






概述
HTTP协议是一种应用非常广泛的应用层协议.我们日常使用的搜索引擎,就是借助HTTP协议来传输数据的.
抓包工具
为了了解HTTP协议请求和响应的内部结构,我们需要在网络传输中将它们捕获,这就需要用到抓包工具.笔者使用的是Fiddler.
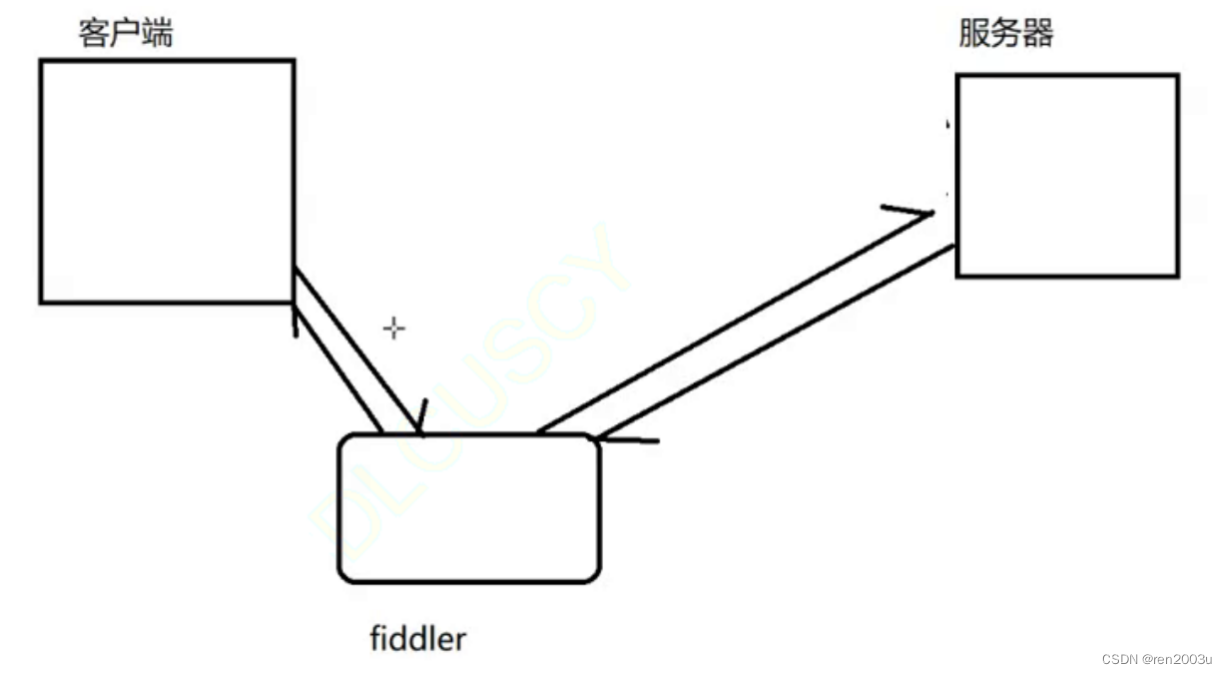
Fiddler相当于一个代理,当浏览器通过url访问目标服务器时,不再直接向目标服务器发送请求,而是改为向Fiddler发送,再由Fiddler将请求转发给目标服务器.同样的,当目标服务器处理完请求返回响应时,也不是直接返回给浏览器(客户端),而是先发给Fiddler,再由Fiddler转发给客户端.(这种过程与"中间人攻击"相类似,后者我们会在后面讲到)由此Fiddler就能获得请求和响应的具体内容.图示如下:
HTTP请求
我们以访问b站为例,来分析其HTTP请求的报文结构.其报文内容如下:
GET https://www.bilibili.com/ HTTP/1.1
Host: www.bilibili.com
Connection: keep-alive
sec-ch-ua: "Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: buvid3=152B4688-F43C-6172-B8DF-61B5DE70DC2E58315infoc; b_nut=1663515558; i-wanna-go-back=-1; _uuid=64610ED32-9104F-6F8C-738C-D8B8362FC33158096infoc; buvid_fp_plain=undefined; DedeUserID=50995319; DedeUserID__ckMd5=6bc75f917182600b; rpdid=|(YYRmkR~uu0J'uYYJlulY|J; b_ut=5; hit-dyn-v2=1; nostalgia_conf=-1; LIVE_BUVID=AUTO3916635924052537; buvid4=C17D2DE1-EEC3-43EB-7CE9-0A2D4E82930059373-022091823-XlbirWgeNG0gDovnUOJ7%2FQ%3D%3D; CURRENT_QUALITY=0; fingerprint=264712f80d69491b690a39a41450f419; buvid_fp=264712f80d69491b690a39a41450f419; PVID=1; theme_style=light; SESSDATA=fecc8ea6%2C1681793335%2Cc60d0%2Aa1; bili_jct=401e4187351be13ca903a41e2bd06dde; sid=5ip2fnmo; CURRENT_FNVAL=4048; b_lsid=BB1618DF_183F42EC91E; innersign=0; bp_video_offset_50995319=719031590583271400
首行
HTTP请求中的第一行称为"首行",其由三部分组成,每部分由空格间隔开来.
GET https://www.bilibili.com/ HTTP/1.1第一部分"GET",我们称之为HTTP的方法(method).除GET之外,HTTP协议还内置了很多其他的方法.如"POST" "PUT" "HEAD"等等.但其中使用最普遍的还是"GET",其次是"POST".方法的作用在于明确一个HTTP请求的目的.但实际上,"GET"和"POST"并无本质上的区别.这部分会在后面详细讲到.
第二部分"https://www.bilibili.com/"是客户端要请求的服务器的域名.相当于服务器在网络上的位置.
第三部分"HTTP/1.1"是HTTP协议的版本号.不同的版本号,所支持的方法种类有所不同.比如"LINK"方法就只有1.0的HTTP协议版本才支持.1.1版本下不支持"LINK"方法.
响应报头(Header)
以下是响应报头部分:
响应报头是键值对的结构,通常来说每一行是一个键值对.每个键与值之间用冒号+一个空格分隔.
Host: www.bilibili.com
Connection: keep-alive
sec-ch-ua: "Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: buvid3=152B4688-F43C-6172-B8DF-61B5DE70DC2E58315infoc; b_nut=1663515558; i-wanna-go-back=-1; _uuid=64610ED32-9104F-6F8C-738C-D8B8362FC33158096infoc; buvid_fp_plain=undefined; DedeUserID=50995319; DedeUserID__ckMd5=6bc75f917182600b; rpdid=|(YYRmkR~uu0J'uYYJlulY|J; b_ut=5; hit-dyn-v2=1; nostalgia_conf=-1; LIVE_BUVID=AUTO3916635924052537; buvid4=C17D2DE1-EEC3-43EB-7CE9-0A2D4E82930059373-022091823-XlbirWgeNG0gDovnUOJ7%2FQ%3D%3D; CURRENT_QUALITY=0; fingerprint=264712f80d69491b690a39a41450f419; buvid_fp=264712f80d69491b690a39a41450f419; PVID=1; theme_style=light; SESSDATA=fecc8ea6%2C1681793335%2Cc60d0%2Aa1; bili_jct=401e4187351be13ca903a41e2bd06dde; sid=5ip2fnmo; CURRENT_FNVAL=4048; b_lsid=BB1618DF_183F42EC91E; innersign=0; bp_video_offset_50995319=719031590583271400
Host
Host表示访问的服务器的网络地址是什么.这个信息在URL中同样是有体现的.
Content-Length 和 Content-Type
这两个属性在上述的请求报文中并没有出现.这是因为这两个属性是要在请求报文中有body部分的时候才会有的(通常方法为"POST").如下报文中就体现出了这两个属性:
POST https://beacons.gcp.gvt2.com/domainreliability/upload HTTP/1.1
Host: beacons.gcp.gvt2.com
Connection: keep-alive
Content-Length: 637
Content-Type: application/json; charset=utf-8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
{"entries":[{"failure_data":{"custom_error":"net::ERR_ABORTED"},"http_response_code":200,"network_changed":false,"protocol":"SPDY","request_age_ms":1118624,"request_elapsed_ms":71,"sample_rate":1.0,"server_ip":"","status":"aborted","url":"https://beacons.gcp.gvt2.com/domainreliability/upload","was_proxied":false},{"failure_data":{"custom_error":"net::ERR_ABORTED"},"http_response_code":200,"network_changed":false,"protocol":"HTTP","request_age_ms":61713,"request_elapsed_ms":323,"sample_rate":1.0,"server_ip":"","status":"aborted","url":"https://beacons.gcp.gvt2.com/domainreliability/upload","was_proxied":true}],"reporter":"chrome"}在这个"POST"请求的报头中,我们就可以看到有Content-Length和Content-Type这两个属性.其中Content-Length体现的是body部分的长度,这个属性的作用在于显示的指出了body在哪结束.如果没有Content-Length的话,则需要规定分隔符(如换行).而Content-Type则体现了body内的数据格式.上图中的数据格式是大家熟悉的json.
User-Agent(UA)
回到访问b站的数据请求报文.我们可以看到这样一行:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36这对键值对展示了客户端所使用的操作系统和浏览器的版本.其中"Windows NT 10.0; Win64; x64"表明了客户端是win10的64位系统."Chrome/106.0.0.0"则表明了客户端所用的浏览器版本."AppleWebKit/537.36"则表明了客户端所用的浏览器内核.
简单来说,UA的作用是告诉服务器我们在用一台什么样的设备访问它,从而根据客户端版本的新老返回不同的页面,服务更广泛的用户.但是随着网页兼容性的增强,UA现在的作用主要是区分访问设备是PC端还是移动端(根据操作系统内核判断),而不再是上述所说的了.
Referer
这个键值对表示了当前页面是从哪个页面跳转而来.并不是每个HTTP请求中都有Referer这一项,上述访问b站的HTTP请求就没有.我们抓一个有的,截取如下:
Referer: http://fiddler2.com/client/TELE/5.0.20211.51073这是启动Fiddler时,截取自Fiddler自己发送的HTTP请求中的Referer.
Referer在实际中主要用于广告计费.很多公司或企业会在各大浏览器投放自己品牌的广告,支付一定量的广告费来换取知名度.而计算广告费就需要使用Referer.以百度为例,每当客户在百度的搜索界面点击了某一个广告,百度自己会记录该次点击.而广告商会根据Referer所对应的搜索引擎,同样进行计数(因为广告商可能同时在很多不同的浏览器上投放广告).最后将两个计数的数值进行比较,从而结算广告费.
早期的"运营商劫持",就有一种是通过篡改Referer来达到非法盈利的目的.但是这种行为在HTTPS协议问世后得到了限制.这里不再展开.
Cookie
Cookie是浏览器在本地存储数据的一种机制.通常来说,一个用户的相关数据信息都是在服务器端存储的.但是有些时候出于便捷考虑,我们希望也能在浏览器端这边也能存储一些数据.最典型的,就是用户的身份信息.
然而,浏览器为了保证用户的信息安全.在代码层面做出了诸多限制,最典型的就是禁止浏览器页面代码读取用户的本地磁盘.这是很有必要的,否则但凡点开一个恶意的页面,就可能导致本地磁盘数据的丢失.
为了平衡便捷与安全,浏览器做了某种程度上的"退让".不再是百分之百禁止使用磁盘,而是允许在限制条件下访问部分数据.此外,浏览器还限制了页面代码对获得的数据的存储方式----只能以键值对形式存储.所存储的这些键值对,我们就称之为Cookie.
我们可以直接在浏览器页面上找到Cookie.以Chrome浏览器为例,其页面左上方有一个锁头标志.

点击后会出现如下页面:

从这我们就能看到当前网页中的所有Cookie了.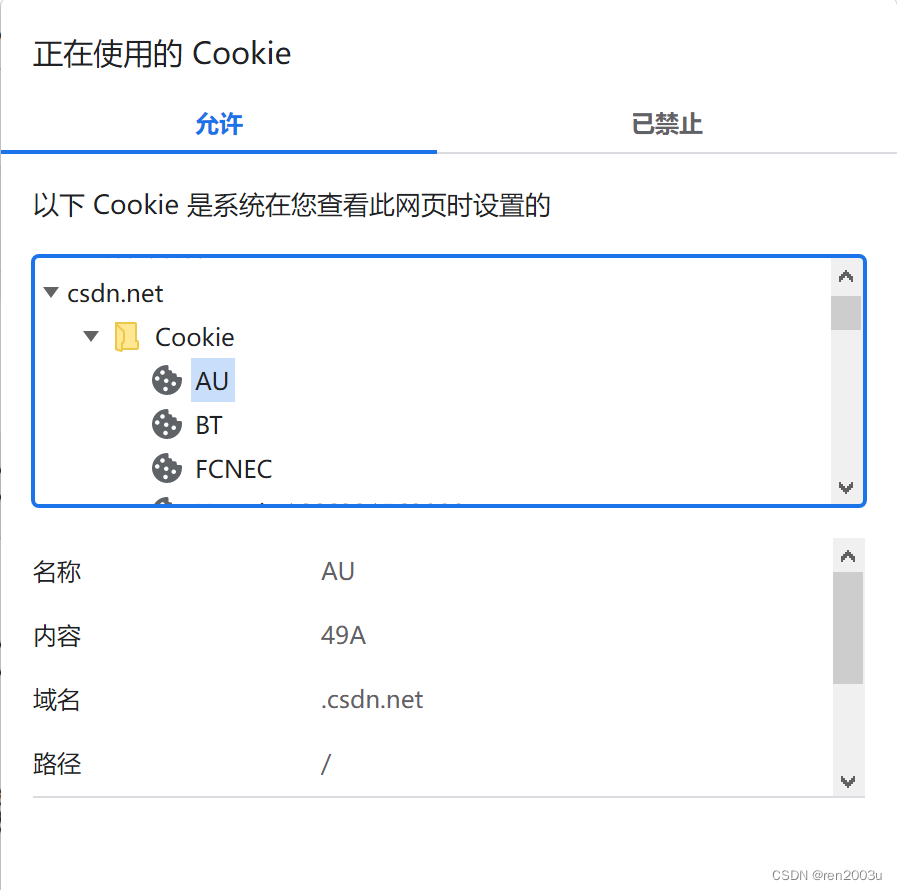
这其中,"名称"是键值对的"键".而"内容"是键值对的"值".键值对的含义通常只有开发者才知道.
我们假如把用户的磁盘的内容比作一个大房间.那么Cookie所占的部分可以当成一个小鞋柜.浏览器页面无法操作除了这个小鞋柜以外的磁盘资源.更重要的是,我们还依照域名将小鞋柜划分成不同的格子,不同域名下的Cookie是独立开来的,不能互相访问与修改.
我们已经明确了Cookie是浏览器允许页面在本地持久化存储数据的一种机制.我们还需要明确的是Cookie的内容从哪里来,又到哪里去.
由于用户的数据通常是存储在服务器上的,所以我们很自然的想到.Cookie的数据也是来源于服务器.当用户第一次访问某个服务器时,服务器在返回响应时,响应报文中会有"Set-Cookie"这样的键值对.这就是服务器在把某些数据传输给浏览器,浏览器会将"Set-Cookie"中的键值对以Cookie的形式存储在本地.下次在访问这个服务器时就可以直接把Cookie中的内容带上,从而能更容易的完成身份验证等工作.
我们举一个具体的例子来阐明这个过程:
以访问码云为例,我们先在码云的登陆界面删除掉所有的Cookie.然后登陆码云,所获得的HTTP请求是这样的:

我们观察可以发现上述HTTP报头中并没有Cookie这一项.
然后再来看看服务器发回的响应(仅截取部分):
可以看到有Set-Cookie这样的键值对.这就是在把数据传输给服务器.
当我们再次登录时,HTTP请求中就会带上上述服务器传过来的键值对了.如下:

对比键值对内容可以发现.Cookie中的键值对与Set-Cookie中的键值对的内容是完全一致的.这就阐明了Cookie机制的来龙去脉.
空行
空行,如其名.就是简单的空白行而已.其作用是将HTTP请求和响应的报头和正文部分间隔开来.否则报头的边界没有明确的定义,无法解析.
正文(Body)
首先需要明确的一点是,并不是所有HTTP的请求都有正文.通常以POST方法开头的HTTP请求有正文部分.试举一例:
POST https://beacons.gcp.gvt2.com/domainreliability/upload HTTP/1.1
Host: beacons.gcp.gvt2.com
Connection: keep-alive
Content-Length: 637
Content-Type: application/json; charset=utf-8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
{"entries":[{"failure_data":{"custom_error":"net::ERR_ABORTED"},"http_response_code":200,"network_changed":false,"protocol":"SPDY","request_age_ms":1118624,"request_elapsed_ms":71,"sample_rate":1.0,"server_ip":"","status":"aborted","url":"https://beacons.gcp.gvt2.com/domainreliability/upload","was_proxied":false},{"failure_data":{"custom_error":"net::ERR_ABORTED"},"http_response_code":200,"network_changed":false,"protocol":"HTTP","request_age_ms":61713,"request_elapsed_ms":323,"sample_rate":1.0,"server_ip":"","status":"aborted","url":"https://beacons.gcp.gvt2.com/domainreliability/upload","was_proxied":true}],"reporter":"chrome"}此处可以注意到"Accept-Language"这个键值对下空了一行.然后又有新的内容,这部分内容就是正文(Body).此处body的内容是一些json格式的数据.但body中不仅可以是json,还可以是css,js,HTML等等.HTTP请求中body的内容一般是一些简单键值对,而响应中body的内容就多种多样,可以是一个完整的前端页面,也可以是一些简单数据.
请求的构造
最简单也最基础的方式是直接在浏览器中输入URL,这就构建出了GET请求.而基于代码构造HTTP请求主要有两种方式:1.基于form标签 2.基于ajax
form标签
使用form标签构造简单HTTP的请求的代码如下:
<form action="https://www.sogou.com" method="get">
<input type="text" name="username">
<input type="submit">
</form>对于form标签,action属性表示该HTTP请求要访问的服务器域名.而method属性则表示构造出的HTTP请求所用的方法是什么.此处构造的是GET方法.
在form标签内部中,第一个input的作用是构造query string参数.第二个input的作用是提交HTTP请求至服务器.如图:
当我们点击提交按钮后,页面会跳转至搜狗主页.

观察url一栏我们可以看见:
https://www.sogou.com/?username=123"?"往后就是query string的内容.此处只有一组参数(因为我们代码中只写了一组).其中username就是我们第一个input标签name属性中的值.而"123"则是我们上面输入的内容.
实际上,我们可以在submit按钮之前加入任意个input标签.每个标签最后都会成为query string中的一组参数.他们之间用"&"间隔开来.比如这样:![]()
此外需要注意的是,form标签仅支持GET和POST方法.对于其他HTTP协议下的方法,form标签是不支持的.这就造成了一定的局限性.
ajax
ajax全称"asynchronous javascript and xml".表面上看起来只能传输xml格式的数据,但实际上ajax能传输其他任何常见格式的数据.
"asynchronous"意为异步.异步的含义是,当客户端给服务器发送请求时,无需自己获取结果,只需等待服务器返回响应即可.
ajax是浏览器给JS提供的一个和服务器交互数据的机制.为此,浏览器提供了一组特定的API,称之为XMLHttpRequest.但是XMLHttpRequest使用起来非常不方便,所以,JS有很多第三方库对XMLHttpRequest进行了封装.其中最典型的就是jQuery.
我们通常有两种方法将引入jQuery库.
第一.直接在script标签中引入网络路径.

这种方法虽然简单,但是有一个缺陷.这个缺陷在于jQuery库是存储在国外的服务器上的.有些时候出于某些特殊原因,有可能访问不到jQuery,这就存在隐患.
第二.将jQuery库整体拷贝到本地.我们可以在本地创建一个JS文件,然后将jQuery中的所有内容直接拷贝进去.这样就可以在本地直接访问,不存在网络访问不到的问题.

这里需要注意的是,此处的jQuery代码是经过特殊压缩处理的.所以只有一行.
引入jQuery库之后,我们就可以使用ajax构造HTTP请求了.构造形式如下:
<script src="jquery.min.js"></script>
<script>
$.ajax({
type:'GET',
url:'http://www.baidu.com',
//data:'data对应的是正文(body)中的内容,此处没有'
success:function(response){
//此处的函数参数response表示HTTP响应的 正文部分
//而此处的function则是一个回调函数 该函数什么时候被调用取决于
//服务器什么时候返回响应
}
});
</script>如上就是通过ajax构造HTTP请求的方法.但是如果仅仅只是这样写的话,是无法访问到百度主页的.会报出如下错误,我们可以在控制台中看到:

这个报错是ajax中的典型问题----"跨域"问题.
我们可以注意到当前网页的域名为:
file:///C:/Users/86136/Desktop/http/test.html这是一个本地路径.而ajax访问的是百度的服务器,这种行为称为"跨域访问".而浏览器为了保证网络安全,禁止了ajax的跨域访问.要想访问百度的服务器,需要百度允许才行.
响应
首行
同样以b站返回的响应为例.其响应中的首行如下:
HTTP/1.1 200 OK与请求中的首行类似,响应中的首行被空格分成了三个部分.
"HTTP/1.1".这部分与请求中一致,表示HTTP协议的版本号
"200".表示状态码
"OK".表示状态码描述.
其中状态码和状态码描述是一组的.而"200 OK"是最常见的一组,表示访问成功.
除此之外,还有一些其他的状态码和状态码描述.罗列如下:
"404 Not Found".表示"没有找到资源".当我们输入的URL所对应的资源不存在时,就会返回这组数据.
"403 Forbidden".表示"没有权限访问".通常出现于在没有登录的情况下访问某个需要登录的网页.
"504 Gateway Timeout".表示"访问超时".通常出现于服务器负载比较大或者被墙的时候.这种情况下,服务器处理单条请求的时候消耗的时间会很长,就会出现超时.
除了上述罗列的三种状态码与描述之外,还有很多其他的.但限于篇幅,不展开阐述.
响应报头
与请求中的报头一致,参上.
空行
与请求中的空行格式与作用都一致,参上.
响应正文
上面提到响应正文可以是一个完整的前端页面.这里展示b站服务器发回的HTTP响应中的正文部分:
此处只是局部,实际上还有JS代码部分等等.限于篇幅不再展示.














 2992
2992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









