






一轮
-
性能测试时发现系统吞吐量逐渐下降到0,分析原因
吞吐量是指系统在单位时间内处理请求的数量。
断网导致相应时间超时
在系统并发数由小逐渐增大的过程中(这个过程也伴随着服务器系统资源消耗逐渐增大),系统吞吐量先是逐渐增加,达到一个极限后,随着并发数的增加反而下降,达到系统崩溃点后,系统资源耗尽,吞吐量为零。
-
QPS(TPS):每秒钟request/事务 数量固定不变,分析原因
QPS 其实是衡量吞吐量(Throughput)的一个常用指标,就是说服务器在一秒的时间内处理了多少个请求
QPS(事务数/s)=并发数/响应时间
请求数量固定不变(用户固定)
查询字段数量限制固定不变
-
一个登陆界面,包含,用户名,密码,忘记密码按钮和登陆按钮,尽可能全面测试,请写出测试用例
文章来源:面试题:如何测试一个页面的登录功能[转]
-
网页上输入一个网址 如:www.baidu.com 分析整个用户请求到服务器返回页面的过程
-
http 请求报文相应报文的结构,常用的请求方法,响应消息的状态码
-
http 长连接对应头部的哪个键值
-
http 协议中,user-agent 作用是什么
User-Agent是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。用较为普通的一点来说,是一种向访问网站提供你所使用的浏览器类型、操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息的标识。UA字符串在每次浏览器 HTTP 请求时发送到服务器!
Referer 是 HTTP 请求header 的一部分,当浏览器(或者模拟浏览器行为)向web 服务器发送请求的时候,头信息里有包含 Referer 。比如我在www.google.com 里有一个www.baidu.com 链接,那么点击这个www.baidu.com ,它的header 信息里就有:
Referer=http://www.google.com
http请求头中Referer的含义和作用 - shenqueying的博客 - CSDN博客
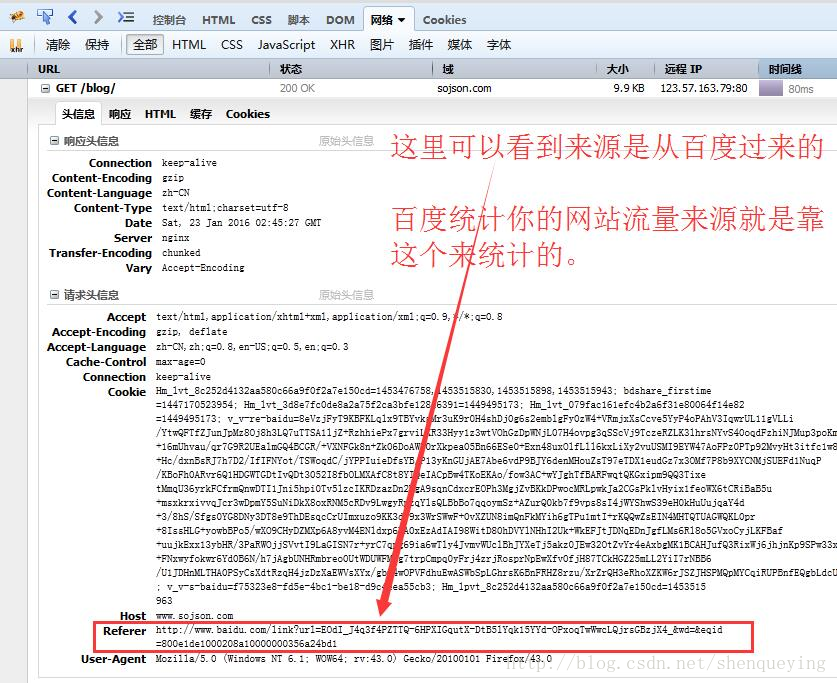
Host:客户端指定自己想访问的http服务器的域名/IP 地址和端口号。
http头中的host字段详解 - zhuangshu_feng'‘每天进步一点点 - CSDN博客
Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
http1.0中默认是关闭的,需要在http头加入”Connection: Keep-Alive”,才能启用Keep-Alive;
http 1.1中默认启用Keep-Alive,如果加入”Connection: close ”才关闭
-
TCP连接过程画出来,并说出为何三次握手和四次挥手
-
数组中是1~100的整型数据,存在重复,排序并统计重复数字出现的次数,考虑最小时间空间复杂度
-
linux命令查找进程号,并杀死进程,写出来
-
kill -9 `ps | grep "test" | grep -v "grep" | sed -n '2P' | awk '{print $1}'` #找到第二个进程,并杀死该进程
1.kill -9 num,杀死1个进程2.`ps`/ 'ps -pux` 列出进程
3. grep "test" 找含“test”字符串的行
4. grep -v "grep" 反选/去掉含“grep”的字符串
5. sed -n '2P' 只打印第二行
6.awk '{print $1}' 打印第一列的字符串
-
# kill 第一个test进程
kill -9 `ps | awk '/test/{print $1;exit}'`
-
ueed0@ueed0:~/Templates/test2$ ps PID TTY TIME CMD 2496 pts/0 00:00:00 bash 4595 pts/0 00:00:00 test 4596 pts/0 00:00:00 test 4597 pts/0 00:00:00 test 4598 pts/0 00:00:00 test 4599 pts/0 00:00:00 test 4600 pts/0 00:00:00 test 4601 pts/0 00:00:00 ps ueed0@ueed0:~/Templates/test2$ kill -9 `ps | awk '/test/{print $1;exit}'` ueed0@ueed0:~/Templates/test2$ ps PID TTY TIME CMD 2496 pts/0 00:00:00 bash 4596 pts/0 00:00:00 test 4597 pts/0 00:00:00 test 4598 pts/0 00:00:00 test 4599 pts/0 00:00:00 test 4600 pts/0 00:00:00 test 4607 pts/0 00:00:00 ps [1] Killed ./test ueed0@ueed0:~/Templates/test2$ kill -9 `ps | awk '/test/{print $1;exit}'` ueed0@ueed0:~/Templates/test2$ ps PID TTY TIME CMD 2496 pts/0 00:00:00 bash 4597 pts/0 00:00:00 test 4598 pts/0 00:00:00 test 4599 pts/0 00:00:00 test 4600 pts/0 00:00:00 test 4612 pts/0 00:00:00 ps [2] Killed ./test ueed0@ueed0:~/Templates/test2$ kill -9 `ps | awk '/test/{print $1;exit}'` ueed0@ueed0:~/Templates/test2$ ueed0@ueed0:~/Templates/test2$ ueed0@ueed0:~/Templates/test2$ ps PID TTY TIME CMD 2496 pts/0 00:00:00 bash 4598 pts/0 00:00:00 test 4599 pts/0 00:00:00 test 4600 pts/0 00:00:00 test 4616 pts/0 00:00:00 ps [3] Killed ./test ueed0@ueed0:~/Templates/test2$ -
Linux 读取文件并将其中的字符串替换为另外字符串
比如$catfile1mqserver=127.0.0.1$catfile2ip=192.168.1.1如何通过shell脚本将file1中的内容改为mqserver=192.168.1.1...
1、按=分割取第二列
cat $file1|grep mqserver|awk -F= '{print $2}'`
2、直接替换文件内容
sed -i "s/127.0.0.1/192.168.1.1/" file1
3、实例:
#!/bin/sh
file1=ip1.txt
file2=ip2.txt
IP1=`cat $file1|grep mqserver|awk -F= '{print $2}'`
IP2=`cat $file2|grep ip|awk -F= '{print $2}'`
echo change $IP1 to $IP2.
sed -i "s/$IP1/$IP2/" $file1
more $file1
说明如下:要在一个目录中,查找所有文件中包含的字符串AAA,找出文件,并用BBB进行替换掉。
#grep -r AAA ./ #表示在当前目录中递归查找包含AAA的文件。
#grep -rl AAA ./ #只列出包含AAA字符串的文件名字。
#sed -i 's/AAA/BBB/g' filename #针对一个文件作替换的命令: sed -i 's/AAA/BBB/g' filename.
sed -i 's/AAA/BBB/g' `grep -l AAA ./`(注意这里的``号,为~下边的那个符号)
若要使用vi进行单个文件的替换可用如下命令:
:1,$s/AAA/BBB/g #AAA是要替换掉的字符串用BBB来替换,1,代表从第一行起,g表示到最后。
-
java GC机制和常用算法
深入理解Java-GC机制 - Steafan_的博客 - CSDN博客
-
什么情况下,资源会被GC回收
哪些情况下的对象会被垃圾回收机制处理掉 - 云+社区 - 腾讯云
GC是如何判断一个对象为"垃圾"的?被GC判断为"垃圾"的对象一定会被回收吗? - 不能说的秘密的博客 - CSDN博客
-
单例模式写出代码,并找到代码中的问题改进,比如懒汉式针对多线程可能要加线程锁机制
public class Singleton {
//懒汉式
// 持有私有静态实例,防止被引用,此处赋值为null,目的是实现延迟加载
private static Singleton singleton=null;
//私有构造方法,防止被实例化
private Singleton(){
}
//静态工程方法,创建实例
// public static synchronized Singleton getInstance(){
// if(singleton==null){
// singleton=new Singleton();
// }
// return singleton;
// }
//将synchronized关键字加在了内部,也就是说当调用的时候是不需要加锁的,
// 只有在instance为null,并创建对象的时候才需要加锁,性能有一定的提升。
public static Singleton getSingleton(){
if (singleton==null){
synchronized (singleton){
singleton=new Singleton();
}
}
return singleton;
}
/*
* 在Java指令中创建对象和赋值操作是分开进行的,也就是说instance = new Singleton();语句是分两步执行的。
* 但是JVM并不保证这两个操作的先后顺序,也就是说有可能JVM会为新的Singleton实例分配空间,
* 然后直接赋值给singleton成员,然后再去初始化这个Singleton实例。这样就可能出错了
* */
//如果该对象被用于序列化,可以保证对象在序列化前后保持一致
public Object readResolve(){
return singleton;
}
}
public class SingletonPro {
/*
* 单例模式使用内部类来维护单例的实现,
* JVM内部的机制能够保证当一个类被加载的时候,这个类的加载过程是线程互斥的。
* 这样当我们第一次调用getInstance的时候,JVM能够帮我们保证instance只被创建一次,
* 并且会保证把赋值给instance的内存初始化完毕,这样我们就不用担心上面的问题。
* 同时该方法也只会在第一次调用的时候使用互斥机制,这样就解决了低性能问题。*/
/* 此处使用一个内部类来维护单例 */
private static class SingletonFactory {
private static SingletonPro instance = new SingletonPro();
}
/* 私有构造方法,防止被实例化 */
private SingletonPro(){
}
/* 获取实例 */
public static SingletonPro getInstance() {
return SingletonFactory.instance;
}
/* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致 */
public Object readResolve() {
return getInstance();
}
}
-
==和equal的区别
== 操作比较的是两个变量的值是否相等,对于引用型变量表示的是两个变量在堆中存储的地址是否相同,即栈中的内容是否相同。
equals操作表示的两个变量是否是对同一个对象的引用,即堆中的内容是否相同。
==一般用在基本数据类型中,equals()一般比较字符串是否相等
String s1 = "Monday";
String s2 = "Monday";
s1==s1 //true,因为s1,s2的值均存放在常量池中,s1,s1在栈中存放常量池中位置相同
String s1 = "Monday";
String s2 = new String("Monday");
s1==s2; //false
s1.equals(s2); //true
原来,程序在运行的时候会创建一个字符串缓冲池当使用 s2 = "Monday" 这样的表达是创建字符串的时候,程序首先会在这个String缓冲池中寻找相同值的对象,在第一个程序中,s1先被放到了池中,所以在s2被创建的时候,程序找到了具有相同值的 s1
将s2引用s1所引用的对象"Monday"
第二段程序中,使用了 new 操作符,他明白的告诉程序:"我要一个新的!不要旧的!"于是一个新的"Monday"Sting对象被创建在内存中。
结论:要想判断两个对象是否相等,不能通过比较两个对象的引用是否相等,这是永远都得不到相等的结果的,因为两个对象的引用永远不会相等,所以正确的比较方法是直接比较这两个对象,比较这两个对象的实质是不是一样的,即这两个对象里面的内容是不是相同的,通过比较这两个对象的属性值是否相同而决定这两个对象是否相等。
所以通过重写类中的equal()方法
文章来源:Java基础之==与equal()的区别 - 程序员人生 - 博客园
二轮
-
请写出快速排序算法
-
请写出链表寻找第一个公共元素的代码
-
请写出两个队列实现栈的代码
-
memcpy内存拷贝和=直接赋值有什么区别
-
测试 linux cp命令,写出测试用例
-
数据库哪些常用关键字
常用关键字
insert into----insert into 表名 values ();
delete-----DELETE 表名 WHERE 列名 运算符 条件
update----UPDATE 表名 SET 列名=值 WHERE 限制条件
select---尽量不要写*
where
in
like(%, _)---模糊查询,%表示0个或多个;_表示一个;
order by----SELECT * FROM emp ORDER BY deptid DESC, ID DESC(排序,加上desc成倒序)
group by--(group by 增强)-------结合分组函数使用 SELECT deptid FROM emp GROUP BY deptid
having
case...when...--------SELECT CASE E.SSEX WHEN 1 THEN '男' WHEN 0 THEN '女' ELSE '不详' END bb FROM EMP E;
set
distinct----去除一列中的重复;
between...and(闭合区间, 即包括前面的数, 也包括后面的数)
all-------SELECT * FROM emp e WHERE e.intime>=ALL(SELECT e1.intime FROM emp e1);
-
数据库限制访问数据数量为100条的关键字
-
数据库创建索引
使用CREATE 语句创建索引
普通索引
CREATE INDEX index_name ON table_name(column_name,column_name) include(score)
非空索引
CREATE UNIQUE INDEX index_name ON table_name (column_name) ;
主键索引
CREATE PRIMARY KEY INDEX index_name ON table_name (column_name) ;
使用ALTER TABLE语句创建索引
alter table table_name add index index_name (column_list) ;
alter table table_name add unique (column_list) ;
alter table table_name add primary key (column_list) ;
删除索引
drop index index_name on table_name ;
alter table table_name drop index index_name ;
alter table table_name drop primary key ;-
三次握手四次挥手,画出来,解释状态变化和为何三次和四次

-
static的作用
第一条也是最重要的一条:隐藏。(static函数,static变量均可)
当同时编译多个文件时,所有未加static前缀的全局变量和函数都具有全局可见性。
如果加了static,就会对其它源文件隐藏。利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。static可以用作函数和变量的前缀,对于函数来讲,static的作用仅限于隐藏.
static的第二个作用是保持变量内容的持久
存储在静态数据区的变量会在程序刚开始运行时就完成初始化,也是唯一的一次初始化。共有两种变量存储在静态存储区:全局变量和static变量,只不过和全局变量比起来,static可以控制变量的可见范围,说到底static还是用来隐藏的。
PS:如果作为static局部变量在函数内定义,它的生存期为整个源程序,但是其作用域仍与自动变量相同,只能在定义该变量的函数内使用该变量。退出该函数后, 尽管该变量还继续存在,但不能使用它。
static的第三个作用是默认初始化为0(static变量)
其实全局变量也具备这一属性,因为全局变量也存储在静态数据区。在静态数据区,内存中所有的字节默认值都是0x00,某些时候这一特点可以减少程序员的工作量。比如初始化一个稀疏矩阵,我们可以一个一个地把所有元素都置0,然后把不是0的几个元素赋值。如果定义成静态的,就省去了一开始置0的操作。再比如要把一个字符数组当字符串来用,但又觉得每次在字符数组末尾加‘\0’;太麻烦。如果把字符串定义成静态的,就省去了这个麻烦。
static的第四个作用:C++中的类成员声明static
在类中声明static变量或者函数时,初始化时使用作用域运算符来标明它所属类,因此,静态数据成员是类的成员,而不是对象的成员,这样就出现以下作用:
(1)类的静态成员函数是属于整个类而非类的对象,所以它没有this指针,这就导致 了它仅能访问类的静态数据和静态成员函数。
(2)不能将静态成员函数定义为虚函数。
(3)由于静态成员声明于类中,操作于其外,所以对其取地址操作,就多少有些特殊 ,变量地址是指向其数据类型的指针 ,函数地址类型是一个“nonmember函数指针”。
(4)由于静态成员函数没有this指针,所以就差不多等同于nonmember函数,结果就 产生了一个意想不到的好处:成为一个callback函数,使得我们得以将C++和C-based X W indow系统结合,同时也成功的应用于线程函数身上。 (这条没遇见过)
(5)static并没有增加程序的时空开销,相反她还缩短了子类对父类静态成员的访问 时间,节省了子类的内存空间。
(6)静态数据成员在<定义或说明>时前面加关键字static。
(7)静态数据成员是静态存储的,所以必须对它进行初始化。 (程序员手动初始化,否则编译时一般不会报错,但是在Link时会报错误)
(8)静态成员初始化与一般数据成员初始化不同:
初始化在类体外进行,而前面不加static,以免与一般静态变量或对象相混淆;
初始化时不加该成员的访问权限控制符private,public等;
初始化时使用作用域运算符来标明它所属类;
所以我们得出静态数据成员初始化的格式:
<数据类型><类名>::<静态数据成员名>=<值>
(9)为了防止父类的影响,可以在子类定义一个与父类相同的静态变量,以屏蔽父类的影响。这里有一点需要注意:我们说静态成员为父类和子类共享,但我们有重复定义了静态成员,这会不会引起错误呢?不会,我们的编译器采用了一种绝妙的手法:name-mangling 用以生成唯一的标志。
C++中static关键字作用总结 - sold_out - 博客园
java:
“static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是不可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。”
也就是方便在没有创建对象的情况下来进行调用(方法/变量)
很显然,被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访问。
static可以用来修饰类的成员方法、类的成员变量,另外可以编写static代码块来优化程序性能。
在Java中切记:static是不允许用来修饰局部变量
1)static方法
static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。并且由于这个特性,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。但是要注意的是,虽然在静态方法中不能访问非静态成员方法和非静态成员变量,但是在非静态成员方法中是可以访问静态成员方法/变量的。
2)static变量
static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。static成员变量的初始化顺序按照定义的顺序进行初始化。
3)static代码块
static关键字还有一个比较关键的作用就是 用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
为什么说static块可以用来优化程序性能,是因为它的特性:只会在类加载的时候执行一次。
1.static关键字会改变类中成员的访问权限吗?
有些初学的朋友会将java中的static与C/C++中的static关键字的功能混淆了。在这里只需要记住一点:与C/C++中的static不同,Java中的static关键字不会影响到变量或者方法的作用域。在Java中能够影响到访问权限的只有private、public、protected(包括包访问权限)这几个关键字。
2.能通过this访问静态成员变量吗?
虽然对于静态方法来说没有this,那么在非静态方法中能够通过this访问静态成员变量吗?先看下面的一个例子
public class Main {
static int value = 33;
public static void main(String[] args) throws Exception{
new Main().printValue();
}
private void printValue(){
int value = 3;
System.out.println(this.value);
}
}33这里面主要考察队this和static的理解。this代表什么?this代表当前对象,那么通过new Main()来调用printValue的话,当前对象就是通过new Main()生成的对象。而static变量是被对象所享有的,因此在printValue中的this.value的值毫无疑问是33。在printValue方法内部的value是局部变量,根本不可能与this关联,所以输出结果是33。在这里永远要记住一点:静态成员变量虽然独立于对象,但是不代表不可以通过对象去访问,所有的静态方法和静态变量都可以通过对象访问(只要访问权限足够)。
3.static能作用于局部变量么?
在C/C++中static是可以作用域局部变量的,但是在Java中切记:static是不允许用来修饰局部变量。不要问为什么,这是Java语法的规定。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









