










关于HyperLPR
HyperLPR是一个使用深度学习针对对中文车牌识别的实现,与较为流行的开源的EasyPR相比,它的检测速度和鲁棒性和多场景的适应性都要好于目前开源的EasyPR,HyperLPR可以识别多种中文车牌包括白牌,新能源车牌,使馆车牌,教练车牌,武警车牌等。
Github地址:https://github.com/zeusees/HyperLPR
前言
车牌识别是使用OCR来识别车牌的一种应用方式,车牌识别在国内经历了十年乃至二十年的发展,在文通,火眼臻睛等一些公司的努力下,中文车牌识别技术基本趋于成熟,基本在能强光,夜晚,光照不均匀,多姿态等恶劣情况下进行稳定的识别,其商业应用也相对比较广泛,从停车场到交通卡口,公司门禁都有涉及。车牌相比人脸,这个坑,效果好的项目至少在开源界并不是很多,EasyPR在这方面做出了做出了很大的贡献,一些成熟的车牌识别公司都有并不开源,甚至没有免费的SDK提供,所以我在课余时间思考和设计了这个开源项目,同时这个开源项目在不断开发的过程中也在帮助我也不断的在学习,后来在一些朋友的帮助下我决定将它的代码开源。
在这里不得的不感谢的是EasyPR这个中文的开源项目给了我很大的帮助和启发,在这里也要感谢EasyPR团队付出的无偿的努力和高质量博文。
HyperLPR使用了一套和EasyPR完全不同的Pipeline来完成车牌识别这个任务
设计流程介绍-粗定位
车牌定位的方法有很多种,在学术界它其实是属于场景文字检测的一种特定情况。
考虑到字符间垂直边缘比较密集,有基于边缘的方法。
考虑到字符个体间的特征,有基于个体字符特征发的方法
考虑到车牌这种共性特征比较强烈的目标 ,有基于目标检测的方法。
有学者对这些方法做了一一的评判。下表是这些方法的各个表现能力。不过由于每篇论文采用的数据集不同。其准确率并不能比较。
HyperLPR用了使用了基于目标检测的方法进行车牌粗定位,总体而言去得了不错的效果。
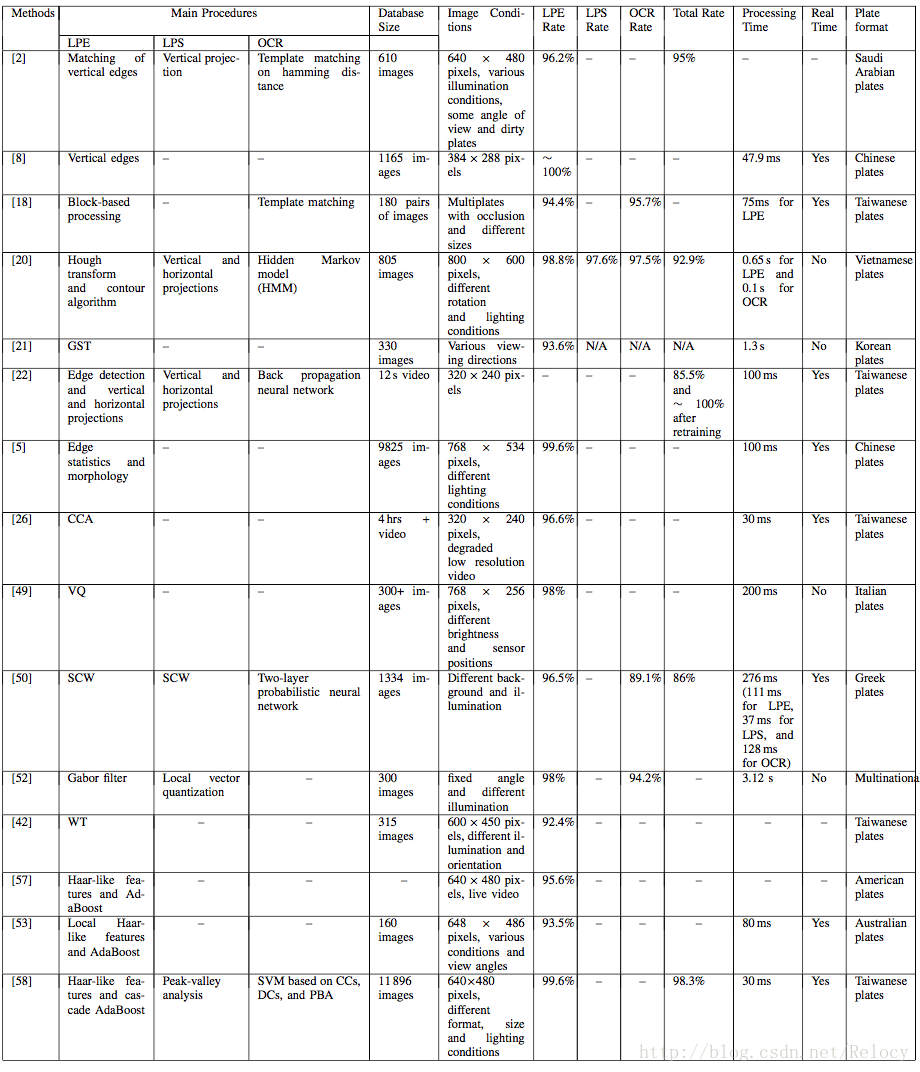
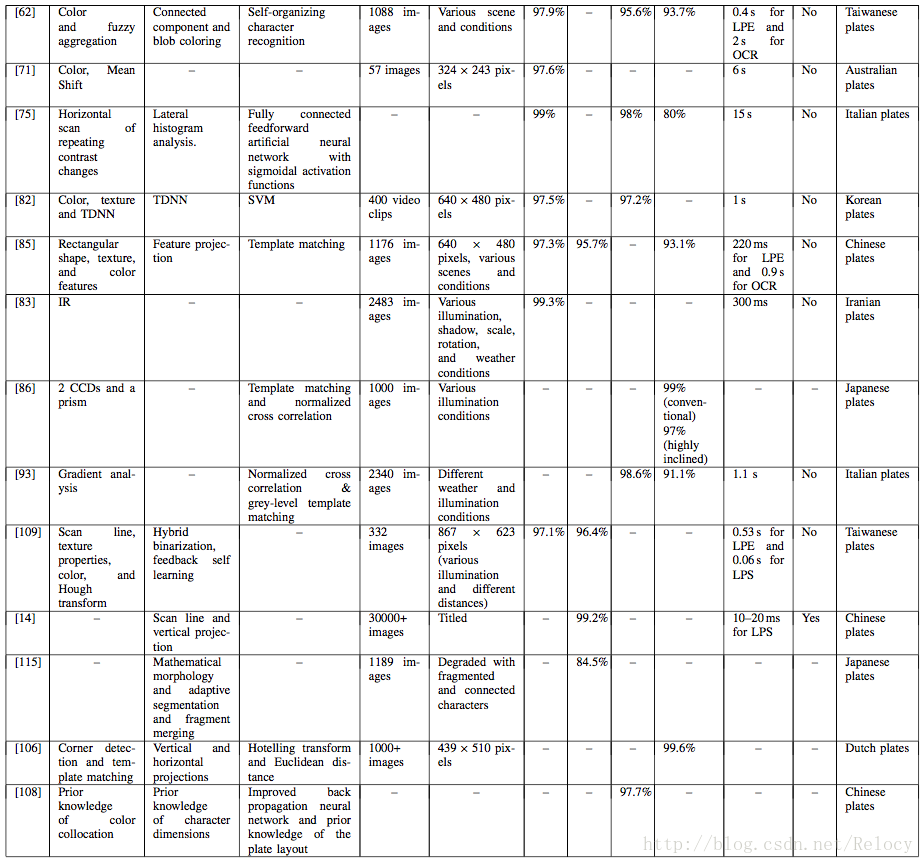
我们使用的目标检测器是基于OpenCV的Haar级联分类器。其速度也达到了不错的效果,对于移动端的大车牌基本可以实时定位。
我们使用了大概4700张正样本车牌车12000张负样本进行了分类器训练。
训练的方法
我们使用了OpenALPR的Train - Detector,来进行训练Opencv的Haar级联分类目标检测器。
正样本可以通过手动crop或者使用easypr或者hyperlpr的模块进行crop裁剪。
负样本在train detector目录下已经包含了一些基本的负样本,我们在多次训练后发现,使用这些负样本训练出来的检测器在垂直边缘密集的地方误检特别高。 这时候我们就要使用类似于Hard Sample Mining的策略 将这些部分的误检区域crop出来。加入到分类器中训练。
使用训练完的检测器
检测器的使用很简单。使用opencv中的cascadeclassifier进行多尺度检测即可。

数据分享和捐赠
车牌识别框架开发时使用的数据并不是很多,有意着可以为我们提供相关车牌数据。联系邮箱 455501914@qq.com。
如果您愿意支持我们持续对这个框架的开发,可以通过下面的链接来对我们捐赠。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









