4 = []
for table in doc.tables:
cell_value4 = table.cell(2, 1).text.replace(" ", "") # 清除缩进
lines4 = cell_value4.split('\n')
del lines4[0] # 删除第一行
new_lines4 = [b + line for line in lines4] # 在每行前面加四个空格
new_cell_value4 = '\n'.join(new_lines4)
table_data4.append(new_cell_value4)
print(new_cell_value4)
table_data5= []
for table in doc.tables:
cell_value5 = table.cell(1, 1).text.replace(" ", "") # 清除缩进
print(cell_value5)
table_data5.append(cell_value5[3:])
# print(new_cell_value5)
table_data6= []
for table in doc.tables:
cell_value6 = table.cell(3, 1).text.replace(" ", "") # 清除缩进
print(cell_value6)
table_data6.append(cell_value6[3:])
# print(new_cell_value5)
df = pd.DataFrame({'Week': results, 'content1': table_data1,'content2': table_data2,'fx1': table_data3,'fx2': table_data4,'T1': table_data5,'T2': table_data6})
df.to_excel(path + '\\数据导出改人名.xlsx', index=False)
# 手动改人名
print("手动改人名,按任意键继续...")
input() # 这里会暂停程序,直到用户输入信息
print("程序继续执行...")
print('---2、手动改人名,随机抽取行数,重新保存一份----')
import pandas as pd
# 读取Excel文件
data = pd.read_excel(path + '\\数据导出改人名.xlsx')
# 获取行数
num_rows = len(data)
print(num_rows)
# 19
# 打乱行顺序
shuffled_data = data.sample(frac=1).reset_index(drop=True)
# 保存打乱顺序后的数据为新的Excel文件
shuffled_data.to_excel(path +r'\更换顺序.xlsx', index=False)
# 更改周次和姓名
import openpyxl
# 打开Excel文件
workbook = openpyxl.load_workbook(path +r'\更换顺序.xlsx')
# 选择工作表
worksheet = workbook.active
# 在A列第2行开始写入1-20的数字
for i in range(2, num_rows+2):
worksheet.cell(row=i, column=1).value = i - 1
# 在F列写入教室A的名字
for i in range(2, num_rows+2):
worksheet.cell(row=i, column=6).value = name1
# 在G列写入教室A的名字
for i in range(2, num_rows+2):
worksheet.cell(row=i, column=7).value = name2
time.sleep(2)
# 保存修改后的Excel文件
workbook.save(path+r'\更换顺序.xlsx')
print('---3、写入模板生成新的文件--')
import os
import pandas as pd
from docxtpl import DocxTemplate
file_path = path + r'\04合成2'
try:
os.mkdir(file_path)
except:
pass
list = pd.read_excel(path + '\\更换顺序.xlsx')
Week= list["Week"]
content1 = list["content1"].str.rstrip()
content2 = list["content2"].str.rstrip()
fx1 = list["fx1"].str.rstrip()
fx2 = list["fx2"].str.rstrip()
T1 = list["T1"].str.rstrip()
T2 = list["T2"].str.rstrip()
num = list.shape[0]
for i, (w, c1, c2, f1, f2 ,t1, t2) in enumerate(zip(Week, content1, content2, fx1,fx2,T1, T2)):
context = {
"Week": w,
"content1": c1,
"content2": c2,
"fx1": f1,
"fx2": f2,
"T1": t1,
"T2": t2,
}
tpl = DocxTemplate(path + '\\模版游戏观察记录与反思(2024.1).docx')
tpl.render(context)
time.sleep(4)
tpl.save(file_path + fr"\第{i+1:02d}周.docx")
print('---4、合并文档--')
import os
import shutil
from docx import Document
def merge_docx_files(input_folder, output_file):
output_doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\游戏观察记录\04合成2\第01周.docx')
files = os.listdir(input_folder)
for index, file in enumerate(files):
if file.endswith(".docx") and index != 0:
input_file = os.path.join(input_folder, file)
input_doc = Document(input_file)
# output_doc.add_page_break() # 添加换页符
for element in input_doc.element.body:
output_doc.element.body.append(element)
time.sleep(2)
output_doc.save(output_file)
input_folder = file_path
output_file = path+fr"\{y:02d}中4班 游戏活动观察记录(202402-202406)全部户外.docx"
merge_docx_files(input_folder, output_file)
存在问题:
本代码有一个问题,就是每次提取的文字会有缺失,原因不明,
所以我就生成多份随机排序的文件,从中挑选一个内容相对多的文件,作为提交的电子稿的资料。





运气好,以下这份文字较为齐全(撑满格子)
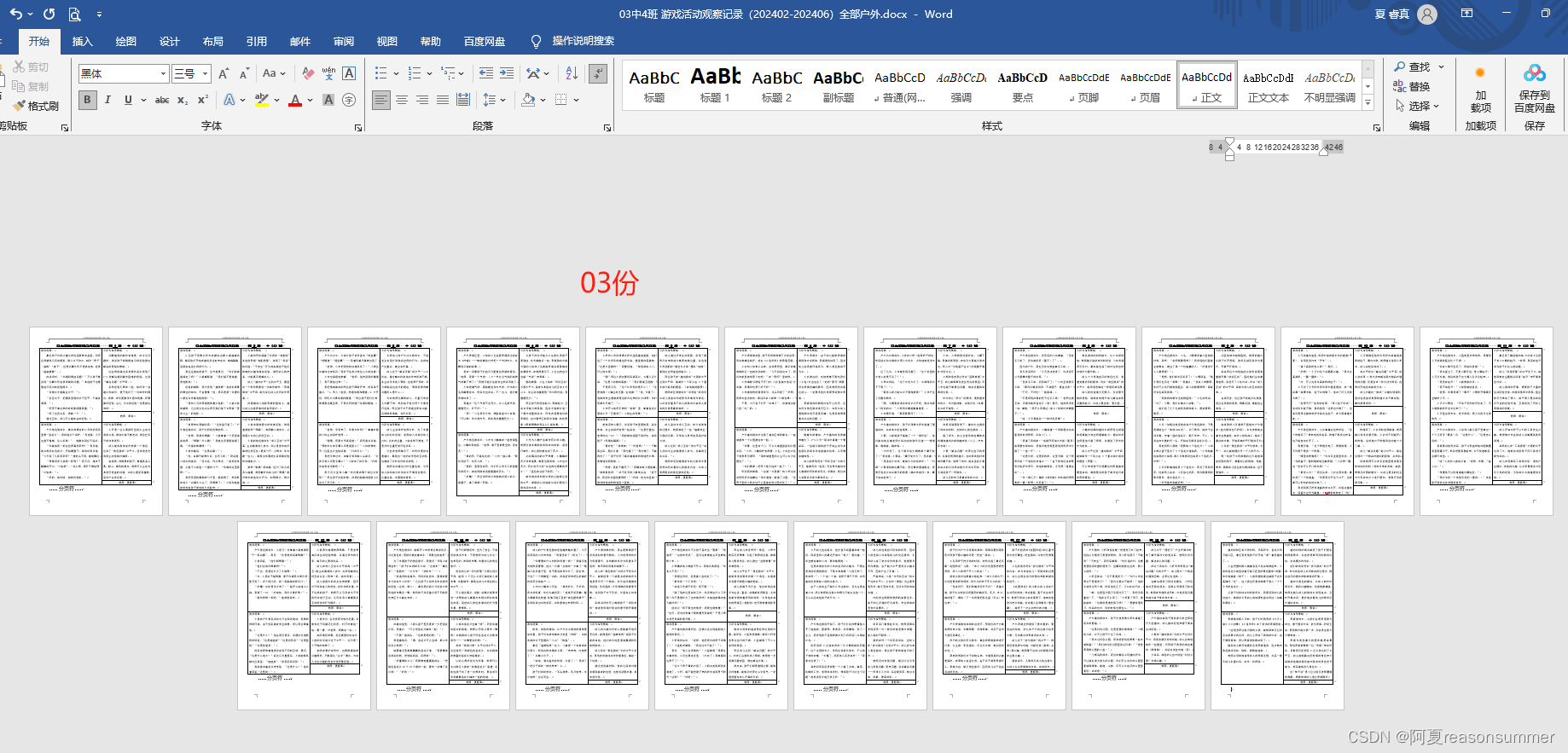
哎,偷懒就不能保证打乱文字的稳定性,所以要多抽几次博一个成功的概率,或者还是乖乖的自己手写吧!
=================================================================
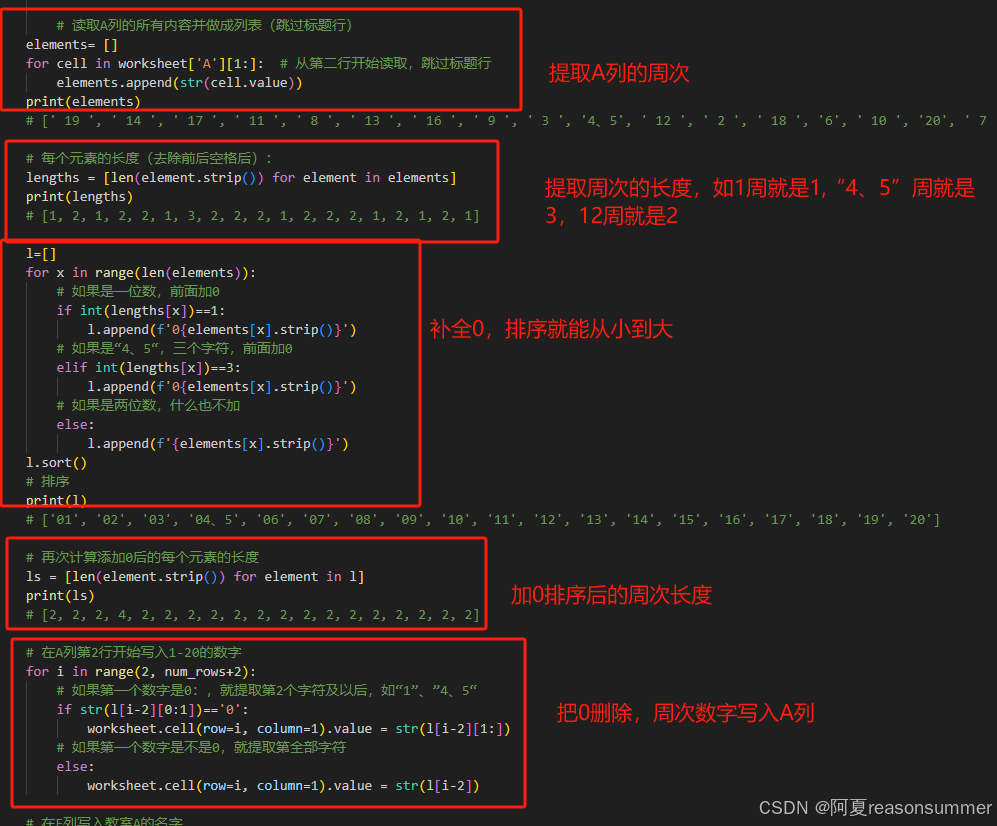
20241102再次做游戏计划打乱
本次的周次不是一个数字,而是有国庆节的45周合并,

为了将数字排序,做了大量的转化
代码展示
'''
项目:期末资料:19周游戏观察记录内容周次调换
工具:星火讯飞、阿夏
时间:2024年6月20日
项目:期末资料:19周游戏观察记录内容周次调换(包含4、5周)
工具:星火讯飞、阿夏
时间:2024年11月02日
'''
import re
import pandas as pd
from docx import Document
import time
for y in range(1):
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\游戏观察记录'
# 读取1.docx文件
# doc = Document(path + r"\00中2班 游戏活动观察记录(202402-202406)全部户外.docx")
weeks=19 # 一共几周
name1='辛峰'
name2='夏叡真'
# print('---1、提取原来的游戏观察记录内容-----')
# # 提取所有段落中“第”和“周”之间的内容
# results = []
# for paragraph in doc.paragraphs:
# content = paragraph.text
# pattern = r"第(.*?)周"
# result = re.findall(pattern, content)
# if result:
# results.extend(result)
# # 缩进2字符
# b=' '
# table_data1 = []
# for table in doc.tables:
# cell_value1 = table.cell(0, 0).text.replace(" ", "") # 清除缩进
# lines1 = cell_value1.split('\n')
# del lines1[0] # 删除第一行
# new_lines1 = [b + line for line in lines1] # 在每行前面加四个空格
# new_cell_value1 = '\n'.join(new_lines1)
# table_data1.append(new_cell_value1)
# print(new_cell_value1)
# table_data2 = []
# for table in doc.tables:
# cell_value2 = table.cell(2, 0).text.replace(" ", "") # 清除缩进
# lines2 = cell_value2.split('\n')
# del lines2[0] # 删除第一行
# new_lines2 = [b + line for line in lines2] # 在每行前面加四个空格
# new_cell_value2 = '\n'.join(new_lines2)
# table_data2.append(new_cell_value2)
# print(new_cell_value2)
# table_data3 = []
# for table in doc.tables:
# cell_value3 = table.cell(0, 1).text.replace(" ", "") # 清除缩进
# lines3 = cell_value3.split('\n')
# del lines3[0] # 删除第一行
# new_lines3 = [b + line for line in lines3] # 在每行前面加四个空格
# new_cell_value3 = '\n'.join(new_lines3)
# table_data3.append(new_cell_value3)
# print(new_cell_value3)
# table_data4 = []
# for table in doc.tables:
# cell_value4 = table.cell(2, 1).text.replace(" ", "") # 清除缩进
# lines4 = cell_value4.split('\n')
# del lines4[0] # 删除第一行
# new_lines4 = [b + line for line in lines4] # 在每行前面加四个空格
# new_cell_value4 = '\n'.join(new_lines4)
# table_data4.append(new_cell_value4)
# print(new_cell_value4)
# table_data5= []
# for table in doc.tables:
# cell_value5 = table.cell(1, 1).text.replace(" ", "") # 清除缩进
# print(cell_value5)
# table_data5.append(cell_value5[3:])
# # print(new_cell_value5)
# table_data6= []
# for table in doc.tables:
# cell_value6 = table.cell(3, 1).text.replace(" ", "") # 清除缩进
# print(cell_value6)
# table_data6.append(cell_value6[3:])
# # print(new_cell_value5)
# df = pd.DataFrame({'Week': results, 'content1': table_data1,'content2': table_data2,'fx1': table_data3,'fx2': table_data4,'T1': table_data5,'T2': table_data6})
# df.to_excel(path + '\\数据导出改人名.xlsx', index=False)
# # 手动改人名
# print("手动改人名,按任意键继续...")
# input() # 这里会暂停程序,直到用户输入信息
# print("程序继续执行...")
print('---2、手动改人名,随机抽取行数,重新保存一份----')
import pandas as pd
# 读取Excel文件
data = pd.read_excel(path + '\\数据导出改人名.xlsx')
# 获取行数
num_rows = len(data)
print(num_rows)
# 19
# 打乱行顺序
shuffled_data = data.sample(frac=1).reset_index(drop=True)
# 保存打乱顺序后的数据为新的Excel文件
shuffled_data.to_excel(path +r'\更换顺序.xlsx', index=False)
# 更改周次和姓名
import openpyxl
# 打开Excel文件
workbook = openpyxl.load_workbook(path +r'\更换顺序.xlsx')
# 选择工作表
worksheet = workbook.active
# 读取A列的所有内容并做成列表(跳过标题行)
elements= []
for cell in worksheet['A'][1:]: # 从第二行开始读取,跳过标题行
elements.append(str(cell.value))
print(elements)
# [' 19 ', ' 14 ', ' 17 ', ' 11 ', ' 8 ', ' 13 ', ' 16 ', ' 9 ', ' 3 ', '4、5', ' 12 ', ' 2 ', ' 18 ', '6', ' 10 ', '20', ' 7 ', ' 15 ', ' 1 ']
# 每个元素的长度(去除前后空格后):
lengths = [len(element.strip()) for element in elements]
print(lengths)
# [1, 2, 1, 2, 2, 1, 3, 2, 2, 2, 1, 2, 2, 2, 1, 2, 1, 2, 1]
l=[]
for x in range(len(elements)):
# 如果是一位数,前面加0
if int(lengths[x])==1:
l.append(f'0{elements[x].strip()}')
# 如果是“4、5“,三个字符,前面加0
elif int(lengths[x])==3:
l.append(f'0{elements[x].strip()}')
# 如果是两位数,什么也不加
else:
l.append(f'{elements[x].strip()}')
l.sort()
# 排序
print(l)
# ['01', '02', '03', '04、5', '06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20']
# 再次计算添加0后的每个元素的长度
ls = [len(element.strip()) for element in l]
print(ls)
# [2, 2, 2, 4, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
# 在A列第2行开始写入1-20的数字
for i in range(2, num_rows+2):
# 如果第一个数字是0:,就提取第2个字符及以后,如“1”、”4、5“
if str(l[i-2][0:1])=='0':
worksheet.cell(row=i, column=1).value = str(l[i-2][1:])
# 如果第一个数字是不是0,就提取第全部字符
else:
worksheet.cell(row=i, column=1).value = str(l[i-2])
# 在F列写入教室A的名字
for i in range(2, num_rows+2):
worksheet.cell(row=i, column=6).value = name1
# 在G列写入教室A的名字
for i in range(2, num_rows+2):
worksheet.cell(row=i, column=7).value = name2
time.sleep(2)
# 保存修改后的Excel文件
workbook.save(path+r'\更换顺序.xlsx')
print('---3、写入模板生成新的文件--')
import os
import pandas as pd
from docxtpl import DocxTemplate
file_path = path + r'\04合成2'
try:
os.mkdir(file_path)
except:
pass
list = pd.read_excel(path + '\\更换顺序.xlsx')
Week= list["Week"]
content1 = list["content1"].str.rstrip()
content2 = list["content2"].str.rstrip()
fx1 = list["fx1"].str.rstrip()
fx2 = list["fx2"].str.rstrip()
T1 = list["T1"].str.rstrip()
T2 = list["T2"].str.rstrip()
num = list.shape[0]
for i, (w, c1, c2, f1, f2 ,t1, t2) in enumerate(zip(Week, content1, content2, fx1,fx2,T1, T2)):
context = {
"Week": w,
"content1": c1,
"content2": c2,
"fx1": f1,
"fx2": f2,
"T1": t1,
"T2": t2,
}
tpl = DocxTemplate(path + '\\模版游戏观察记录与反思(2024.1).docx')
tpl.render(context)
time.sleep(4)
tpl.save(file_path + fr"\第{i+1:02d}周.docx")
print('---4、合并文档--')
import os
import shutil
from docx import Document
def merge_docx_files(input_folder, output_file):
output_doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\游戏观察记录\04合成2\第01周.docx')
files = os.listdir(input_folder)
for index, file in enumerate(files):
if file.endswith(".docx") and index != 0:
input_file = os.path.join(input_folder, file)
input_doc = Document(input_file)
# output_doc.add_page_break() # 添加换页符
for element in input_doc.element.body:
output_doc.element.body.append(element)
time.sleep(2)
output_doc.save(output_file)
input_folder = file_path
output_file = path+fr"\{y:02d}中2班 游戏活动观察记录(202402-202406)全部户外.docx"
merge_docx_files(input_folder, output_file)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











