







 本文详细介绍了SQL的四个主要部分:DDL(数据定义语言)、DML(数据操作语言)、DCL(数据控制语言)和DQL(数据查询语言),涵盖了创建、修改、权限管理和数据查询等方面,以及外连接、子查询的使用实例和SQL语句执行顺序。
本文详细介绍了SQL的四个主要部分:DDL(数据定义语言)、DML(数据操作语言)、DCL(数据控制语言)和DQL(数据查询语言),涵盖了创建、修改、权限管理和数据查询等方面,以及外连接、子查询的使用实例和SQL语句执行顺序。
结构化查询语言SQL
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;
SQL的种类
结构化查询语言SQL包含DDL、DML、DQL、DCL
1.数据定义语言 (DDL):
DDL(Data Definition Language)语句: 数据定义语言,主要是进行定义/改变表的结构、数据类型、表之间的链接等操作。常用的语句关键字有 CREATE、DROP、ALTER 等。
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE – 修改数据库表
DROP TABLE - 删除表
2.数据操作语言 (DML):
DML(Data Manipulation Language)语句: 数据操纵语言,主要是对数据进行增加、删除、修改操作。常用的语句关键字有 INSERT、UPDATE、DELETE 等。
INSERT INTO 表名 (字段1,字段2,...) values (某值,某值,...),(某值,某值,...);
UPDATE 表名 SET 列名=新值 WHERE 限定条件;
DELETE FROM 表名 WHERE 限定条件;
3.数据控制语言(DCL)(Data Control Language):
数据控制语言,主要是用来设置/更改数据库用户权限。常用关键字有 GRANT、REVOKE 等。一般人员很少用到DCL语句。
GRANT (授权)
REVOKE (取消权限)
4.数据查询语言(DQL):
DQL(Data Query Language)语句:数据查询语言,主要是对数据进行查询操作。常用关键字有 SELECT、FROM、WHERE 等。
SELECT 语句:
SELECT 列1 FROM 表1 WHERE 条件;
SELECT 可查询多个列,以逗号分隔:
SELECT 列1,列2 FROM 表1;
SELECT DISTINCT 去重查询:
SELECT DISTINCT(列1) FROM 表1;
SELECT语句对大小写不敏感,SELECT 等效于 select
WHERE 子句:
WHERE子句用于规定选择的标准,与运算符或操作符配合使用。
文本值使用单引号环绕,数值不需要使用引号。
SELECT 列1 FROM 表1 WHERE money = 1000 ;
SELECT 列2 FROM 表2 WHERE name =‘弘连’;
SELECT 列3 FROM 表3 WHERE paidmoney+money >= 10000 ;
WHERE 操作符—LIKE:
模糊查询,配合% ,_ 通配符使用
SELECT name FROM 表1 WHERE phone LIKE’%8888’;
SELECT name FROM 表2 WHERE ID LIKE ’______20021111____’;
WHERE 操作符—BETWEEN:
范围查询:between…and…
SELECT name FROM 表1 WHERE age BETWEEN 18 AND 35;
WHERE 子句——AND & OR:
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
SELECT name FROM 表1 WHERE age = 18 AND id = 230100200211110001;
SELECT age FROM 表1 WHERE id = 230201198502230002 OR name=‘张’ ;
WHERE 操作符—IN:
在 WHERE 子句中规定多个值
SELECT name FROM 表1 WHERE age IN (18,20,35);
ORDER BY语句:
ORDER BY 语句用于对结果集进行排序,ASC为升序,DESC为降序
SELECT * FROM 表1 ORDER BY age DESC;
聚合函数:
聚合函数可以操作多个符合条件的值,并返回一个单一值,常见的包括:
COUNT(列1) 返回列1非null行数 MAX(列4) 返回列4的最大值
SUM(列2) 返回列2数值总和 MIN(列5) 返回列5的最小值
AVG (列3) 返回列3数值平均值
GROUP BY语句:
GROUP BY 语句用于对结果集分组汇总
SELECT SUM(money) FROM 表1 GROUP BY userid;
常与HAVING连用,用于限定分组条件
HAVING语句:
作用于对GROUP BY分组后的结果,对输出做限制
SELECT GROUP_CONCAT(name),FROM 表1 GROUP BY age HAVING AVG(worktime) > 10
WHERE? OR HAVING?
WHERE作用于整列,HAVING作用于GROUP BY产生的组
WHERE在分组前过滤,HAVING在分组后过滤
WHERE后不能使用聚合函数,HAVING后可以使用
小结:
SELECT FROM WHERE GROUP BY HAVING ORDER BY
FROM子句:
FROM用于限定查询语句的数据来源。
笛卡尔积现象:
假设集合A={a, b},集合B={0, 1, 2},
select * from A, B
则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
规避笛卡尔集现象:
WHERE限定条件。通过这种方式,可以进行多表联查。
SELECT * FROM 表1,表2 WHERE 表1.id=表2.uid
内连接:
内连接查询出与连接条件匹配的数据行,搭配比较运算符使用,分为:等值连接、不等连接、自然连接。
1.等值连接 在连接条件中使用等于号(=)运算符,返回符合条件的内容。
SELECT * FROM 表名1 as x INNER JOIN 表名2 as y on x.列名=y.列名;
2.不等连接 在连接条件中使用不等号,如>、<、<>等运算符,返回符合条件的内容。
SELECT * FROM 表名1 as A INNER JOIN 表名2 as B on A.列名!=B.列名;
3.自然连接(natural join)自然连接是一种特殊的等值连接,他要求两个关系表中进行连接的必须是相同的属性列(名字相同),无须添加连接条件,并且在结果中消除重复的属性列。
SELECT * FROM 表名1 NATURAL JOIN 表名2;
一道原题:
求两个关系RA和RB的自然连接,书本上的原题是这样的(有点歪,将就一下)
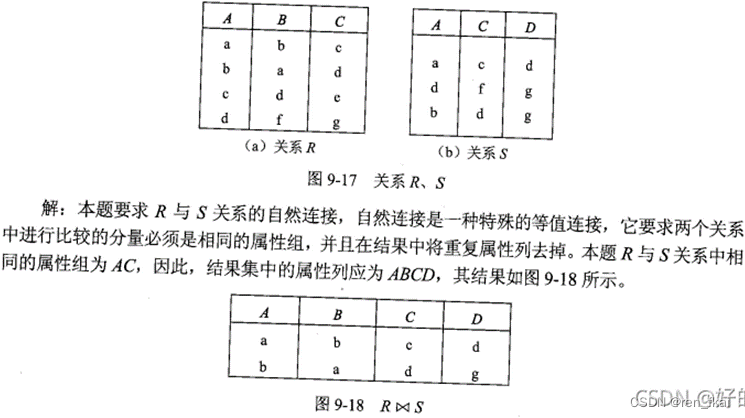
解题思路:
1、首先找到Ra 和Rb 中相同的列,是不是只有A和C两列是他们都有的;
2、我们就只看两个关系式中的A列和C列所在的行;
3、从Ra开始看,Ra的A,C两列所在第一行值是 ac。于是我们去Rb中找到A,C两列同样值为ac的行;
4、我们发现Rb中的第一行A,C列的值和Ra中第一行ac的值一样。所以需要将他们连接起来就是:
a b c a c d。但是,需要做去重复处理,所以得到 a b c d (没毛病);
5、同理,我们继续找RB中符合值为ac的行,发现已经没有了。那么我们继续找Ra中下一个;
6、Ra中 A,C列所在的第二行值为 b,d 。所以我们又要去RB中找值为b,d的行,找到就串起来。
所以找到Rb中的第三行 恰好也是b,d。连起来就是 b a d b d g ,需要做去重复处理,得到:
b a d g
7、再找Ra中的第三行 A,C列的值,对照Rb,发现没有符合条件的,同理第四行。。。最后结束。
所以结果为
外连接
1.左外连接 返回左表中的所有行,如果右表中没有值则补为NULL。
select * from 表名1 as X LEFT OUT JOIN 表名2 as Y on X.列名 = Y.列名;
2.右外连接 返回右表中的所有行,如果左表中没有值则补为NULL。
select * from 表名1 as X RIGHT OUT JOIN 表名2 as Y on X.列名 = Y.列名;
3.全外连接 全外连接是左外连接和右外连接的组合。简单说就是将左外连接和右外连接同时做多一次。根据全连接的定义,我们可以写成左外连接和右外连接组合起来
select * from 表名1 FULL JOIN 表名2;
INNER JOIN字段
SELECT * FROM 表1 INNER JOIN 表2 ON 条件1 INNER JOIN 表3 ON 条件2;
外连接: 分为左外连接和右外连接,分别为LEFT JOIN 和RIGHT JOIN
LEFT JOIN 将保留左边表格全部数据,右表仅显示符合条件数据,RIGHT JOIN相反。
SELECT * FROM 表1 RIGHT JOIN 表2 ON 条件1;
子查询:
1.非相关子查询
先看一个非相关子查询的sql语句。
需求:查询学生表student和学生成绩表grade中成绩为70分的学生的基本信息。
select t.sno,t.sname,t.sage,t.sgentle,t.sbirth,t.sdept from student t where t.sno in (select f.sno from garde f where f.score=70)
这个sql语句的执行时是简单的,
第一步:在grade表中找出成绩为70的学生学号sno,再将该学号返回到父查询作为where子句的条件。
第二步:在student表中找到该学号学生的其他基本信息。
2.相关子查询
所谓相关子查询,是指求解相关子查询不能像求解普通子查询那样,一次将子查询求解出来,然后求解父查询。相关子查询的内层查询由于与外层查询有关,因此必须反复求值。
下面看相关子查询的sql语句。
需求:在学生表student和学生成绩表grade找出参加了“计算机基础”课程并且分数在80分以上的所有学生信息。
select t.sno,t.sname,t.sage,t.sgentle,t.sbirth,sdept from student t where 80<=(select f.score from grade f where f.sno=t.sno and f.cname='计算机基础')
该子查询的执行流程:
第一步:先从父查询的student表中取出第一条记录的sno值,进入子查询中,比较其where子句的条件“where f.sno=t.sno and f.cname=’计算机基础’”,符合则返回score成绩。
第二步:返回父查询,判断父查询的where子句条件80<=返回的score,如果条件为true,则返回第1条记录。
第三步:从父查询的student表中取出第2条数据,重复上述操作,直到所有父查询中的表中记录取完为止。
总结:
对比这两个查询的sql执行过程可以看出,相关子查询和非相关子查询的不同点在于,相关子查询依赖于父查询,父查询和子查询是有联系的,尤其在子查询的where语句中更是如此。明白了他们的执行过程,再去看相关子查询的代码,一下子就明白了。
SELECT语句中还可以调用另外一个或更多个SELECT语句。
子查询可以出现在两个位置:
WHERE后,可以把子查询得到的结果作为另一个SELECT的条件值
FROM后,可以把子查询得到的结果集表单当作一个新表处理
SELECT * FROM 表1 WHERE id IN(
SELECT uid FROM 表2 WHERE order > 10
)
小结——SQL语句执行顺序:
(1) FROM
(2) <join_type>JOIN<right_table>
(3) WHERE<where_condition>
(4) GROUP BY<group_by_list>
(5) HAVING<having_condtion>
(6) SELECT DISTINCT
(7) ORDER BY

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









