






1:得到文件夹里独立的文件名以及绝对路径
这是要解析的xml文件:
获取文件所处的上级目录:
folder_path = 'D:\\PycharmProjects\\XmltoDict\\xmltest_xml'使用os.listdir()获取文件夹下的所有xml文件名:
# xmltest_xml文件夹下面的所有xml文件名
records_fileName_list = os.listdir(path)使用str.find()方法过滤掉除病程记录之外的病历单并得到绝对路径名:
if records_fileName.find('病程记录') == 0:
records_absolute_fileNames_list.append(os.path.join(folder_path, records_fileName))得到所有病程记录单子的文件名:
for records_fileName in records_filename_list:
# if判断过滤掉除病程记录之外的单子
if records_fileName.find('病程记录') == 0:
new_records_filename_list.append(records_fileName)2:解析xml文件为ElementTree对象并获取根节点
导入模块:
import xml.etree.ElementTree as ET使用ET.parse()解析xml文件为ELementTree对象:
# 获取record树列表
tree_list = record_absolute_pathName_Get(folder_path)
treename_list = record_filename_list_Get(folder_path)
for treename, tree in zip(treename_list, tree_list):
elementtree = ET.parse(tree)
root = elementtree.getroot()
3:编写含有各个不同子节点的子节点解析函数
utext解析函数:
utext是出现最多的xml标签,内容为一些文本信息,是抓取的主要信息:
def utext_Process(utext_parent: ET) -> dict:
if utext_parent is not None:
utext_dict = {}
# 该节点下的所有utext节点
utext_node_list = utext_parent.findall("utext")
new_utext_node_list = []
# 过滤掉空列表
if utext_node_list is not None:
# 过滤到无效字符的剩下的所有utext节点并入新列表
new_utext_list = [utext_node for utext_node in utext_node_list if
utext_node.text not in [',', ':', ', ', ' ', '\n', '/', '。', ':']]
count = 1
# 合并new_utext_node_list,new_element_node_list
for new_utext in new_utext_list:
if new_utext is not None:
if new_utext.text is not None:
utext_dict.update({new_utext.tag + str(count): new_utext.text.strip().strip(":")})
count = count + 1
if utext_dict:
return utext_dictelement解析函数:
element节点尽量不要使用element.text作为字典的值,使用element.attrib里的title和value更好,而却最好使用iter()方法获取所有element节点而不是findall,这样更快,代码更简洁
def element_Process(element_ancestor: ET) -> dict:
if element_ancestor is not None:
element_dict = {}
# 该节点下的所有element节点
element_list = element_ancestor.iter("element")
# 过滤掉空列表
if element_list is not None:
# 过滤到无效字符的剩下的所有element节点并入新列表
new_element_list = [element_node for element_node in element_list if
element_node.text not in [',', ':', ', ', ' ', '\n', '/', '。', ':']]
# 将element标签的title值和value值组成字典添加到element_dict
for new_element in new_element_list:
if new_element is not None:
if new_element.text is not None:
title = new_element.get("title")
value = new_element.get("value")
if title is not None and value is not None:
key = title
value = value.strip().strip(":")
if key is not None and value is not None:
element_dict.update({key: value})
if element_dict:
return element_dictsignature解析函数:
返回医师签名信息:
# 子节点有signature的解析函数
def signature_Process(node: ET) -> dict:
if node is not None:
sign_dict = {}
signs = node.findall("signature")
if signs is not None:
for sign in signs:
signplaceholder_key = sign.attrib.get("signplaceholder", "医师签名notFound")
displayinfo_value = sign.attrib.get("displayinfo", "姓名notFound")
sign_dict.update({signplaceholder_key.strip('[]'): displayinfo_value})
if sign_dict:
return sign_dictsection解析函数:
section大部分都是utext,还有少量的element以及signature
subdoc解析函数:
首次病程记录里有很多的section,其他的记录都是utext和element,signature节点是一定有的,可能会有section节点
4:由主函数调用后返回字典,存为json文件
字典类型转化为json:
xmljson = json.dumps(xmldicts, ensure_ascii=False)
# pprint(xmljson)保存在项目的根目录:
with open('test1.json', mode="w", encoding="utf-8") as f:
json.dump(xmldicts, f, ensure_ascii=False, sort_keys=False, indent=2, separators=(',', ':'), skipkeys=True)
5:全部代码:
# encoding=gbk
'''
@auther:zhanggong
需要解析的内容为:
1:root下的subdocuments->header->document
2:root下的document的每个subdoc
2.1:其中subdoc.no1也即首次病程记录下有utext、element、以及各个section的内容是需要解析的
2.1.1:section下会有大量的utext以及偶尔出现的element还有signature
2.2:只有subdoc1下的section才有一个element。其title为入院诊断
设计:不同单子设计一个解析函数,该函数下面嵌套section解析函数,element解析函数,utext解析函数,signature解析函数
单独处理subdocument->header->document
findall所有的subdoc
单独处理subdoc1也即首次病程记录
其余的subdoc遍历utext节点,检查signature和enum->enumvalues->element
'''
import os
import json
import re
import xml.etree.ElementTree as ET
# xmltest_xml的绝对路径
from datetime import datetime
folder_path = 'D:\\PycharmProjects\\XmltoDict\\xmltest_xml'
# 得到所有病程记录单子绝对路径的列表
def record_absolute_pathName_Get(path):
# recordname列表
records_absolute_fileNames_list = []
# xmltest_xml文件夹下面的所有xml文件名
records_fileName_list = os.listdir(path)
# pprint(records_fileName_list)
for records_fileName in records_fileName_list:
# if判断过滤掉除病程记录之外的单子
if records_fileName.find('病程记录') == 0:
records_absolute_fileNames_list.append(os.path.join(folder_path, records_fileName))
else:
continue
# pprint(records_absolute_fileNames_list)
return records_absolute_fileNames_list
# 得到所有病程记录单子名字的列表
def record_filename_list_Get(path):
# record_filename_list
records_filename_list = os.listdir(path)
new_records_filename_list = []
for records_fileName in records_filename_list:
# if判断过滤掉除病程记录之外的单子
if records_fileName.find('病程记录') == 0:
new_records_filename_list.append(records_fileName)
else:
continue
# pprint(records_absolute_fileNames_list)
return new_records_filename_list
# 病程记录解析函数
def records_Procss(root):
# 单独处理subdocuments->header->document
def sub_header_doc_Process(node: ET) -> dict:
if node is not None:
# 解析subdocuments->header->document
sub_header_doc_dict = {}
sub_node = node.find("subdocuments")
sub_header_node = sub_node.find("header")
sub_header_doc_node = sub_header_node.find("document")
if sub_node is not None:
if sub_header_node is not None:
if sub_header_doc_node is not None:
for element in sub_header_doc_node.iter("element"):
sub_header_doc_dict[element.attrib["title"]] = element.text
if sub_header_doc_dict:
return sub_header_doc_dict
# subdoc解析函数
def subdoc_Process(subdoc: ET) -> dict:
if subdoc is not None:
subdoc_dict = {}
section_dict = {}
sections_dict = {}
element_dict = {}
sign_dict = {}
# 解析subdoc下的utext
utext_text = dict_to_text(utext_Process(subdoc))
# 解析subdoc下的element
element_dict = element_Process(subdoc)
# 解析subdoc下的signature
sign_dict = signature_Process(subdoc)
# 解析多个section
sections = subdoc.findall("section")
for section in sections:
section_dict.update(section_Process(section))
if section_dict:
sections_dict.update(section_dict)
if utext_text:
subdoc_dict.update({"文本": utext_text})
if element_dict:
subdoc_dict.update(element_dict)
if "签名" in subdoc_dict:
if element_dict["签名"] is None:
element_dict.pop("签名")
if sections_dict:
subdoc_dict.update(sections_dict)
if sign_dict:
subdoc_dict.update(sign_dict)
data_value = subdoc_dict.pop('日期时间')
subdoc_dict.update({'日期时间': data_value})
return subdoc_dict
# section解析函数
def section_Process(section: ET) -> dict:
if section is not None:
section_dict = {}
section_utext_dict = utext_Process(section)
section_element_dict = element_Process(section)
section_sign_dict = signature_Process(section)
# section_enum_enumvalues_element_dict = enum_enumvalues_element_Process(section)
# 合并以上三个字典
if section_utext_dict:
section_dict.update({section.attrib["title"]: dict_to_text(section_utext_dict).strip(":")})
if section_element_dict:
section_dict.update(section_element_dict)
if section_sign_dict:
section_dict.update(section_sign_dict)
tags = ["当前日期", "性别", "年龄", "姓名", "入院日期", "签名"]
dic_pop(tags, section_dict)
return section_dict
# 子节点有utext节点的解析函数
def utext_Process(utext_parent: ET) -> dict:
if utext_parent is not None:
utext_dict = {}
# 该节点下的所有utext节点
utext_node_list = utext_parent.findall("utext")
new_utext_node_list = []
# 过滤掉空列表
if utext_node_list is not None:
# 过滤到无效字符的剩下的所有utext节点并入新列表
new_utext_list = [utext_node for utext_node in utext_node_list if
utext_node.text not in [',', ':', ', ', ' ', '\n', '/', '。', ':']]
count = 1
# 合并new_utext_node_list,new_element_node_list
for new_utext in new_utext_list:
if new_utext is not None:
if new_utext.text is not None:
utext_dict.update({new_utext.tag + str(count): new_utext.text.strip().strip(":")})
count = count + 1
if utext_dict:
return utext_dict
# 子节点有element节点的解析函数
def element_Process(element_ancestor: ET) -> dict:
if element_ancestor is not None:
element_dict = {}
# 该节点下的所有element节点
element_list = element_ancestor.iter("element")
# 过滤掉空列表
if element_list is not None:
# 过滤到无效字符的剩下的所有element节点并入新列表
new_element_list = [element_node for element_node in element_list if
element_node.text not in [',', ':', ', ', ' ', '\n', '/', '。', ':']]
# 将element标签的title值和value值组成字典添加到element_dict
for new_element in new_element_list:
if new_element is not None:
if new_element.text is not None:
title = new_element.get("title")
value = new_element.get("value")
if title is not None and value is not None:
key = title
value = value.strip().strip(":")
if key is not None and value is not None:
element_dict.update({key: value})
if element_dict:
return element_dict
# 子节点有signature的解析函数
def signature_Process(node: ET) -> dict:
if node is not None:
sign_dict = {}
signs = node.findall("signature")
if signs is not None:
for sign in signs:
signplaceholder_key = sign.attrib.get("signplaceholder", "医师签名notFound")
displayinfo_value = sign.attrib.get("displayinfo", "姓名notFound")
sign_dict.update({signplaceholder_key.strip('[]'): displayinfo_value})
if sign_dict:
return sign_dict
# 把字典转化为文本的函数
def dict_to_text(Dict: dict) ->str:
values = " ".join( Dict.values())
values.strip()
return values
# 删除tags列表里存在的字典的键值对的函数
def dic_pop(tags: list, Dict: dict)->dict:
for tag in tags:
if tag in Dict:
Dict.pop(tag)
return Dict
# 返回整个xml文件的字典
xmldict = {}
# xmldict的第一部分
sub_header_doc_dict = sub_header_doc_Process(root)
# xmldict的第二部分
subdocs_list = root.find("document").findall("subdoc")
subdoc_count = 1
subdocs_dict = {}
if subdocs_list:
# 解析每个subdoc
tags1 = ["当前日期", "性别", "年龄", "姓名"]
tags2 = ["当前日期", "性别", "年龄", "姓名", "入院日期", "主诉", "入院诊断"]
for index, subdoc in enumerate(subdocs_list):
subdoc_dict = subdoc_Process(subdoc)
# 首次病程记录
if index == 0:
# 删掉重tags1里的重复信息
dic_pop(tags1, subdoc_dict)
# 整理主诉section
if "主诉" in subdoc_dict:
subdoc_dict["主诉"] = subdoc_dict.pop("文本")
zhusuString = subdoc_dict["主诉"]
start = zhusuString.find("“")
zhusu_value = zhusuString[start + 1:]
subdoc_dict["主诉"] = zhusu_value
# 其他记录
else:
# 删掉重tags1里的重复信息
dic_pop(tags2, subdoc_dict)
if subdoc.attrib["title"] in ["术前小结", "术后首次病程记录", "转入记录", "转出记录"]:
if subdoc_dict.get("文本"):
subdoc_dict.pop("文本")
# 合并西医入院诊断与入院诊断
if subdoc_dict.get("西医入院诊断"):
subdoc_dict["入院诊断"] = subdoc_dict.pop("西医入院诊断")
# 将纯数字的日期时间格式转化为data格式
date = subdoc_dict["日期时间"]
# 统一日期的长度
if date.isdigit():
date = date[0:12]
date = datetime.strptime(date, "%Y%m%d%H%M%S")
date = date.strftime('%Y-%m-%d %H:%M:%S') # 只取年月日,时分秒
subdoc_dict["日期时间"] = date
else:
date = re.sub('\D', '', date)
date = datetime.strptime(date, "%Y%m%d%H%M%S")
date = date.strftime('%Y-%m-%d %H:%M:%S') # 只取年月日,时分秒
subdoc_dict["日期时间"] = date
subdoc_title = subdoc.attrib["title"]
subdocs_dict.update({subdoc_title.strip(".")+"_"+str(subdoc_count): subdoc_dict})
subdoc_count = subdoc_count+1
# 添加两个子字典到xmldict
xmldict.update(sub_header_doc_dict)
xmldict.update(subdocs_dict)
return xmldict
if __name__ == '__main__':
# 获取record树列表
tree_list = record_absolute_pathName_Get(folder_path)
treename_list = record_filename_list_Get(folder_path)
# 循环解析record树
xmldicts = {}
for treename, tree in zip(treename_list, tree_list):
elementtree = ET.parse(tree)
root = elementtree.getroot()
xmldict = records_Procss(root)
xmldicts.update({treename : xmldict})
xmljson = json.dumps(xmldicts, ensure_ascii=False)
# pprint(xmljson)
with open('test1.json', mode="w", encoding="utf-8") as f:
json.dump(xmldicts, f, ensure_ascii=False, sort_keys=False, indent=2, separators=(',', ':'), skipkeys=True)
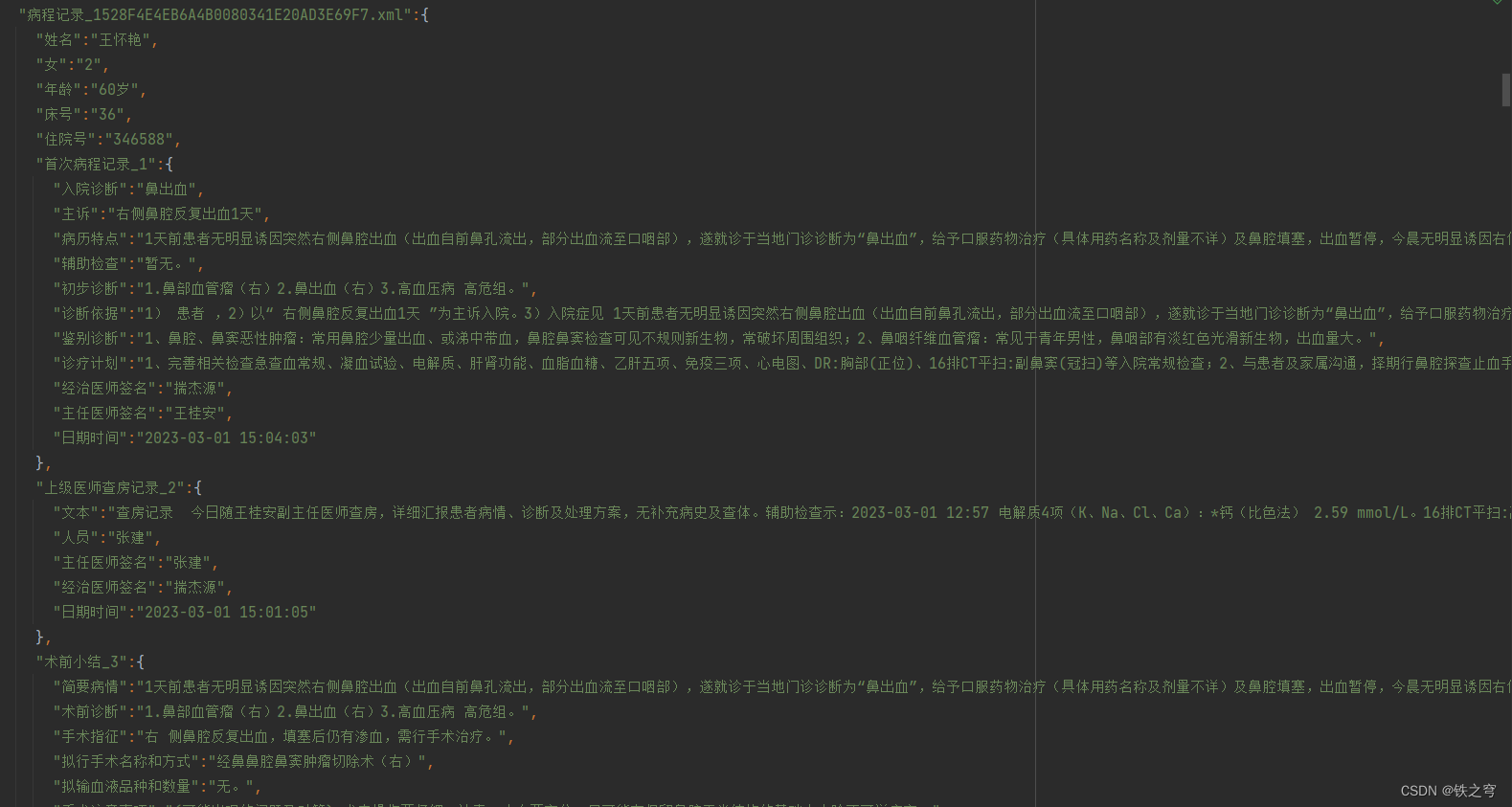
6:效果展示:
7:踩过的坑和学到的知识点:
1:使用json.dump()方法时,注意添加参数ensure_ascil=Flalse否则会乱码
json.dump(xmldicts, f, ensure_ascii=False, sort_keys=False, indent=2, separators=(',', ':'), skipkeys=True)2:os.path.join()函数用于路径拼接文件路径,可以传入多个路径 如果不存在以‘’/’开始的参数,则函数会自动加上
3:字符串str对象常用操作
4:if x 和 if x is not None的区别
5:python in的用法
6:字典的pop()会返回被删除的值
7:str对象的strip()链接调用可以删掉自己不想要的标点符号
8:if x in dicts和dict.pop组合很好用:很快删掉字典里不需要的键值对
# 删除tags列表里存在的字典的键值对的函数
def dic_pop(tags: list, Dict: dict)->dict:
for tag in tags:
if tag in Dict:
Dict.pop(tag)
return Dict9:Python正则表达式处理字符串:re模块使用
10:datatime模块的使用,两个方法:strptime()将字符串转化为日期对象,strftime()将日期对象转化为字符串对象:
# 统一日期的长度
if date.isdigit():
date = date[0:12]
date = datetime.strptime(date, "%Y%m%d%H%M%S")
date = date.strftime('%Y-%m-%d %H:%M:%S') # 只取年月日,时分秒
subdoc_dict["日期时间"] = date
else:
date = re.sub('\D', '', date)
date = datetime.strptime(date, "%Y%m%d%H%M%S")
date = date.strftime('%Y-%m-%d %H:%M:%S') # 只取年月日,时分秒
subdoc_dict["日期时间"] = date














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









