







学习目标
- 了解单链表和双链表的结构;
- 在单链表或双链表中实现遍历、插入和删除;
- 分析在单链表或双链表中的各种操作的复杂度;
- 在链表中使用双指针技巧(快指针慢指针技巧);
- 解决一些经典问题,例如反转链表;
- 分析你设计的算法的复杂度;
- 积累设计和调试的经验。
1. 链表
链表是一种线性数据结构,它通过引用字段将所有分离的元素链接在一起。有两种常用的链表:单链表 和 双链表。
链表中的每个元素实际上都是一个单独的对象,而所有对象都通过每个元素中的引用字段链接在一起。
1.1 单链表
单链表中的每个结点不仅包含值,还包含链接到下一个结点的引用字段。通过这种方式,单链表将所有结点按顺序组织起来,如下:

蓝色箭头显示单个链接列表中的结点是如何组合在一起的。
结点结构
//以下是单链表中结点的典型定义:
public class SingListNode {
int val;
SingListNode next;
SingListNode(int x) { val = x; }
}
操作
与数组不同,我们无法在常量时间内访问单链表中的随机元素。如果我们想要获得第 i 个元素,我们必须从头结点逐个遍历。我们按索引来访问元素平均要花费0(N)时间,其中N是链表的长度。
例如,在上面的示例中,头结点是 23 。访问第3个结点的唯一方法是使用头结点中的"next"字段达到第 2 个结点(结点 6 ) ;然后使用结点 6 的"next"字段,我们能够访问第 3 个结点。
1.1.1 添加操作
如果我们想在给定的结点 prev 之后添加新值,我们应该:
1.使用给定值初始化新结点 cur;
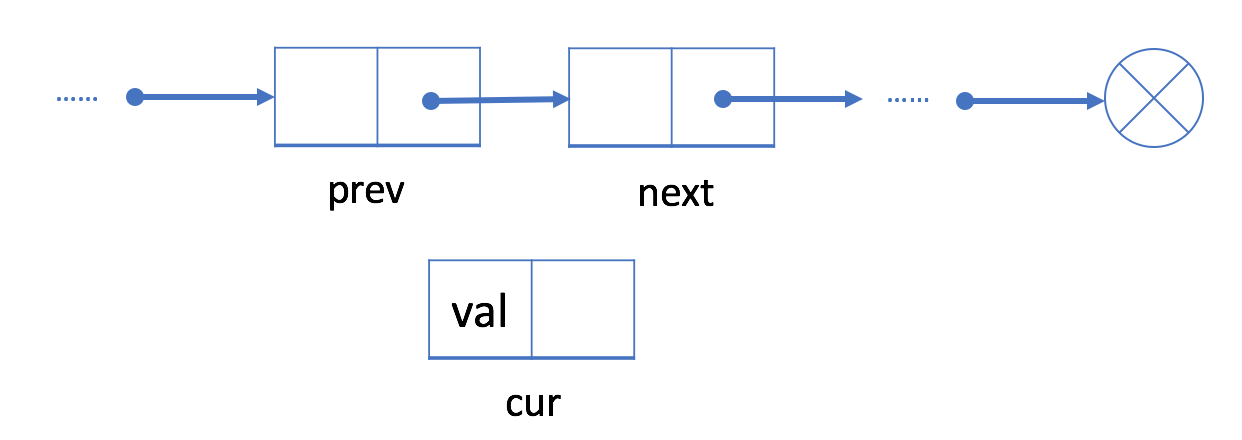
2.将 cur 的 next 字段链接到 prev 的下一个结点 next;
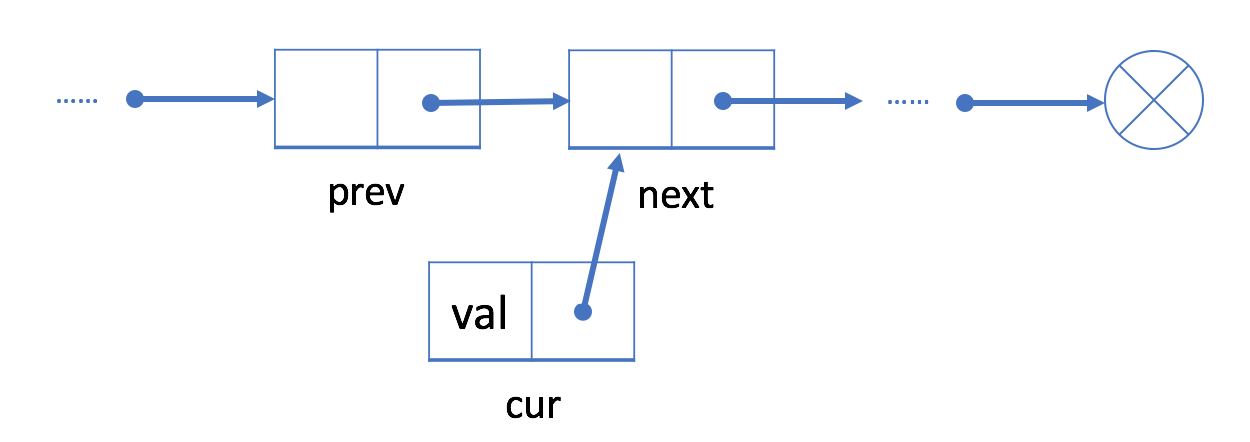
3.将 prev 中的 next 字段链接到 cur。
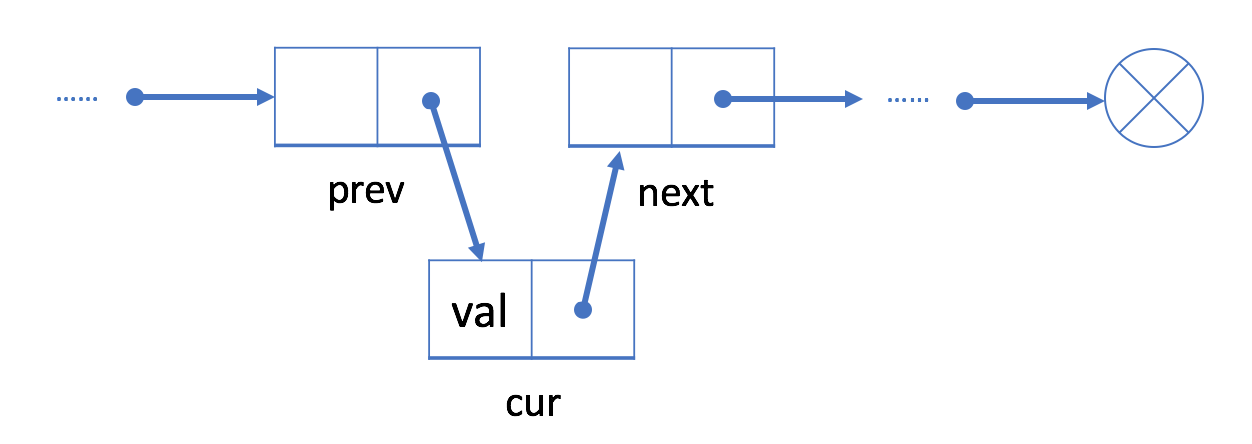
与数组不同,我们不需要将所有元素移动到插入元素之后。因此,您可以在 O(1)时间复杂度中将新结点插入到链表中,这非常高效。

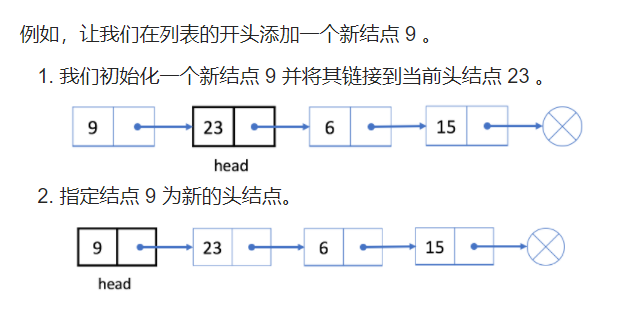
在开头添加结点
众所周知,我们使用头结点来代表整个列表。
因此,在列表开头添加新节点时更新头结点 head 至关重要。
- 初始化一个新结点 cur;
- 将新结点链接到我们的原始头结点 head。
- 将 cur 指定为 head。
1.1.2 删除操作
如果我们想从单链表中删除现有结点 cur ,可以分两步完成:
1.找到 cur 的上一个结点 prev 及下一个结点 next;

2.接下来链接到 prev 到 cur 的下一个节点 next。

在我们的第一步中,我们需要找出 prev 和 next。使用 cur 的参考字段很容易找出 next,但是,我们必须从头结点遍历链表,以找出 prev,它的平均时间似 O(N),其中 N 是链表的长度。incident,删除结点的时间复杂度将是 O(N)。
空间复杂度为 O(1),因为我们只需要常量空间来存储指针。
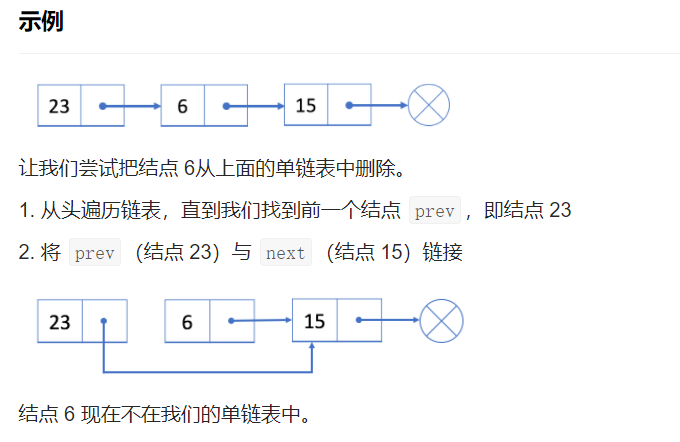
删除第一个结点

1.2 双链表
与单链表不同的是,双链表还有一个引用字段,称为 prev 字段。有了这个额外的字段,你就能够知道当前结点的前一个结点。

绿色箭头表示我们的 prev 字段是如何工作的。
结点结构
//双链表的定义
class DoublyListNode{
int val;
DoublyListNode next,prev;
DoublyListNode(int x) { }
}
操作
我们可以与单链表相同的方式访问数据:
- 我们不能在常量级时间内访问随机位置。
- 我们必须从头部遍历才能得到我们想要的第一个结点。
- 在最坏的情况下,时间复杂度将是O(N),其中 N 是链表的长度。
1.2.1 添加操作
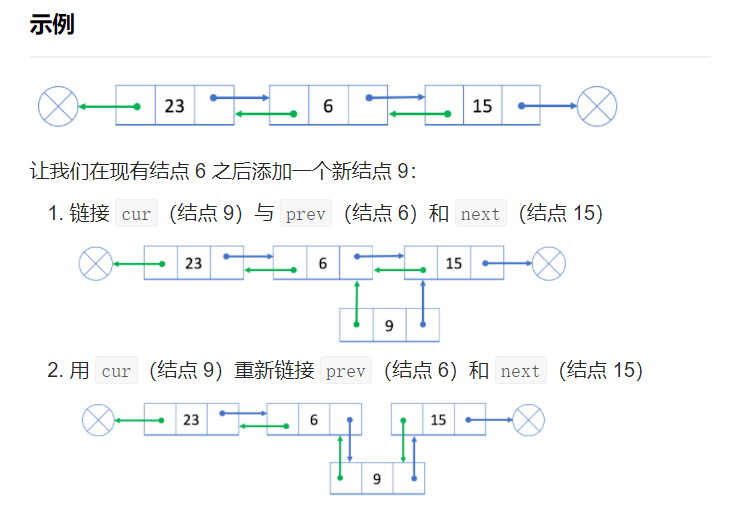
如果我们想在现有的结点 prev 之后插入一个新的结点 cur,我们可以将此过程分为两个步骤:
1.链接 cur 与 prev 和 next,其中 next 是 prev 原始的下一个节点;
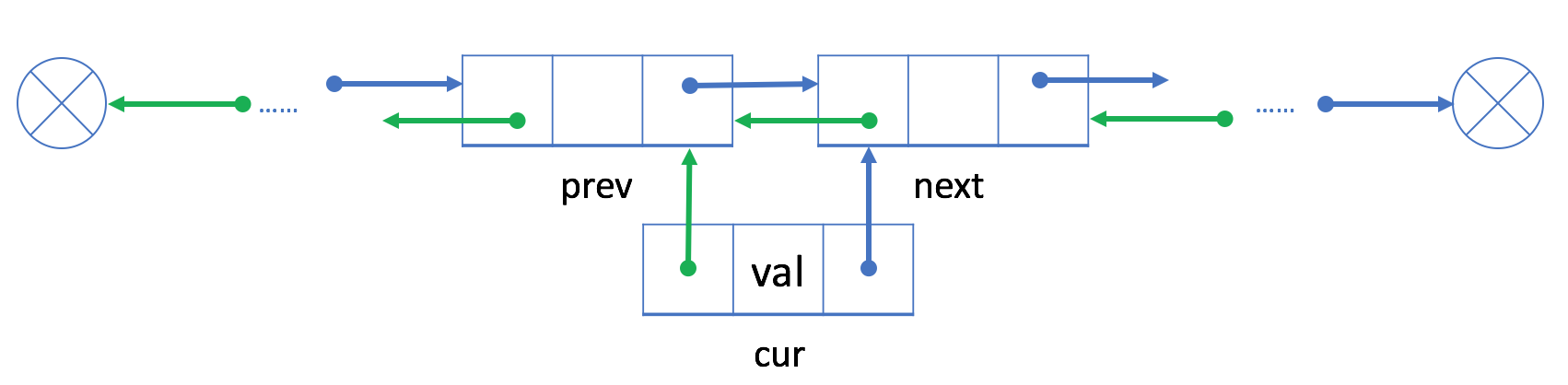
2.用 cur 重新链接 prev 和 next。
与单链表类似,添加操作的时间和空间复杂度都是 O(1)。
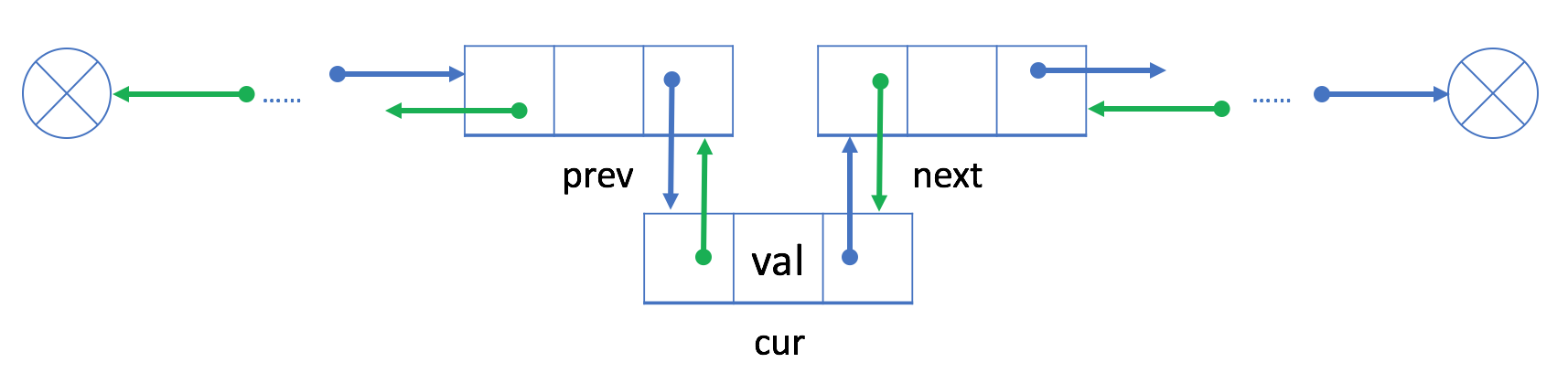
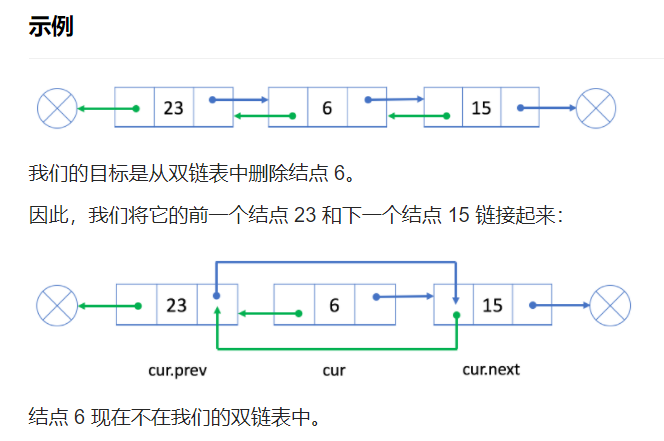
1.2.2 删除操作
如果我们想从双链表中删除一个现有的结点 cur,我们可以简单地将它的前一个结点 prev 与 下一个节点 next 链接起来。
与单链表不同,使用 "prev"字段可以很容易地在常量时间内获得前一个结点。
因为我们不再需要遍历链表来获取前一个结点,所以时间和空间复杂度都是O(1)。
2. 设计链表
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
- get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
- addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
- addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
- addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果
- index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
- deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
实例:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3
linkedList.get(1); //返回2
linkedList.deleteAtIndex(1); //现在链表是1-> 3
linkedList.get(1); //返回3
提示:
- 所有
val值都在[1, 1000]之内。 - 操作次数将在
[1, 1000]之内。 - 请不要使用内置的 LinkedList 库。
class MyLinkedList {
int size;
ListNode head; //作为伪头的哨兵节点
/** Initialize your data structure here. */
public MyLinkedList() {
size = 0;
head = new ListNode(0);
}
/** Get the value of the index-th node in the linked list. If the index is invalid, return -1. */
public int get(int index) {
//如果索引无效
if(index < 0 || index >= size) return -1;
ListNode curr = head;
//从sentinel节点移到所需节点的步骤
for(int i = 0;i<index+1;++i) curr = curr.next;
return curr.val;
}
/** Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list. */
public void addAtHead(int val) {
addAtIndex(0,val);
}
/** Append a node of value val to the last element of the linked list. */
public void addAtTail(int val) {
addAtIndex(size,val);
}
/** Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. */
public void addAtIndex(int index, int val) {
//如果索引大于长度,不会插入节点
if(index > size) return;
//如果索引为负,节点将插入列表的开头
if(index <0) index = 0;
++size;
//查找要添加的节点的前置节点
ListNode pred = head;
for(int i = 0; i < index; ++i) pred = pred.next;
//要添加的节点
ListNode toAdd = new ListNode(val);
//将它插入
toAdd.next = pred.next;
pred.next = toAdd;
}
/** Delete the index-th node in the linked list, if the index is valid. */
public void deleteAtIndex(int index) {
//如果索引无效,直接返回
if(index < 0 || index >= size ) return;
size --;
//查找要删除结点的前置节点
ListNode pred = head;
for(int i = 0; i < index; ++i) pred = pred.next;
//删除结点
pred.next = pred.next.next;
}
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList obj = new MyLinkedList();
* int param_1 = obj.get(index);
* obj.addAtHead(val);
* obj.addAtTail(val);
* obj.addAtIndex(index,val);
* obj.deleteAtIndex(index);
*/
3. 小结
双链表和单链表在许多操作中是相似的。
- 它们都无法在常量时间内随机访问数据。
- 它们都能够在O(1)时间内在给定结点之后或列表开头添加一个新结点。
- 它们都能够在O(1)时间内删除第一个结点。
但是删除给定结点(包括最后一个结点)时略有不同。
- 在单链表中,它无法获取给定结点的前一个结点,因此在删除给定结点之前我们必须花费O(N)时间来找出前一结点。
- 在双链表中,这会更容易,因为我们可以使用 "prev"引用字段获取前一个结点。因此我们可以在O(1)时间内删除给定结点。














 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









