







第二章 编译和链接
通常IDE将编译、汇编和链接的过程一步完成,并将这个过程称之为构建(Build)。IDE通常提供了编译、汇编、链接的默认参数,一般情况下足够使用了,但在实际程序的开发过程中,常常对于很多莫名的错误无所适从,或者需要自己配置程序特有的参数,如果能够深入的了解这些机制,解决这些问题就能游刃有余,收放自如了。
2.1 被隐藏了的过程
对于以下这样一个简单的HelloWorld程序:
//hello.cpp
#include <stdlib.h>
int main ()
{
printf("HelloWorld!");
return 0;
} 在Linux下用GCC编译,只需要用到一行指令
$g++ hello.c
$./a.out
HelloWorld! 在VS中只需要Build一下,也可以生成可执行文件。
事实上,上述过程,至少可以分解为4个步骤:预处理,编译,汇编,链接。

预编译
预编译过程只要处理源代码文件中以“#”开始的预编译指令:
将所有的#define删除,展开宏定义
处理条件编译指令
处理“#include”预编译指令
删除注释
添加行号和文件名表示,
保留#pragma编译器指令,因为编译器要使用它们
预编译后产生后缀名为”.i”的文件。
编译
主要可以分为词法、语法、语义分析,中间代码生成和优化,汇编代码生成或目标机器代码生成。
汇编
将编译产生的汇编文件,经过类似编译的过程,生成目标机器代码
链接
将汇编产生的多个目标机器代码文件,以及用到的运行时库和其他函数库通过地址和空间分配,符号决议,重定位等技术链接生成可执行文件。
2.2 编译器做了什么
这部分内容我本身比较熟悉,书上讲解比较简略,只是大概浏览
2.3 链接器的年龄比编译器长
在发明汇编语言之前,人们直接同机器指令来书写程序。当程序有所修改时,特别是在程序某个位置插入一些指令,会导致很多跳转指令的跳转位置需要做相应的调整,这个过程极为耗时。这种重新计算各个目标地址的过程叫做重定位(Relocation)。
随着程序规模的增大,人们不得不改进程序编写的方式,此时发明了一些符号来代替难以理解的机器指令,即汇编语言。在汇编语言中,可以通过符号来标示某条特定指令(函数)的起始位置或某个变量的起始位置,在修改程序时,就不需要考虑重定位的问题了。在汇编程序编写完成后,直接有汇编程序来计算各个符号的位置,填入生成的机器代码中。可以说符号这个概念极大的提高了程序开发的效率。
但随着程序规模日益增大,动辄数百万行代码,如果只放置在一个文件中,会导致难以理解、维护等各种问题。所以人们开始将代码分模块,层次来组织。但由此引来另外的问题。在A文件中定义的变量和函数,如何在B文件中引用。也就是说,A、B文件同样经过汇编之后,在生成的机器代码中,B文件如何引用A文件中的符号,精确的跳转到相应的指令位置,或访问A文件中定义的全局变量。事实上也就是如何实现模块之间的相互通信。这个模块之间拼接通信的过程,就是链接(Linking)要解决的问题。
2.4 模块拼装——静态链接
人们在开发软件的过程中,希望能够将软件划分为不同的模块和层次,分别来开发、测试、编译、汇编,来简化软件开发的复杂性,最后将生成的目标代码文件通过链接器组装起来,生成可执行文件。
链接的主要过程包括了地址和空间分配(Address and storage Allocation)、符号决议(Symbol Resolution)、重定位(Relocation)等步骤。
个人认为,符号决议指的就是在一个汇编文件中,解析外部符号的过程。实际上Symbol Resolution 直译为符号的解决方案可能更好理解,而不是看似很专业的符号决议,这样拗口的术语。另外,符号决议指的是在静态链接中符号的解析过程。
最基本的静态链接如下图,源代码生成的目标文件与库(library)一起链接生成可执行文件。最常见的是运行时库(Runtime Library),它是支持程序运行的基本函数集合。
库其实是一组目标文件的包,就是一些最常用的代码编译会变成目标文件后打包存放。
在多个文件的程序编译时,如果某个文件引用了另外文件中的全局变量,或函数,在生成目标文件时,由于无法确定Symbol的确切位置,长江与之相关的目标地址置为0,在链接的时候再将其修正。这个地址修正的过程讲座重定位(Relocation),每个要被修正的地方叫做**重定位入口(Relocation Entry)。
2.5 本章小结
本章主要回顾了从源程序到可执行文件的4个步骤,预编译,编译,汇编,链接。着重介绍了链接的历史和静态链接的一系列基本概念:重定位,符号,符号决议,目标文件,库,运行库等概念。
作者在本章中对于“编译”和“汇编”两个术语运用较为混乱,不做具体区分,对于目标文件为汇编语言还是机器语言运用场合有所偏差,容易引起误解。
第三章 目标文件中有什么
编译器在编译汇编之后生成的文件叫做目标文件。目标文件从结构上讲,已经是可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或地址还没有调整,与真正的可执行文件略有不同。
3.1目标文件的格式
目前PC平台上的可执行文件(Executable)格式主要是Windows平台下的PE(Portable Executable)和Linux平台下的ELF(Executable Linkable Format),他们都是COFF(Common File Format)格式的变种。从广义上看,目标文件和可执行文件可以认为是同一种类型的文件。初次之外,动态链接库和静态链接库都是按照可执行文件的格式存储的。其中静态链接库稍有不同,他是把很多目标文件捆绑在一起形成一个文件,再加上一些索引,可以简单的把它理解为包含很多目标文件的文件包、
ELF格式可归结为4类:**可重定位文件(Relocatable File),可执行文件( Executable File),共享目标文件(Shared Object File),核心转储文件( Core Dump File)。
可以用file命令在Linux平台下查看相应的文件格式。
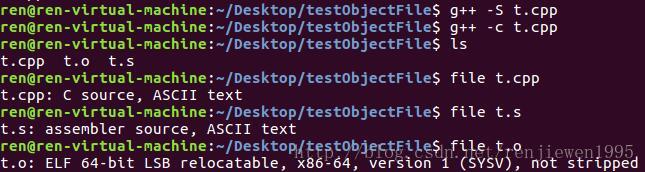
Unix最早的可执行文件是a.out,设计非常简单,当后来共享库概念出现时,a.out格式变得捉襟见肘了。于是人么你设计了COFF格式解决这些问题。COFF的主要贡献是在目标文件中引入了“段“的机制,不同目标文件可以拥有不用数量以及不同类型的”段“。另外,它还定义了调试数据格式。
3.2目标文件是什么样的
简单来说,目标文件包括编译后的机器指令,数据,以及链接时所需的一些信息,比如符号表,调试信息,字符串等。目标文件将这些信息按照不同的类型以“节“(Section)或称作”段“(Segment)的形式存储。
ELF目标文件以一个文件头开始,它描述了整个文件的属性,并且包括一个段表,其中描述了各个段的属性,偏移量等。文件头后就是各个段的内容。.text段包括了编译后生成的可执行机器代码;.data段中包括了初始化的静态变量和全局变量。.bss(Block Started by Symbol)段中包含了未初始化的全局变量和局部静态变量。.bss段只是为未初始化的全局变量和局部变量预留留位置而已,并没有内容,以不占据空间。
总体来说,程序源代码被编译之后主要分为两种段,程序指令和程序数据,代码段术语程序指令,而数据段和.bss段属于程序数据。程序将指令和数据分开存放的主要原因如下:
1. 指令和数据的可读写性不同,分开存放,可以防止指令被有意无意的改写;
2. 出于对程序的局部性考虑,并充分发挥CPU强大的高速缓存能力。CPU通常设计为指令和数据分离的哈弗结构,所以程序指令和数据的分离对于CPU缓存命中率提高是必要且高效的。
3. 最重要的原因是考虑到系统中可能同时运行多个程序副本,此时内存中只需要保存一份该程序的指令部分(以及只读数据部分)。通过虚拟存储管理,多个进程共享只读内存空间,可以节省大量的空间,比如多个浏览器进程的开启和执行。
3.3挖掘SimpleSection.o
真正了不起的程序员对于程序的每一个字节都了如指掌。
————SomeOne
下文通过一个具有代表性又不至于繁琐的示例程序来进行实验和讲解:
/*
*SimpleSection.c
*linux:
* gcc -c SimpleSection.c
*
*Windows:
* cl SimpleSection.c /c /Za
*/
int printf( const char* format,... );
int global_init_var = 84;
int global_uninit_var;
void func1( int i )
{
printf( "%d\n", i );
}
int main()
{
static int static_var = 85;
static int static_var2 ;
int a = 1;
int b;
func1( static_var + static_var + a + b );
return 0;
}本书声明以下分析都是32位Intel X86平台ELF格式,实际上我实验所用为X64,系统为64位Ubuntu。ELF文件结构应当会有写差异。
使用gc· c -c 编译汇编,并用objdump -h(打印基本信息) -x(详细信息) -s(以十六进制形式打印)-d(反汇编形式)查看目标文件内部结构。
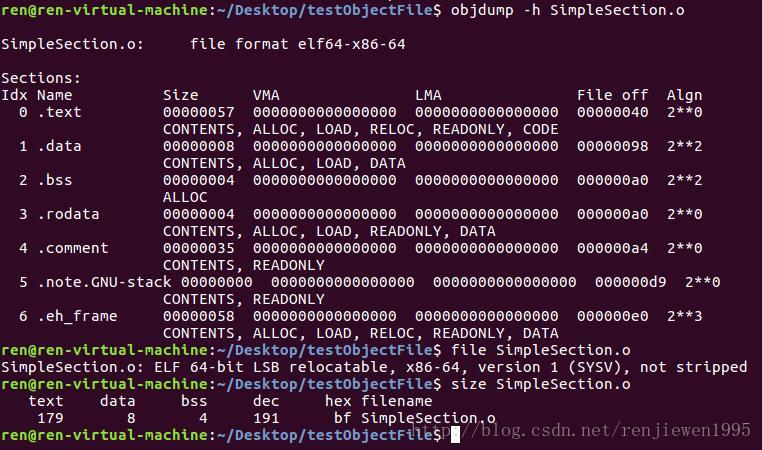
size命令生成结果中,dex和hex下是前三段字节数之和。
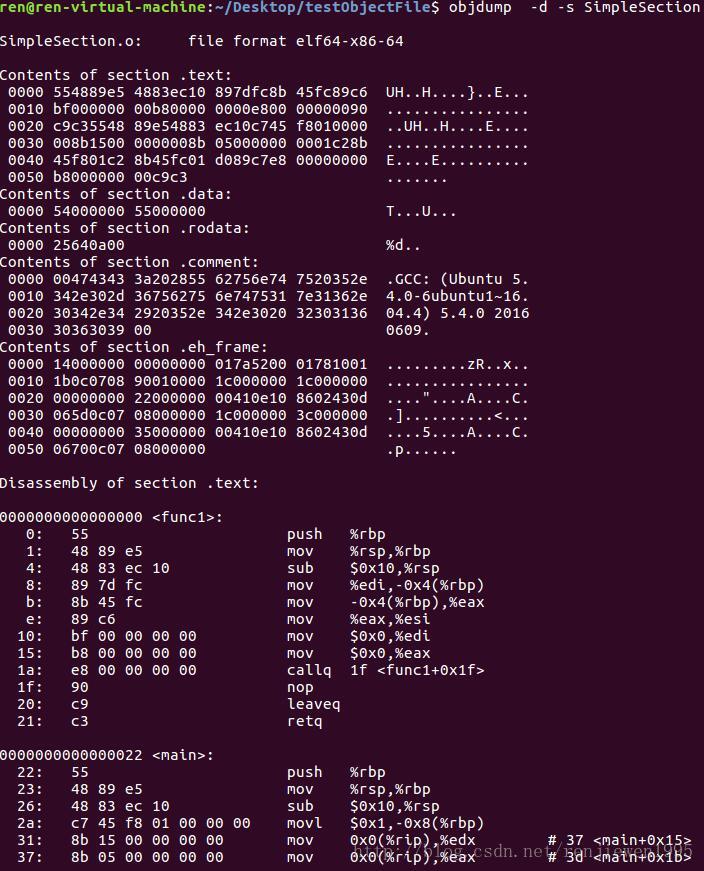
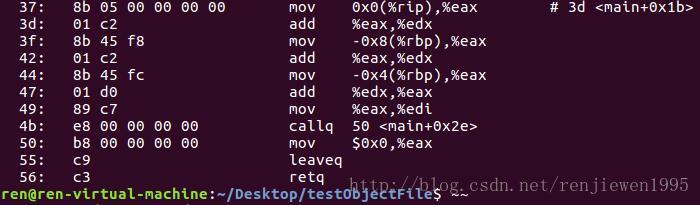
3.3.1 代码段
通过以十六进制显示并反汇编如下:
3.3.2 数据段和只读数据段
.data中存储了已经初始化的全局变量,和静态变量;.rodata段中存放了只读数据,一般熟只读变量和字符串常量(有些编译器也会把字符串常量放在.data段。


3.3.3BSS段
.bss段中存放的是未初始化的全局变量和静态变量,淡我们通过符号变(Symbol Table)可以看到,全局变量global_uninit_var没有存放在任何段,这编译器的实现有关,他们只是预留一个未定义的全局变量符号,等到最后链接时再在.bss段中分配空间。
有些编译器优化机制会对我们分析软件背后的机制有很多障碍,是的很多问题不能一目了然。
例如:当int变量初始化为0时,常常被编译器认为等同于未初始化变量,为了节省存储空间,常常将其放在bss段。
3.3.4其他段
除了.text,.data,.bss这三个最常用的段外,ELF文件中也可能包含其他的段,用来保存于程序相关的其他信息,一些常见的段由:.rodata1,.commnent,.debug,.dynamic,.hash等。
以上的段名都是由“.”作为前缀,表示是系统保留的段名,此外,用户可以自定义一些段名,存入相应的数据,图片,甚至音频信息,来完成一些特殊的任务。GCC也提供了一个拓展的机制,程序员可以指定变量所属的段。
有时候需要把图片或音频数据转化为base64编码,此编码通常是为了在纯文本处理方式下,正确的实现128~255之间的非可见字符。
3.4 ELF文件结构描述
ELF目标文件的整体格式大致如下:
| ELF Header |
|---|
| .text |
| .data |
| .bss |
| other sections |
| Section header table |
| String table |
| Symbol table |
| …… |
ELF目标文件最前不是描述整个文件基本属性的ELF文件头,接下来是各种段,接下来是ELF文件中与段有关的重要结构——段表(Section header table),另外还有一些辅助结构。
3.4.1文件头
用readelf命令可以查看ELF文件:
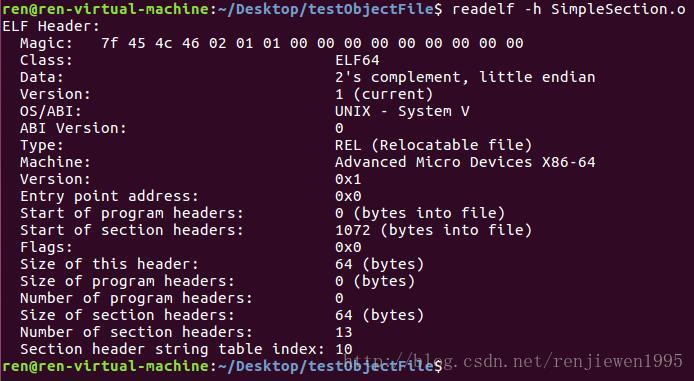
上图可以看出,ELF文件头中定义了ELF魔数,文件机器字节长度、数据存储方式。版本、运行平台,ABI版本,ELF文件类型,硬件平台,硬件平台版本,入口地址,程序头入口和长度,段表位置和长度,段的数量等。
ELF头文件及相关常数定义在“/usr/include/elf.h”,有32和62位版本,他们基本上完全相同。
ELF魔数(Magic):ELF文件头中最前面16个字节用来表示ELF文件的平台属性(字长,存储方式,ELF版本,目标平台,ABI)最开始4个字节是所有ELF文件必须的标识码,第一个为DEL控制字符的ASCII码,接下来三个是ELF三个字母的ASCII码。这四个字节成为ELF魔数,几乎所有可执行文件最开始都是魔数。这种魔数用来确认文件类型,操作系统在加载可执行文件时,会确认魔数是否正确以是否加载。第五个字节表示字长,第六个标识字节序,第七个指明ELF文件格式版本号。后面9个没有定义,一般填0。
魔数的由来 UNIX最早在小型机上诞生,当时系统加载可执行文件时,直接从第一个字节开始执行,人们一般在最开始的地方放置一条跳转指令,来跳过文件头的7个机器字。为了与以前的操作系统保持兼容性,这条跳转指令被当做魔数保留到了几十年后的今天。
计算机学科中类似的例子有不少,也相当有趣,经济学中有所谓的“路径依赖“,其中很有意思的一个例子叫”马屁股决定航天飞机“。大概是说现代航天飞机推进器的宽度最终可以追溯到罗马时代马屁股的宽度。路径依赖关系为推进器宽度->隧道宽度->铁路宽度->马车道宽度->马车宽度->马屁股宽度。
ELF文件标准由来 20世纪90年代初,编译器,操作系统,硬件平台厂商一起成立了一个委员会,来制定具体的可执行文件标准,1995年发布了ELF1.2标准,委员会完成了自己的使命,不久就解散了。
3.4.2段表
ELF文件中有各种段,段表中就保存了各个段的基本属性,通过段表中每个段的偏移量和大小,可以清楚了得到整个ELF文件的具体结构分布。
段的类型和标志对于操作系统如何处理是有用的。link和info两个字段存储了与链接有关的信息。flag字段表示该段在虚拟地址空间的属性。
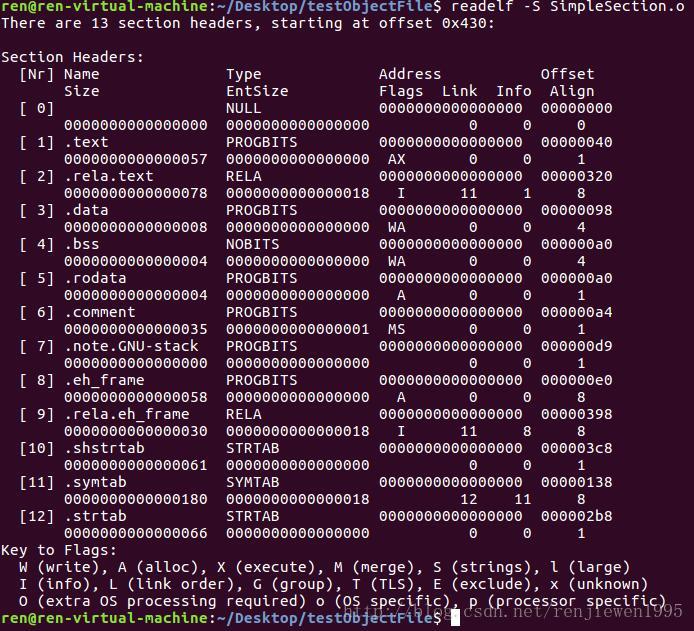
3.4.3重定位表
在链接时,连接器需要重定位目标文件中对绝对地址的引用。对于每个需要重定位的代码段或数据段,都有一个对应的重定位表。具体分析见后文。
3.4.4字符串表
字符串表通常有.strtab和.shstrtab,分别为字符串表和段表字符串表。
3.5链接的接口——符号
链接的过程就是把多个目标文件粘合到一起,实际上目标文件之间的拼合就是文件之间对于变量和函数的地址引用。我们将变量和函数统称为符号(Symbol),除此之外还有段名,局部符号,行号信息以及一些特殊符号等。对于符号表中具体字段的解析暂略。
每个目标文件中都有一个符号表。用nm查看SimpleSection.o的符号表:
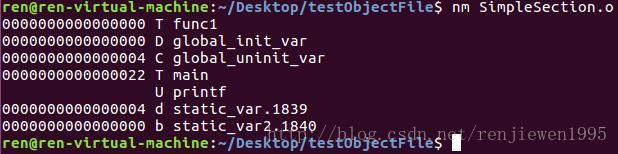
用readelf查看符号表:
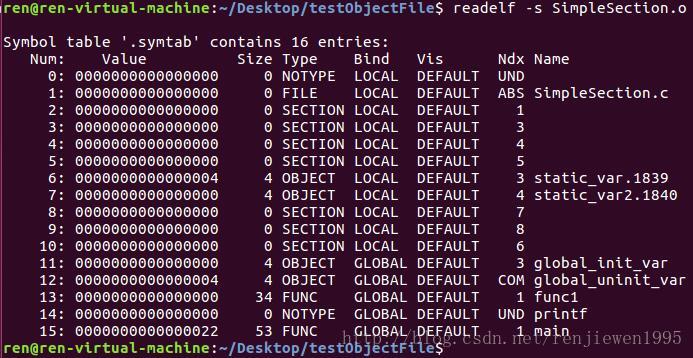
3.5.1符号修饰与函数签名
对于C++函数签名的概念,很多教材上都有相关描述,却在细节方面语焉不详,读完这一节,颇有拨开乌云,豁然开朗的欣喜之感。
约在20世纪70年代以前,编译器在产生目标文件时,符号与相应的变量和函数的名字是一样的。这个时候函数签名可以说就是函数名本身。
后来,当Unix平台和C语言发明时,已经有相当多的汇编编写的库和目标文件。这时就产生了这样一个问题:在C语言中新定义的函数或变量名如果与现有库中的符号名相同的话,就会造成冲突。同样的道理,在不同语言之间编译得到的目标文件如果想要成功链接的话,也必须保证符号名是不冲突的。
为了防止符号名的冲突,Unix下的C语言规定,C语言源代码文件中的多有变量和函数经过编译后,相应的符号名前面都要加“_”;而Fortran语言源代码经过编译后,所有符号的前后都要加上“_”。
以上这种简单原始的方法不能从根本上解决问题,当程序很大时,必须分为不同的模块,不同人员负责开发,很难保证所有模块都不存在相同的变量或函数名。因此而导致的冲突,会造成很多令人费解的困扰。于是C++语言开始考虑了这个问题,引入了命名空间(Namespace)这个概念来解决多模块的符号冲突问题。但随着时间的推移,运行环境发生了很大的变化,符号修饰的规则也有了新的变换。
C++的符号修饰 众所周知,强大又复杂的C++拥有类,继承,虚机制,重载,名称空间等特性,它们使得符号表的管理更为复杂。为了支持C++这些复杂的特性,人们发明了符号修饰(Name Decoration)或符号改编(Name mangling)的机制。
在解决函数重载,以及不同命名空间、作用域中定义的函数决议(Resolution)问题时,人们引入了一个函数签名(Function Signature)的概念。函数签名包含了一个函数的信息,包括函数名,参数的数目类型,所在的类,命名空间及其它信息,对于是否包含返回值,取决于它的实现方式,但在C++中显然返回值不是函数签名的一部分(C++函数重载是通过不同的参数列表实现,而不能通过返回值来区分)。在编译器和链接器处理符号是,他们使用某种符号修饰的方法, 使得每个函数签名对应于一个修饰后名称(Decorated Name)。
GCC对于C++函数修饰规则如下:
所有符号都以“_Z”开头;
对于嵌套的名字(在名称空间或在类中—),后面跟“N”,然后是类或者命名空间的名字,在名字前是字符串的长度,最后以“E”结尾。
他的参数列表紧跟在“E“后面
例如:*
namespace N { class C { int func(int i, double d) ; }; }函数func的修饰后名称为_ZN1N1C4funcEid。不同编译器的名称修饰方法可能实现有所不同
由于不同编译器可能采用不同的符号修饰方法,这是导致不同编译器产生的目标文件一般不能链接的主要原因,
3.5.2extern “C”
C++为了与C兼容,在符号管理上,C++有一个用来声明或定义一个C的符号的extern “C”关键字用法。C++编译器会将在extern “C”作用域内的代码用C的符号修饰方式编译。
extern “C”在C++中复用C语言函数库时尤为有用,我们用过一个C++宏“__cplusplus”来条件编译C库的头文件,从而达到复用C语言库的目的。
3.5.3弱符号与强符号
弱符号与弱引用对于库来说十分有用,在此不做过多解释。
3.6调试信息
目标文件中还可能保存有调试信息。如果我们在gcc编译时加上“-g”选项,就会在目标文件中加入调试信息,出现很多与debug先关的段。对于这些段不做讨论,但值得一提的是,调试信息在目标文件和可执行文件中占很大空间,常常会比程序代码和数据本身大好几倍。
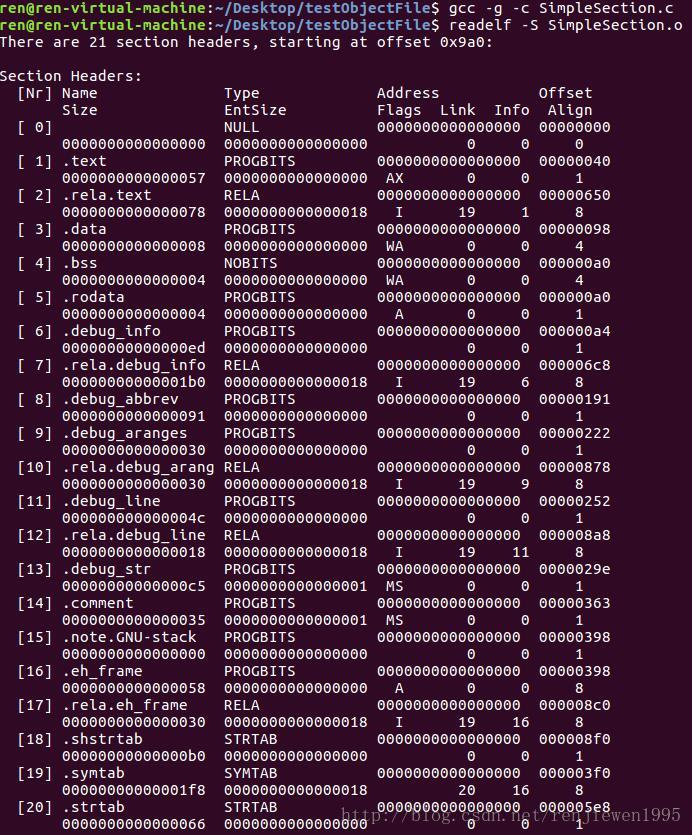
3.7本章小结
本章深入分析 了各种目标文件格式,只要介绍了ELF文件的代码段,数据段,BSS段等与程序运行密切相关的段结构。此外,还介绍了ELF的文件头,段表,重定位表,字符串表,符号表,调试表等结构。
程序的源代码在经过编译后,将代码和数据按照各自属性分别存放于目标文件的不同段中,目标文件中还包括用于链接时的一些调试信息。有了这些目标文件周,接下来如何将他们拼合起来,这就是静态链接所解决的问题,将在下一章介绍。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









