







每一个汇编老师都会告诉你很多强的亚批的指令,但是不怎么说一个真正的、能跑起来的汇编程序长什么样。
在我学习的过程中,虽然有基本格式的讲解,但是说实话听着就很难受。
这也导致在上汇编实验的过程中,是属是难受。
从一个小程序说起
不是微信小程序啊,是比较短的汇编程序。
例:result=a+b
data segment
a db 1
b db 2
result db ?
string db 'result=$’
data ends
code segment
assume cs:code, ds:data
start: mov ax,data
mov ds,ax
mov al,a
add al,b
mov result,al
lea dx,string
mov ah,09
int 21h
add result,30h
mov dl,result
mov ah,2
int 21h
mov ah,4ch
int 21h
code ends
end start
是不是看着就很头疼,我们一点点分析。
指令
先说一下你到底在写什么。
一般来是汇编源程序是包括三种基本语句的,指令语句、伪指令语句和宏指令语句。
我们会写的是伪指令,宏指令也有以后再说。
指令语句则是CPU能看得懂的,也是他要运行的。伪指令最终会形成指令语句,经过汇编才能形成机器目标代码。
segment——段
本来是有很多的段的,其实常用的也就三个。
首先是存放数据的data段,这部分数据在内存中,定义一些我们可能会用到的量。
应该还有一个stack段,是我们用来定义堆栈空间大小的。
一般只有一句:dw 32 dup(?)
定义了一个大小为32个dw的没有初始值的空间
(dup表示循环,可以嵌套,如32 dup(1,2,10 dup(5))
最后,也是最重要的段就是代码段(code)
除了代码段之外,剩下的部分都不许有伪指令。
这里要提一点,我们的所有命名都不是固定的,segment名称都可以变化,只要在后面对应上就行。
另外我们的segment段可以简化定义成:

这样我们的代码就变成了:
.MODEL SMALL
.DATA
;此处输入数据段代码
.STACK
;此处输入堆栈段代码
.CODE
START:
MOV AX, @DATA
MOV DS, AX
;此处输入代码段代码
MOV AH, 4CH
INT 21H
END START
可以看到,没了assume,绑定的方式也发生了改变(这两个在后面有提)
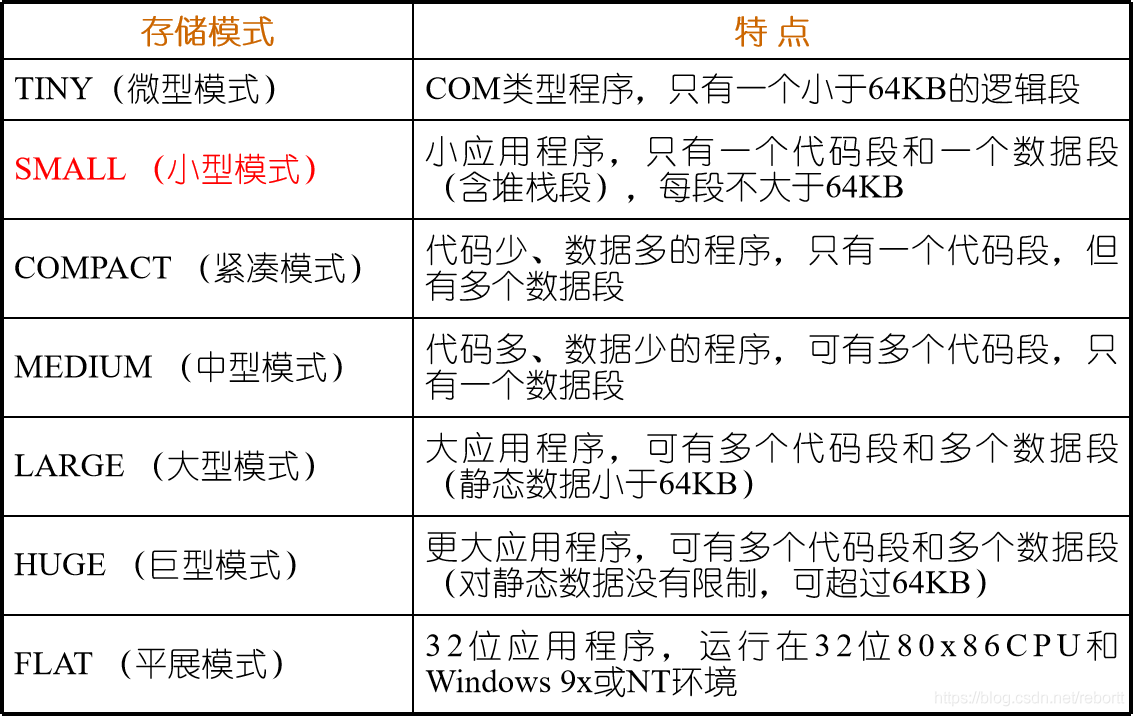
但使用简化段定义时,必须有存储模式.MODEL语句,且位于所有简化段定义语句之前。
这个东西说实话感觉一般是用不上,我们一般来说small就够了,下面给出small:
start
start:
end start
组成了程序开始和结尾的部分。
在子程序中,我们的start是应该放在主模块的开始处,而不是整个代码段的开始。
剩下的情况,无特殊情况就放在code段开始,end start是在code段结束之后。
这里的start和上面的segment一样,都只是一个标志,可以换成其他的,但是这个比较常用而已。
另外如果是第一条指令就是程序开始,那么我们就可以省略两个start,变成:
code segment
……
code ends
end
assume伪指令
assume 段寄存器:段名
相当于将segment段和我们的数据段进行匹配。
- data段就匹配ds段
- stack段就匹配ss段
- code段就匹配cs段
其实不止这三个,但是基本上常用到的也就这些了。
讲一下程序的一些组成部分
绑定
mov ax, data
mov ds, ax ; 数据段段地址 ——> 段寄存器
这个当时迷惑了我很久,其实就是一个绑定段和段寄存器,就是一个套话,但是还不能没有。
变量
我们写程序一定少不了变量的存在,毕竟你不能啥都往寄存器里面装吧。
我们需要将一些东西放在内存中时,就需要变量的存在了。
变量书写在data段中的,一般格式: 名称+类型(db、dw、dd,分别为字节、单字和双字)+初始值,如果没有初始值就写一个“?"上去。
(汇编默认为十进制数据,如果需要十六进制记得加h)
字符串需要用双引号或者单引号括起来,如’12AB’,‘string’,
当然如果将12AB写成 31h,32h,41h,42h也行,这时不需要单引号。
(引号问题注意一下内部会不会造成冲突,和python感觉差不多。)
如果是数组的话:
num db 10,20,30
outrec db 10 dup(0)
记住我们的num和outrec是数组的首地址就行。
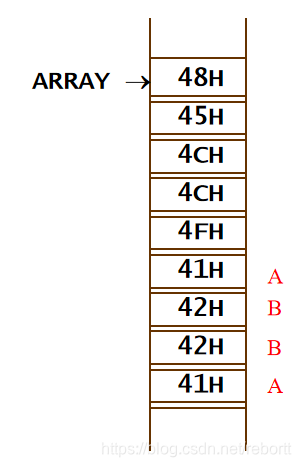
如果我们有这样的一个定义:
ARRAY DB ‘HELLO’
DB ‘AB’ ;两个数据
DW ‘AB’ ;双字
那么在内存中,我们看到的是这样的:(注意顺序,按照顺序上面两个是db型,下面dw型)
我们先要知道,越往下地址越大。
dw作为一个整体,所以是A在高字节,B在低字节,所以A在下B在上;
对于db类型,则是A、B两个部分组成的字符串,所以需要将字符串的第一个元素放在首地址,然后将剩下的元素向后排,故A在上B在下。
标号
上面的例子不好就在于没有循环或者条件分支,看不到标号。
在循环或者分支的过程中,我们需要进行跳转,这时就需要标号了:

红框的部分就是标号,配合跳转指令能跳转到对应标号的位置(红字),其中loop和jnz都有跳转的属性。
奇奇怪怪的东西
这部分可能就不是很常用了,但是还是先给出来吧。
强转
我们有时候可能在赋值过程中,类型匹配不上,如:
OPER1 DB ?, ?
……
MOV AX, OPER1+1
字节和字对不上,会报错。这时我们就需要ptr指令了。
MOV AX, WORD PTR OPER1+1
这时我们是将oper1数组的第二位和其前面一个字的内容都取出来赋值给ax寄存器。
如果内存是这样的:
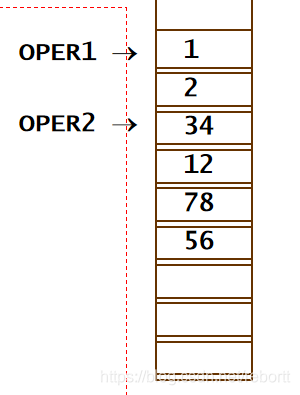
那么ax就为3402h。(oper1+1在2对应的地址)
如果是 MOV AL, BYTE PTR OPER2,此时al寄存器为34h,因为此时的地址为34h处的地址,我们只需要一个字节。
label伪指令
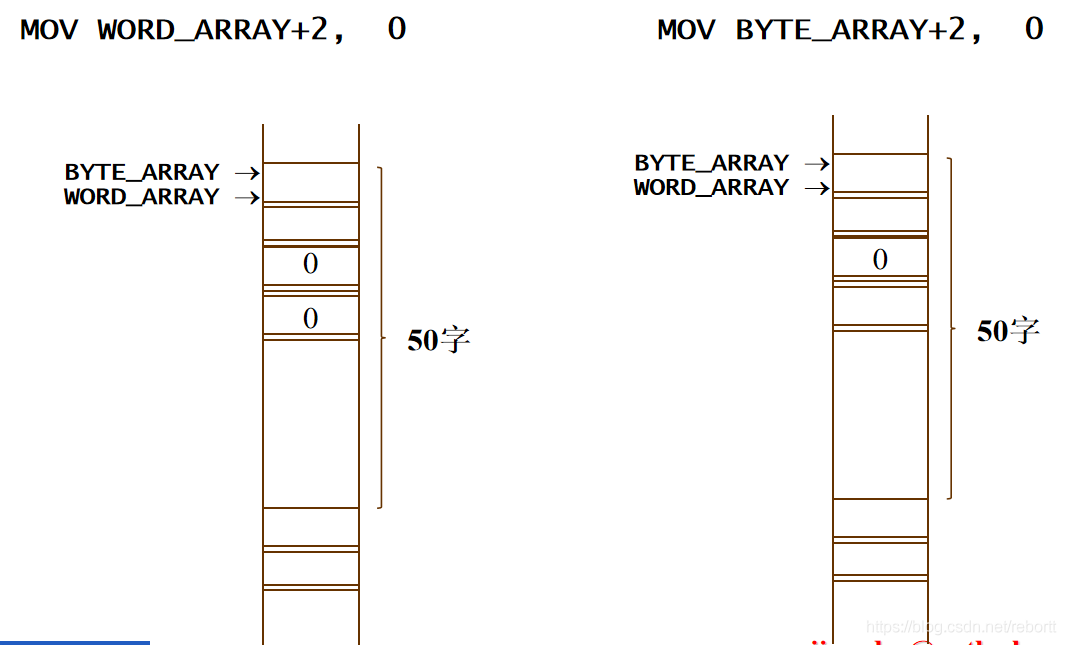
BYTE_ARRAY LABEL BYTE
这样赋值是没有分配内存的。
BYTE_ARRAY LABEL BYTE
WORD_ARRAY DW 50 DUP (?)
在内存中:

这时我们来看两个指令:
equ伪指令
表达式名 EQU 表达式
这样就将两者对等,类似于"=",但是还有所不同,这种方式不允许重复定义。
地址计数器
“$”:保存当前正在汇编的指令的偏移地址。
在指令中本指令的第一个字节的地址。
我们可以使用JNE $+6,转向当前地址+6(个字节)的位置。
在data段中表述地址计数器的当前值。
例:ARRAY DW 1, 2 , $+4 , 3 , 4 , $+4
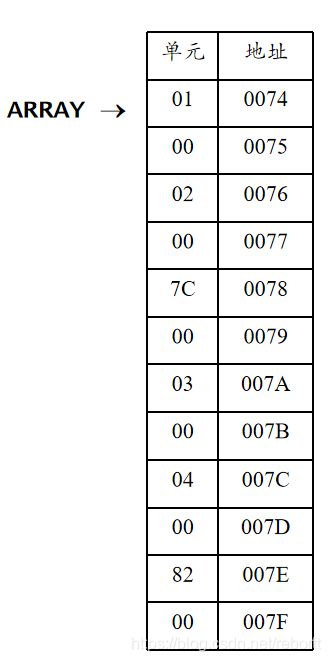
首先是前两个格为0001h,下两个是0002h,然后跳过四个字节,在007A赋值为0003h,然后是4。
我们可以使用org伪指令来设置地址计数器的值。
Buffer Label BYTE+ORG $+8 = Buffer DB 8 DUP(?)
基数控制
修改默认的进制,
.RADIX 16 表示修改为16进制。















 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









