



 Seaborn是Python的数据可视化库,基于matplotlib,与Pandas紧密集成。它提供了一种高级接口,用于绘制统计图形,如散点图、线图、直方图等,同时支持统计估计和误差线,便于数据探索和理解。Seaborn通过声明式API简化了多维数据集的复合视图,如relplot()、catplot()和pairplot(),并且有个性化的默认样式,同时允许灵活的自定义选项。它与matplotlib的关系使得用户可以在各种环境中使用Seaborn,包括交互式分析和出版质量的图形输出。
Seaborn是Python的数据可视化库,基于matplotlib,与Pandas紧密集成。它提供了一种高级接口,用于绘制统计图形,如散点图、线图、直方图等,同时支持统计估计和误差线,便于数据探索和理解。Seaborn通过声明式API简化了多维数据集的复合视图,如relplot()、catplot()和pairplot(),并且有个性化的默认样式,同时允许灵活的自定义选项。它与matplotlib的关系使得用户可以在各种环境中使用Seaborn,包括交互式分析和出版质量的图形输出。
原文:http://seaborn.pydata.org/introduction.html
Seaborn简介
Seaborn是一个用Python制作统计图形的库。它建立在matplotlib之上,并与Pandas数据结构紧密集成。
Seaborn可帮助您探索和理解您的数据。它的绘图功能对包含整个数据集的数据框和数组进行操作,并在内部执行必要的语义映射和统计聚合以生成信息图。其面向数据集的声明式API让您可以专注于绘图的不同元素的含义,而不是如何绘制它们的细节。
1. 我们的第一个seaborn图
这是seaborn可以做什么的一个例子:
# Import seaborn
import seaborn as sns
# Apply the default theme
sns.set_theme()
# Load an example dataset
tips = sns.load_dataset("tips")
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)

这里发生了一些事情。 让我们一一介绍:
# Import seaborn
import seaborn as sns
Seaborn 是我们需要为这个简单示例导入的唯一库。按照惯例,它是用缩写sns导入的。
在幕后,seaborn使用matplotlib绘制绘图。对于交互式工作,建议在matplotlib模式下使用Jupyter或IPython接口,否则,当您想查看绘图时,必须调用 matplotlib.pyplot.show()。
# Apply the default theme
sns.set_theme()
这使用了matplotlib rcParam系统,并且会影响所有matplotlib图的外观,即使您没有使用seaborn制作它们。除了默认主题之外,还有其他几个选项,您可以独立控制绘图的样式和缩放比例,以在演示上下文之间快速转换您的工作(例如,制作在演讲期间投影时具有可读字体的图形版本)。如果您喜欢matplotlib默认值或喜欢不同的主题,您可以跳过这一步并仍然使用seaborn绘图功能。
(注:出现错误提示module ‘seaborn’ has no attribute ‘set_theme’,可能为Seaborn版本较老,在cmd中使用指令pip install -U seaborn即可)
# Load an example dataset
tips = sns.load_dataset("tips")
文档中的大多数代码将使用load_dataset()函数来快速访问示例数据集。这些数据集没有什么特别之处:它们只是Pandas数据帧,我们可以使用 pandas.read_csv()加载它们或手动构建它们。文档中的大多数示例将使用Pandas数据框指定数据,但seaborn对于它接受的数据结构非常灵活。
(注:若出现错误“TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败”,可能为计算机C:/user/用户名/ 文件夹内无seaborn-data文件夹,该文件夹可在https://github.com/mwaskom/seaborn-data下载)
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
该图采用对seaborn函数relplot()的一次调用,显示了tips数据集中五个变量之间的关系。注意我们是如何仅提供变量的名称及其在图中的作用的。与直接使用matplotlib不同,我们没有必要根据颜色值或标记代码指定绘图元素的属性。在幕后,seaborn处理了从数据帧中的值到matplotlib理解的参数的转换。这种声明式方法让您可以专注于想要回答的问题,而不是关注如何控制matplotlib的细节。
2. 跨可视化的API抽象
没有普适的方式来可视化数据。不同的问题最好用不同的图来回答。通过使用一致的面向数据集的API,Seaborn可以轻松地在不同的视觉表示之间切换。
函数relplot()以这种方式命名是因为它旨在可视化许多不同的统计关系。虽然散点图通常很有效,但用一条线更好地表示一个变量代表时间度量的关系。relplot()函数有一个方便的kind参数,可让您轻松切换到此替代表示:
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharex=False),
)
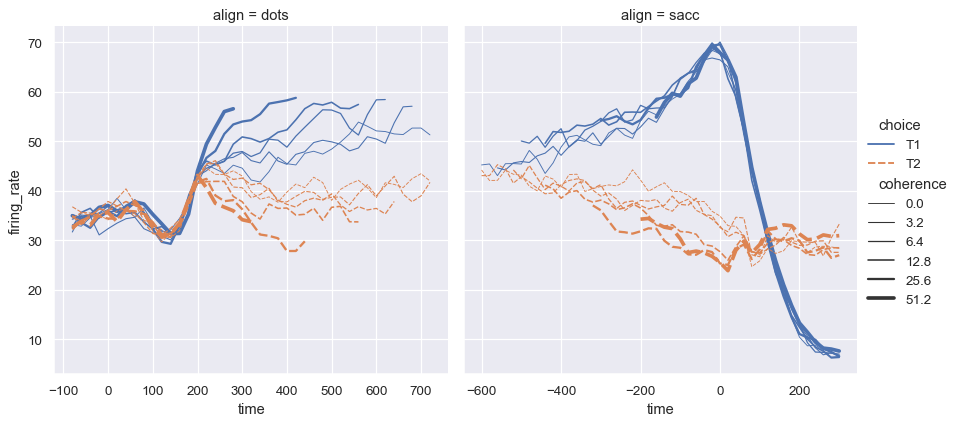
请注意,虽然在散点图和折线图中都使用了size和style参数,但它们对两种图的影响不同:在散点图中,二者分别影响标记区域和符号;而在折线图中,二者影响虚线样式与线宽。我们不需要牢记这些细节,让我们专注于图的整体结构以及我们希望它传达的信息。
3. 统计估计和误差线
通常,我们对作为其他变量的函数的一个变量的平均值感兴趣。许多seaborn函数将自动执行回答这些问题所需的统计估计:
fmri = sns.load_dataset("fmri")
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", col="region",
hue="event", style="event",
)
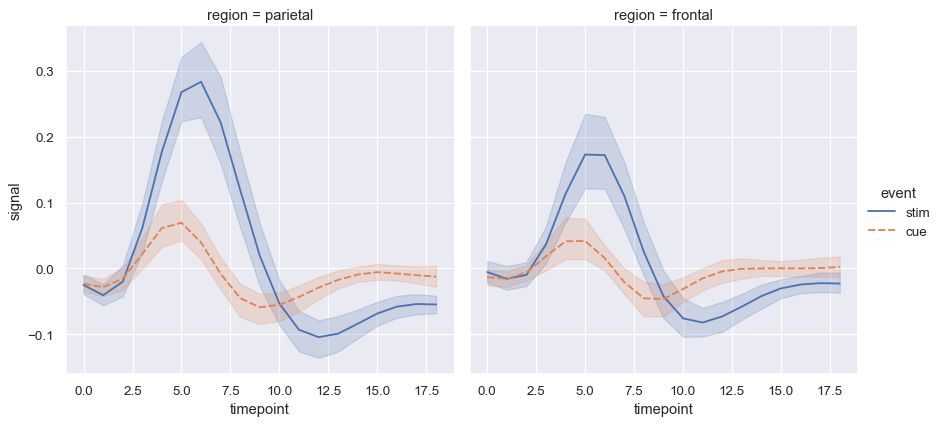
当估计统计值时,seaborn将使用bootstrapping来计算置信区间并绘制代表估计不确定性的误差线。
seaborn中的统计估计不仅仅是描述性统计。例如,可以通过使用lmplot()包含线性回归模型(及其不确定性)来增强散点图:
sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")
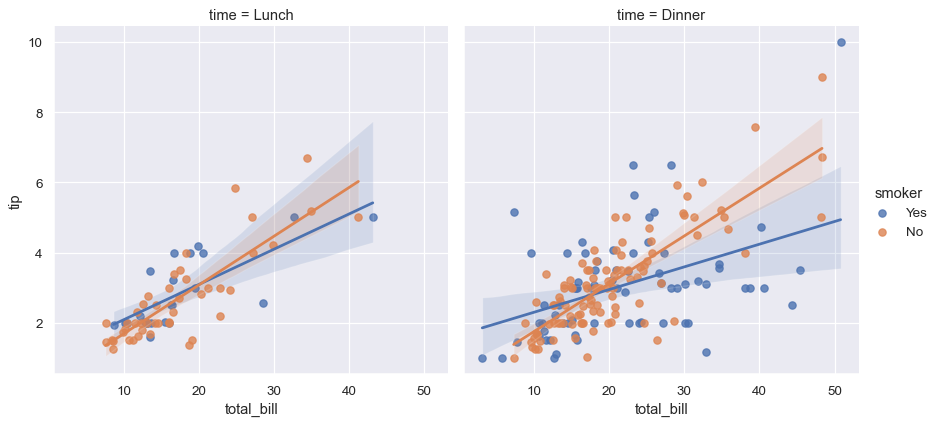
4. 信息性分布摘要
统计分析需要了解数据集中的变量分布。seaborn函数displot()支持多种可视化分布的方法,包括直方图等经典技术和核密度估计等计算密集型方法:
sns.displot(data=tips, x="total_bill", col="time", kde=True)
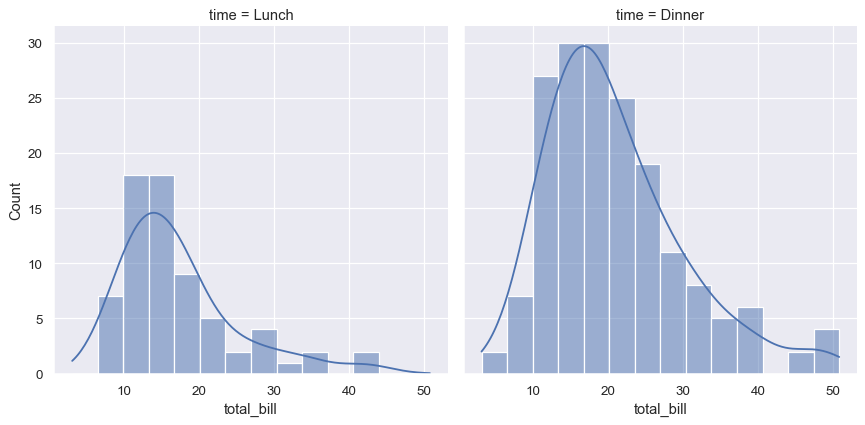
Seaborn还尝试推广功能强大但不太熟悉的技术,例如计算和绘制数据的经验累积分布函数:
sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
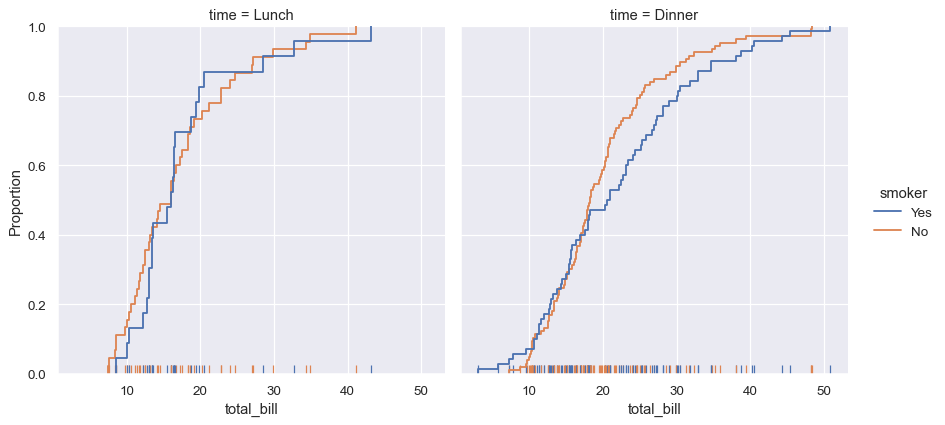
5. 分类数据的专用图
seaborn中有几种专门的绘图类型面向分类数据的可视化。它们可以通过catplot()访问。这些图提供了不同级别的粒度。在最精细的层面上,您可能希望通过绘制“群”图来查看每个观察结果:散点图沿分类轴调整点的位置,使它们不重叠:
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")

或者,您可以使用核密度估计来表示采样点的基础分布:
sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)

或者您可以只显示每个嵌套类别中的平均值及其置信区间:
sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker")

6. 多元数据集上的复合视图
一些seaborn函数结合了多种绘图,以快速提供数据集的信息摘要。其中之一,jointplot(),专注于单一关系。它绘制了两个变量之间的联合分布以及每个变量的边际分布:
penguins = sns.load_dataset("penguins")
sns.jointplot(data=penguins, x="flipper_length_mm", y="bill_length_mm", hue="species")

另一个,pairplot(),采用更广阔的视图,它分别显示了所有成对关系和每个变量的联合分布和边际分布:
sns.pairplot(data=penguins, hue="species")
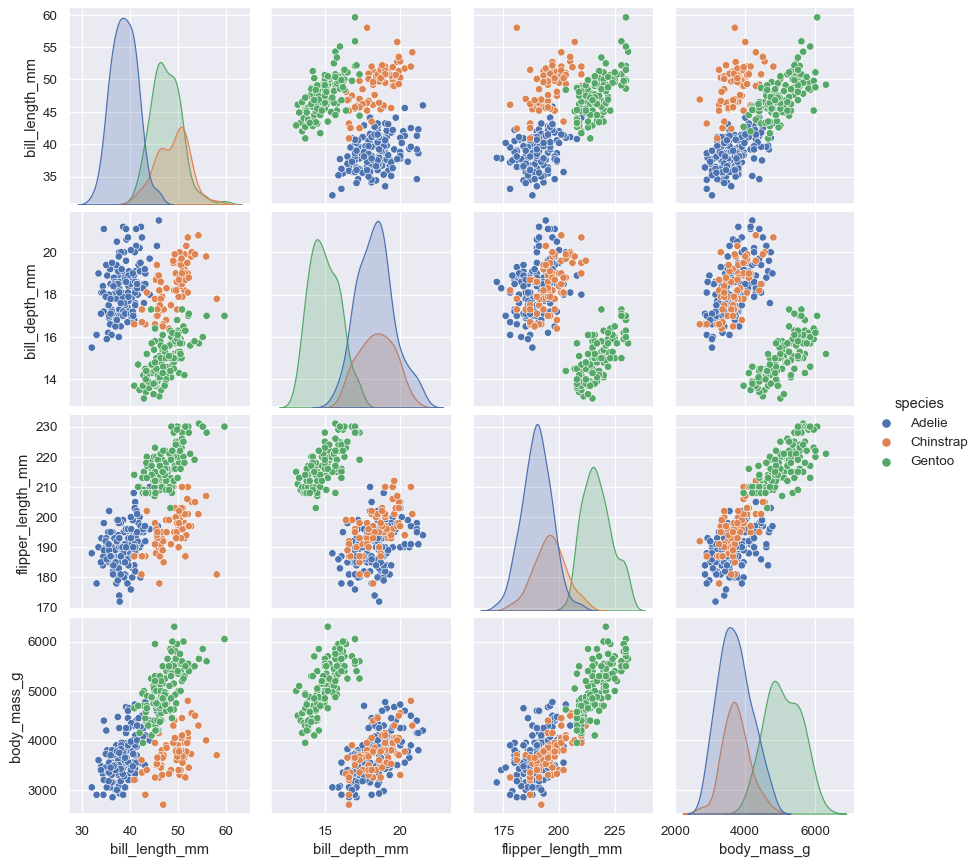
7. 用于制作复杂图形的类和函数
这些工具的工作原理是将轴级绘图功能与管理图形布局的对象相结合,将数据集的结构链接到轴网格。 这两个元素都是公共API的一部分,可以直接使用它们来创建复杂的图形,只需多几行代码:
g = sns.PairGrid(penguins, hue="species", corner=True)
g.map_lower(sns.kdeplot, hue=None, levels=5, color=".2")
g.map_lower(sns.scatterplot, marker="+")
g.map_diag(sns.histplot, element="step", linewidth=0, kde=True)
g.add_legend(frameon=True)
g.legend.set_bbox_to_anchor((.61, .6))
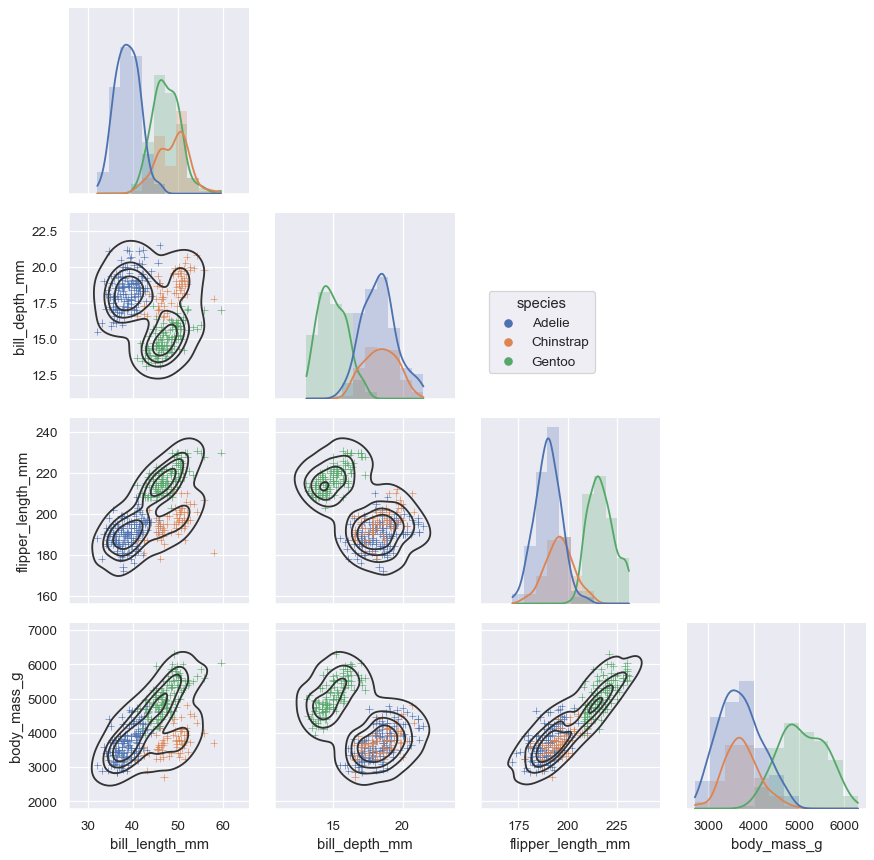
8. 有个性的默认值和灵活的定制
Seaborn使用单个函数调用创建完整的图形。如果可能,其函数将自动添加信息轴标签和图例,以解释图中的语义映射。
在很多情况下,seaborn也会根据数据的特征为其参数选择默认值。例如,我们目前看到的颜色映射使用不同的色调(蓝色、橙色,有时是绿色)来表示分配给色调的分类变量的不同级别。映射数值变量时,一些函数会切换到连续梯度:
sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g"
)

当您准备好共享或发布您的作品时,您可能希望将图形打磨得超出默认值所能达到的效果。 Seaborn允许多个级别的自定义。它定义了多个适用于所有图形的内置主题,其函数具有可以修改每个图的语义映射的标准化参数,并且额外的关键字参数被传递给底层的matplotlib artst,从而允许更多的控制权。创建绘图后,可以通过seaborn API和下降到matplotlib层进行细粒度调整来修改其属性:
sns.set_theme(style="ticks", font_scale=1.25)
g = sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g",
palette="crest", marker="x", s=100,
)
g.set_axis_labels("Bill length (mm)", "Bill depth (mm)", labelpad=10)
g.legend.set_title("Body mass (g)")
g.figure.set_size_inches(6.5, 4.5)
g.ax.margins(.15)
g.despine(trim=True)

9. 与Matplotlib的关系
Seaborn与matplotlib的集成允许您在matplotlib支持的许多环境中使用它,包括笔记本中的探索性分析、GUI应用程序中的实时交互以及多种光栅和矢量格式的存档输出。
虽然您可以仅使用seaborn函数来提高工作效率,但完全自定义您的图形将需要了解matplotlib的概念和 API。对于seaborn的新用户来说,学习曲线的一个方面是了解何时需要下降到matplotlib层以实现特殊定制。另一方面,来自matplotlib的用户会发现他们的大部分知识是相通的。
Matplotlib拥有全面而强大的API,几乎可以根据自己的喜好更改图形的任何属性。seaborn的高级界面和matplotlib的深度可定制性相结合,将使您既能快速探索数据,又能创建可被定制为出版质量最终产品的图形。
附:实例代码
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme()
tips = sns.load_dataset("tips")
dots = sns.load_dataset("dots")
fmri = sns.load_dataset("fmri")
#sns.relplot(data=tips, x="total_bill", y="tip", hue="sex", style="time")
'''
x, y必须为数值型;
hue为data中的变量名,可选项,根据变量值的不同,将散点着不同颜色;变量可以是类别变量或数值型变量;若变量为数值型,则默认着色切换为顺序调色板;
style为data中的变量名,可选项,根据变量值的不同,改变散点形状;可与hue设为同一变量,起视觉强调作用;
size为data中的变量名,可选项,根据变量值的不同,将会产生具有不同尺寸元素的变量进行分组;
'''
#sns.relplot(data=dots, kind="line", x="time", y="firing_rate", col="align", hue="choice", size="coherence", style="choice", facet_kws=dict(sharex=False))
'''
kind参数可将散点图转换为折线图(或其他)类型;
row和col为确定图以哪个变量值拆分,分别为拆分后按行/列排布;
facet_kws“以字典形式传给FacetGrid的其他关键字参数”,具体用途尚不了解,只知道加入此参数可使图像坐标轴显示的范围更贴合数据;
'''
#sns.relplot(data=fmri, kind="line", x="timepoint", y="signal", col="region", hue="event", style="event")
#sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")
#sns.displot(data=tips, x="total_bill", col="time", kde=True)
'''
kde参数可控制是否绘制高斯核密度估计图;
'''
#sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
#sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
#sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)
sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker")
plt.show()

















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









