







 本文介绍了如何使用Python通过12306官网API进行火车票查询。通过docopt库解析命令行参数,抓取指定日期、始发站和终点站的车次信息,并详细说明了获取数据的过程,包括网络请求的URL和解析JSON响应数据。同时,还提供了用于解析车站信息的Python脚本,以获取车站的代号。
本文介绍了如何使用Python通过12306官网API进行火车票查询。通过docopt库解析命令行参数,抓取指定日期、始发站和终点站的车次信息,并详细说明了获取数据的过程,包括网络请求的URL和解析JSON响应数据。同时,还提供了用于解析车站信息的Python脚本,以获取车站的代号。
这个小工具通过抓取12306网站提供的数据并进行解析,从而实现通过命令行的方式查询火车票余票数的功能。主要运用了docopt,requests,prettytable,colorama的库函数,达到简单熟悉Python3网络编程的目的。运行效果如下: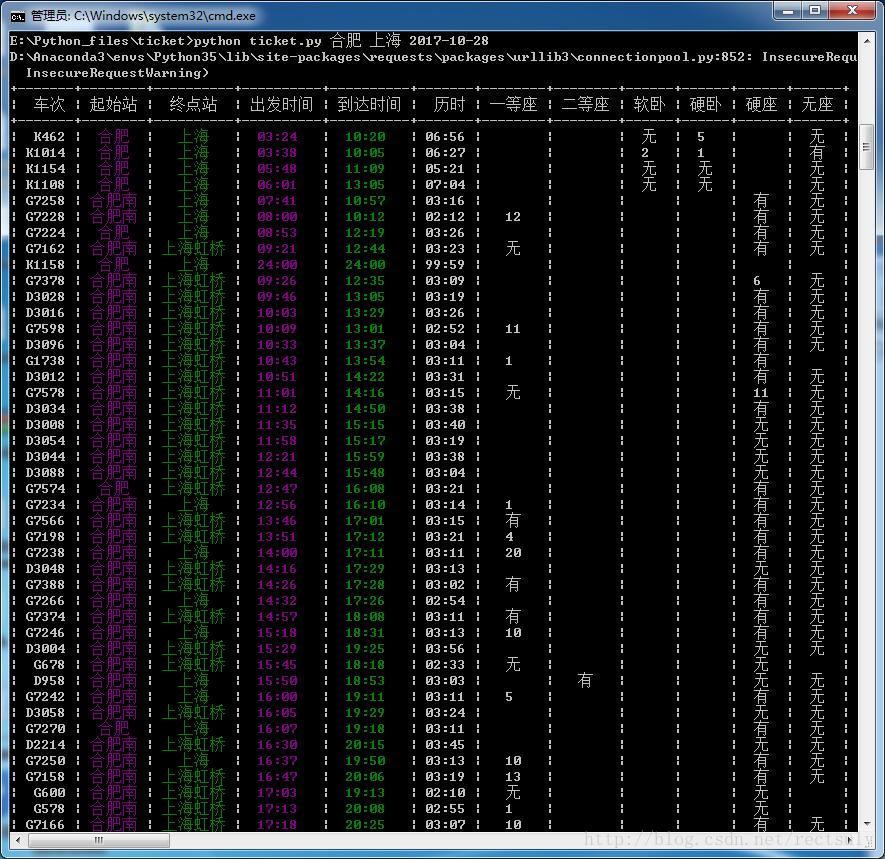
首先,我们用docopt这个库来解析Python的命令行参数,docopt可以按我们在文档字符串中定义的格式来解析参数,比如我们在代码中写下以下内容:
# coding: utf-8
"""命令行火车票查看器
Usage:
tickets [-gdtkz] <from> <to> <date>
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 北京 上海 2017-10-22
tickets -dg 成都 南京 2017-10-22
"""
from docopt import docopt
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
print(arguments)
if __name__ == '__main__':
cli()接下来是获取数据,让我们先打开12306的官网,进入余票查询页面,随便查询一次从北京到上海的车次,然后按F12打开开发者工具,选中Network一栏,在调试工具观察下请求和响应:

从图中可以很容易找到请求数据的URL:https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-10-23&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=BJP&purpose_codes=ADULT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1876
1876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









