






前言
技术的分类
解决功能性的问题
- Java、Jsp、RDBMS、Tomcat、HTML、Linux、Jdbc、SVN
解决扩展性的问题
- Struts、Spring、SpringMVC、Hibernate、Mybatis
解决性能的问题
- NoSQL、Java线程、Hadoop、Nginx、MQ、ElasticSearch
1、Web 1.0 的时代,数据访问量很有限,用一夫当关的高性能单点服务器可以解决大部分问题。
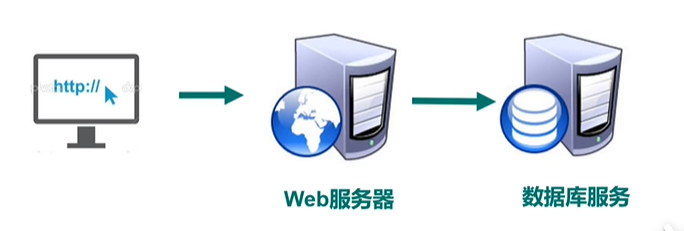
2、随着Web2.0的时代的到来,用户访问量大幅度提升,同时产生了大量的用户数据。加上后来的智能移动设备的普及,所有的互联网平台都面临了巨大的性能挑战。
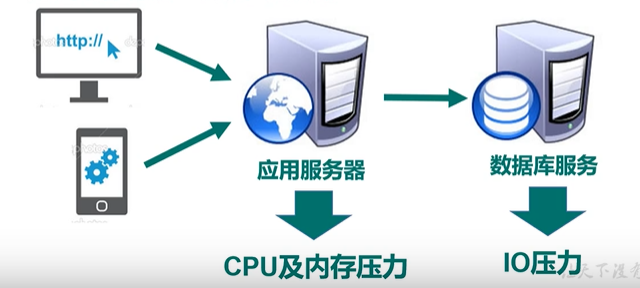
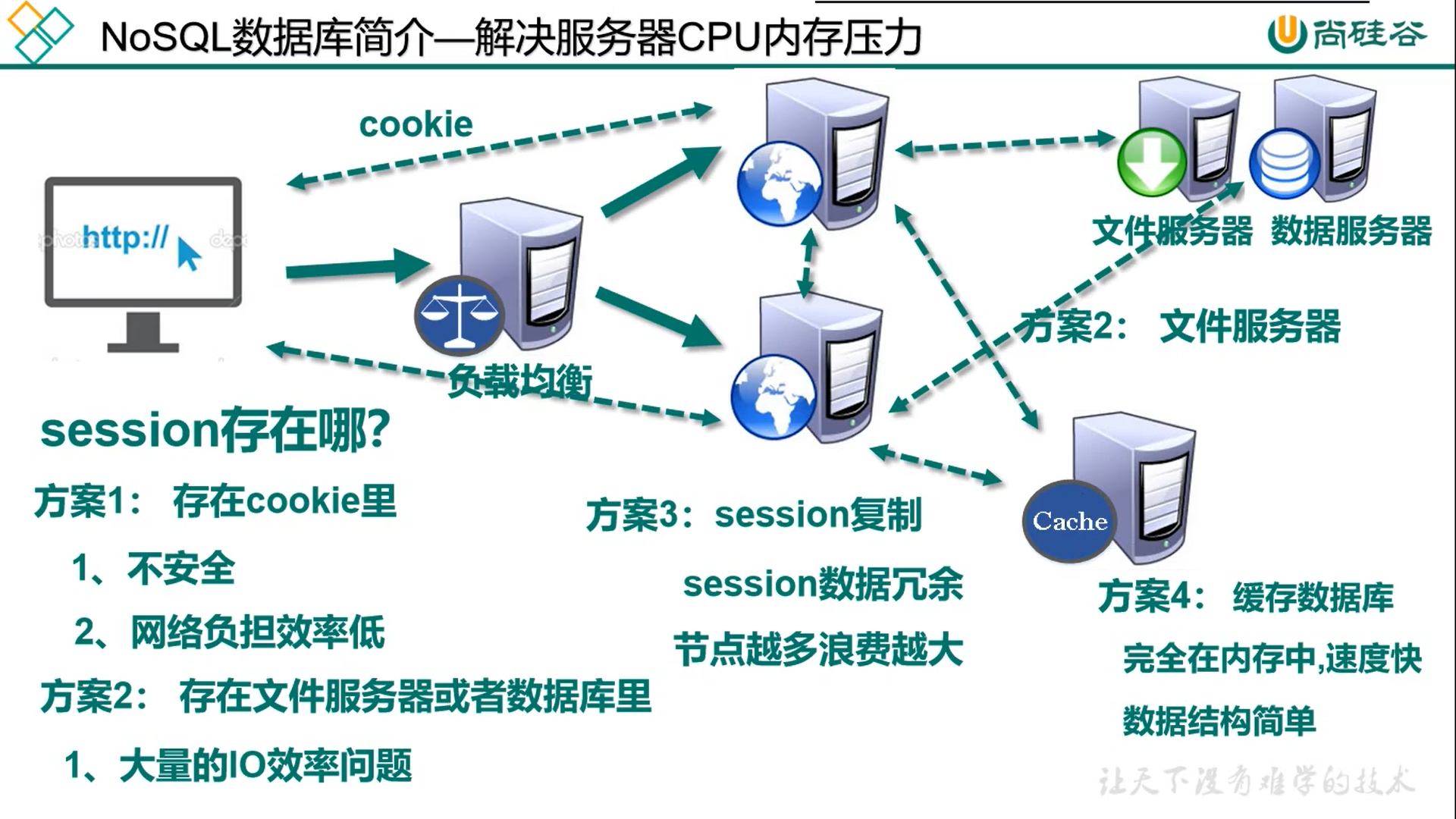
解决服务器的CPU内存压力
session存在缓存服务器中,缓存服务器主要把数据存在内存里面,可以增加读写效率。
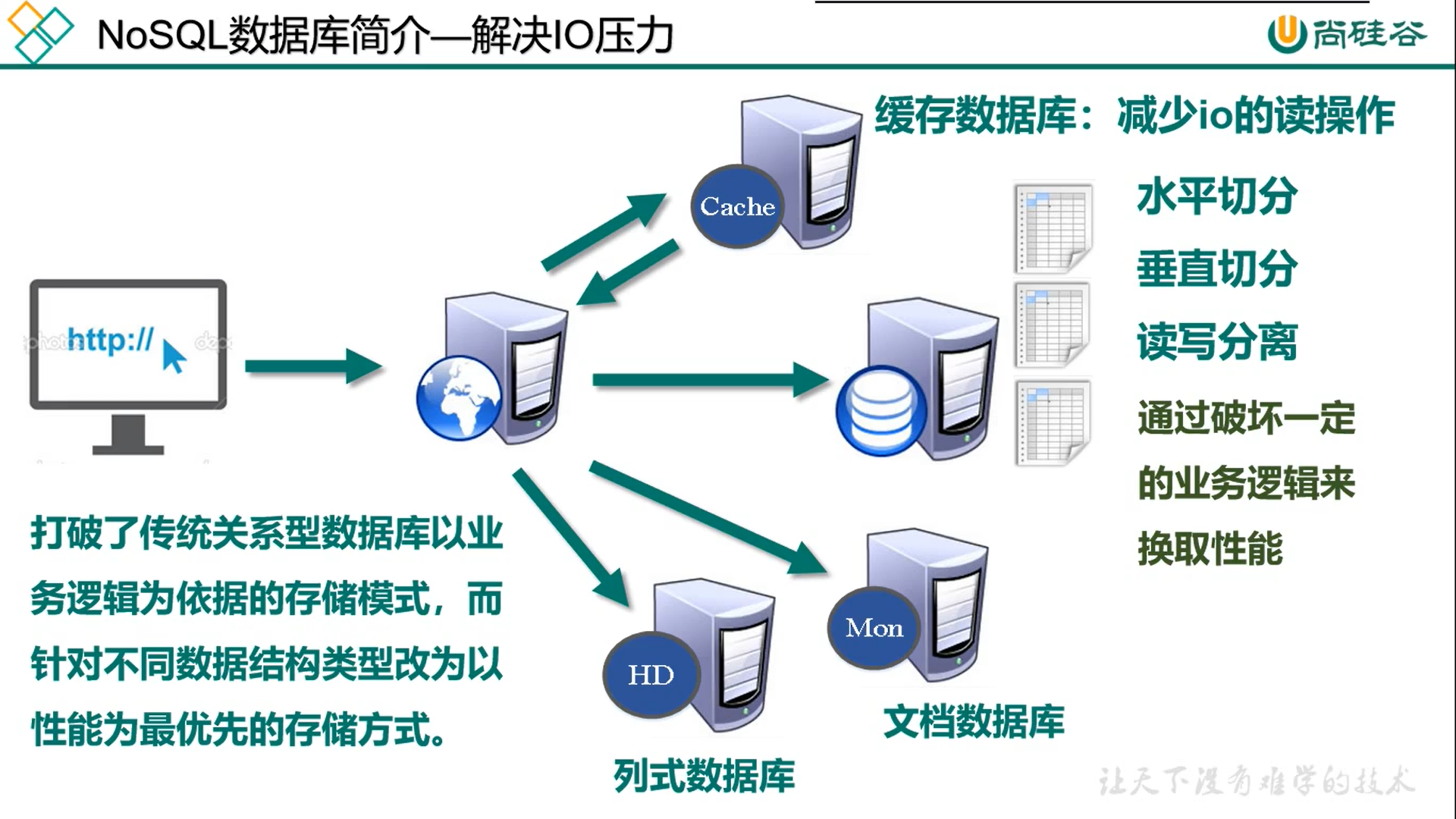
解决IO压力
1. NoSQL 数据库简介
1.1 NoSQL 数据库概述
-
NoSQL(NoSQL = Not Only SQL),意即"不仅仅是SQL",泛指非关系型的数据库。
-
NoSQL 不依赖业务逻辑方式存储,而以简单的 key-value 模式存储。
因此大大的增加了数据库的扩展能力。
-
不遵循SQL标准。
-
不支持ACID。
-
远超于SQL的性能。
1.2 NoSQL 适用场景
- 对数据高并发的读写
- 海量数据的读写
- 对数据高可扩展性的
1.3 NoSQL 不适用场景
- 需要事务支持
- 基于 sql的结构化查询存储,处理复杂的关系,需要即席查询。
用不着sql的和用了sql也不行的情况,请考虑用NoSql
2. 缓存数据库
2.1 Memcached
- 很早出现的 NoSql 数据库。
- 数据都在内存中,一般不持久化。
- 支持简单的 key-value 模式。
- 一般是作为 缓存数据库 辅助持久化的数据库。
2.2 Redis
- 几乎覆盖率 Memcached 的绝大部分功能。
- 数据都在内存中,支持持久化,主要用作备份恢复。
- 除了支持简单的 key-value 模式,还支持多种数据结构的存储,比如 String、list、set、hash、zset等。
- 一般是作为 缓存数据库 辅助持久化的数据库。
2.3 MongoDB
被称为最接近关系型数据库的非关系型数据库。
- 高性能、开源、模式自由(schema free)的 文档型数据库。
- 数据都在内存中,如果内存不足,MongoDB是一个环形队列,在往数据库存数据的时候会把数据放置在一个队列中,支持先进先出。最先进来的数据先被清除掉。
- 虽然是 key-value 模式,但是对 value(尤其是json)提供把不常用的数据保存到硬盘,丰富的查询功能。
- 支持二进制数据及大型对象。(比如能直接存图片)
- 可以根据数据的特点替代 RDBMS,成为独立的数据库。或者配合 RDBMS。
3. 列式数据库
行式数据库每次查询一行,列式数据库每次查询一列。
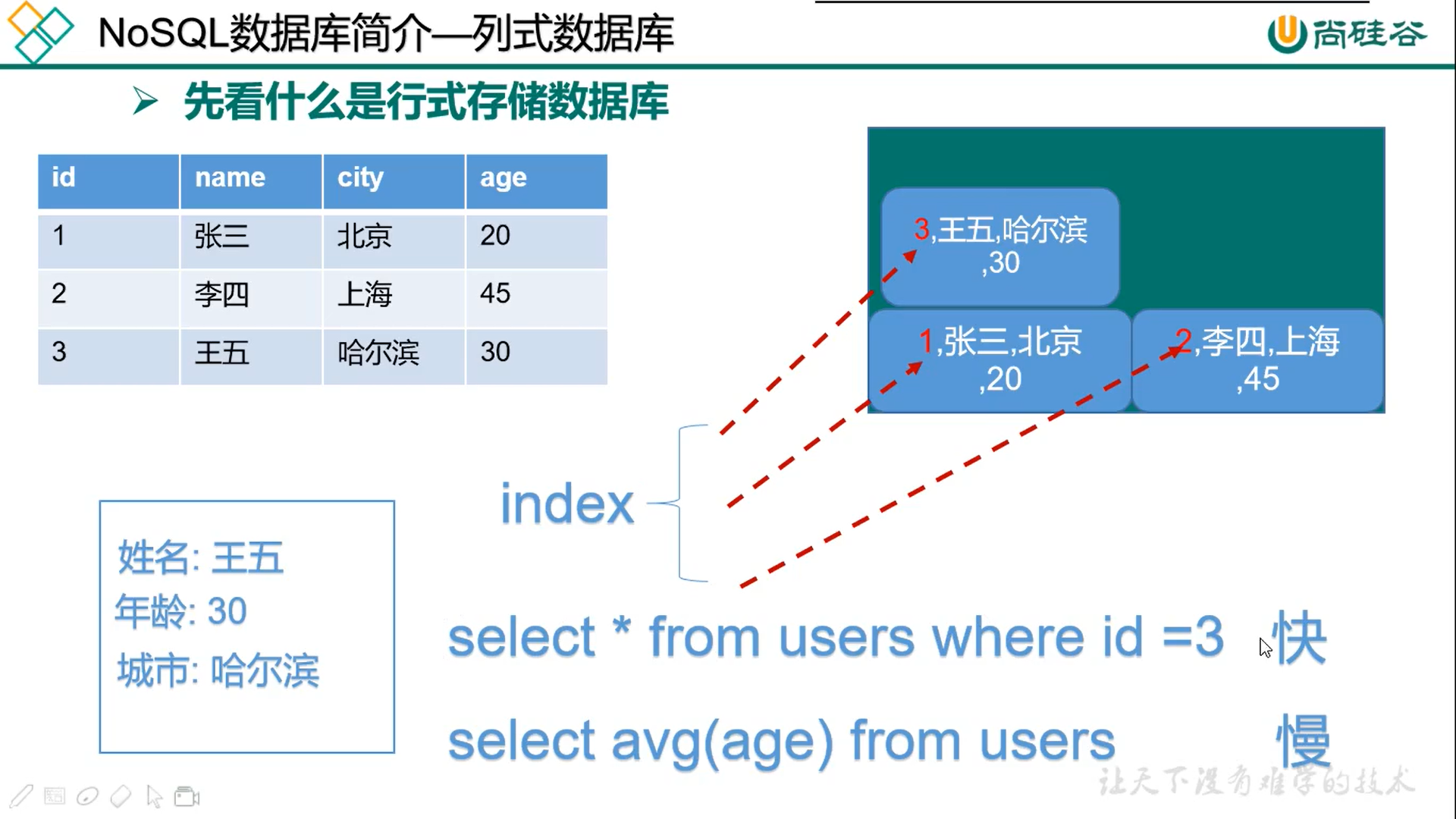
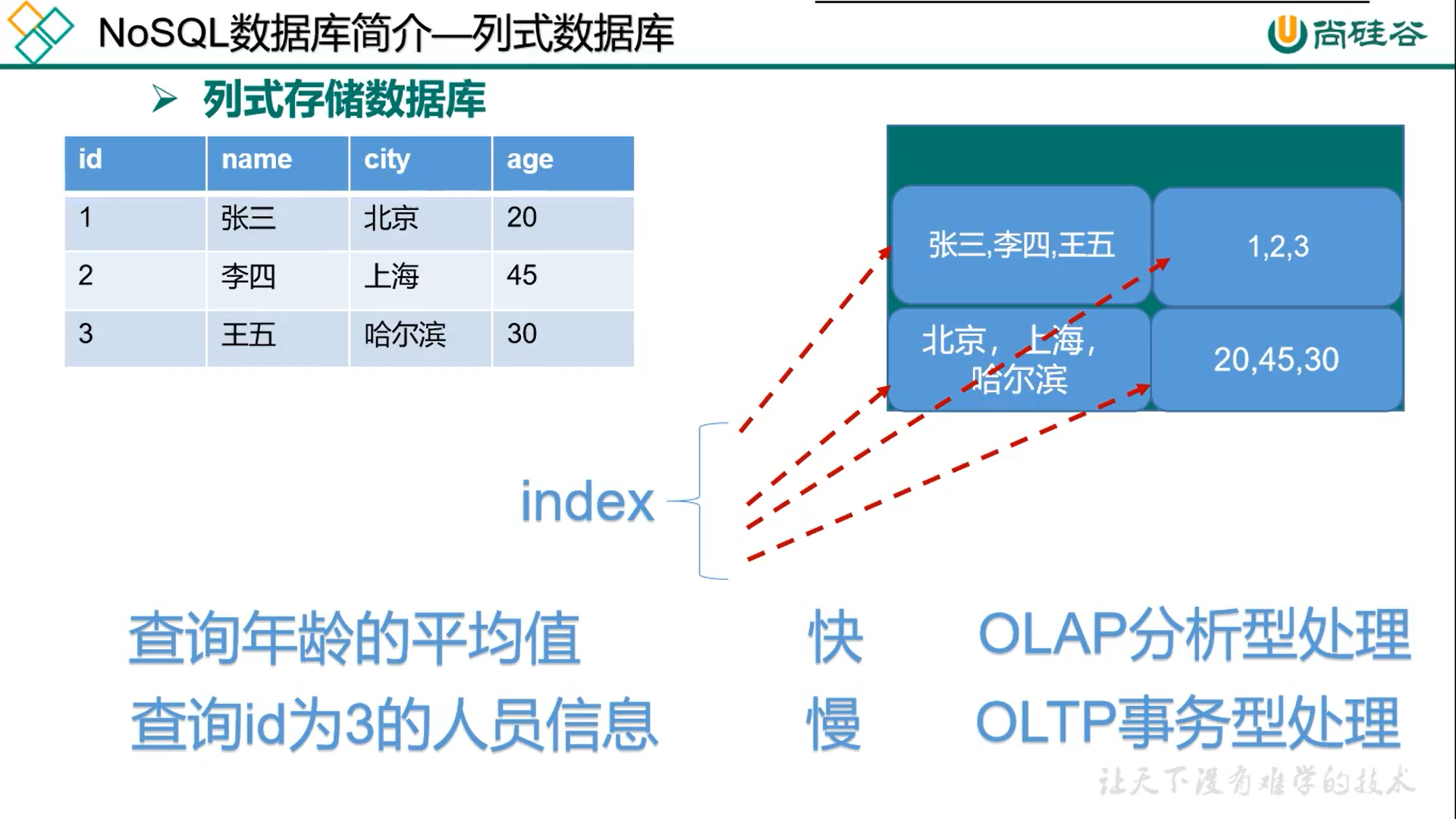
3.1 HBase
- HBase 是 Hadoop 项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。HBase 的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过 10 亿行数据,还可处理有数百万元素的数据表。
3.2 Cassandra
- Apache Cassandra 是一款免费的开源NoSQL 数据库,其设计目的在于管理由大量商用服务器构建起来的庞大集群上的 海量数据集(数据量通常达到 PB级别,大约等于1000个TB) 。在众多显著特性当中,Cassandra 最为卓越的长处是对写入及读取操作进行规模调整,而且其不强调主集群的设计思路能够以相对直观的方式简化各集群的创建与扩展流程。
4. 图关系数据库
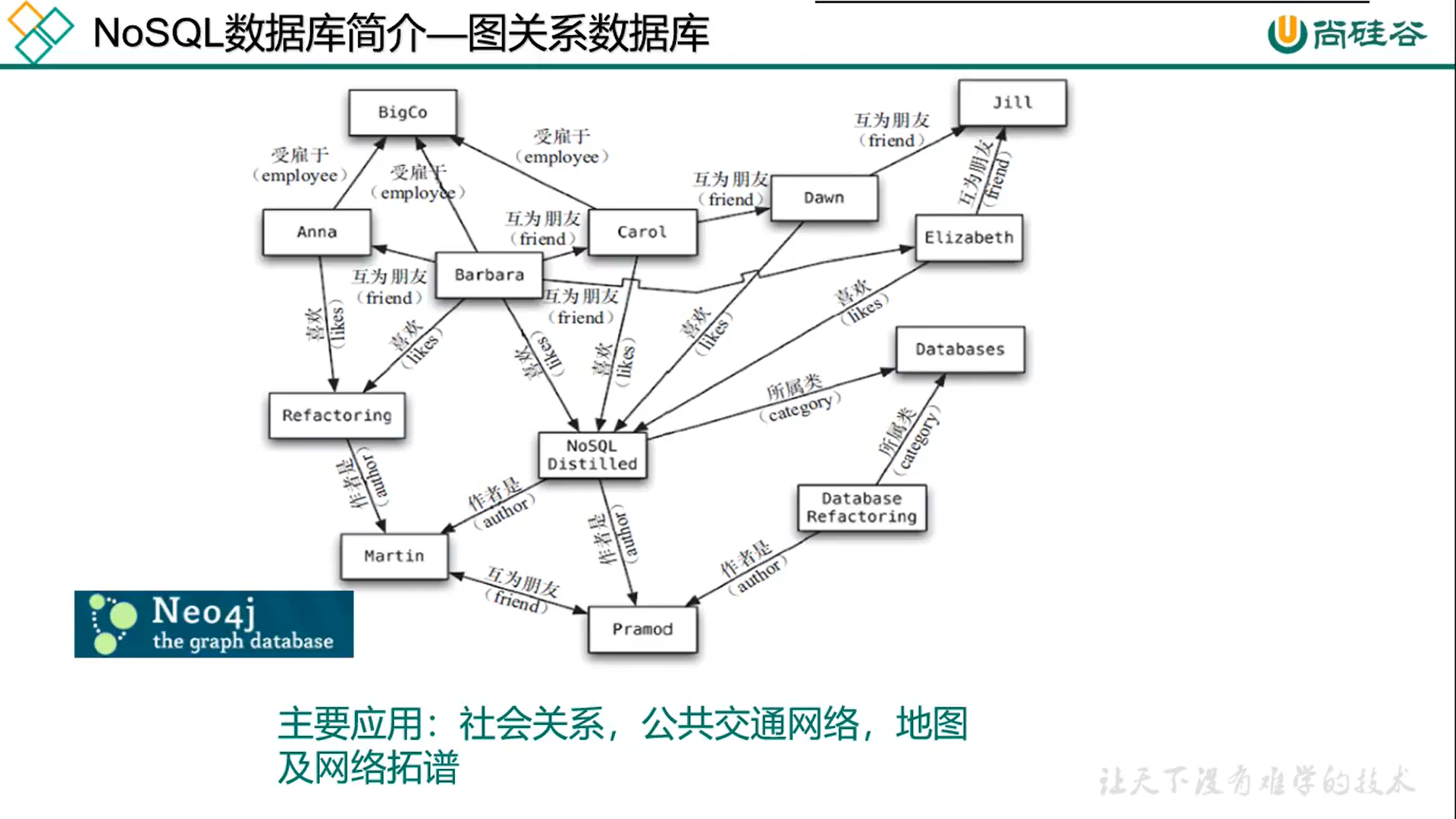















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









