






拖延症大王小杨在找工作的压力下终于开启了神奇的算法之旅,采用语言Python3,每日打卡。
打卡顺序:写题——写题解——看优解——CSDN专题总结
一、数组类:
2020.7.20 小杨困倦
-
高度检查器:
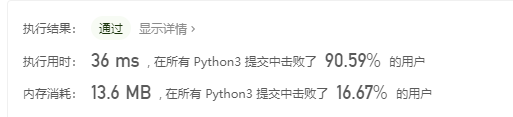
我的解法:
排序+比对,用到列表自带的sort()函数和for循环。sort()会改变原列表,事先copy一份原数据便于比对。
先进思想:
看了优秀题解之后,其实是比对没有优化余地,排序倒是可以不用内置函数,而是用桶排序。桶排序有一个优点就是利用了输入数据的范围提前开一个固定空间(101个桶,下标是从0开始的,但是仅仅用1-100),因此空间复杂度能降到O(1)。先将列表中的数都装到一个个桶里面,再将桶中的数按照顺序输出,这块本质上就是在排序,在输出的同时和原始数据进行一个个比对。
降低时间复杂度的一个技巧就是降低复杂语句的重复次数(我后来提交的代码在空间复杂度上没有进步,反而由于贪图一点想当然的空间导致内置函数的多次使用,大大提升时间复杂度,明明是一次能解决的问题),降低空间复杂度的技巧就是根据题设提前设立存储空间,使得空间消耗不随输入规模的变化而变化。
提交优秀解法之后,在时间上提高了4ms,但是空间占用更大了,13.8MB,emmm,不知道咋回事。而且一个神奇的事情就是,用同一段代码重复提交之后每次的结果都不大一样,可能是测试的样例不一样?好吧。因为O(n)仅仅是一个数量级,不是一个具体值。
今天第一次看java代码,大致上还是能看懂,看不同的编程语言感觉就像啥呢,就像看几个同父异母的孩子,有相像的地方,但是又不是一个妈妈生的。
-
删除排序数组中的重复项
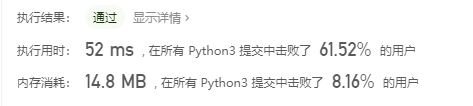
我的解法:
我的算法也是可行,只是时间和空间上比较复杂。建立一个新数组去记录原数组中出现的不重复元素。如果not in就append。
先进思想:
删除重复元素时,可采用双指针。
一个快指针,一个慢指针。快指针从1开始,慢指针从0开始。
快指针在不断前进,慢指针只在出现新元素的时候前进。将新元素赋值给前进后的慢指针。num[i+1]=num[j]。
一个感悟是不要太看重打败率,毕竟很多是直接看了题解之后提交的。提交量越大的这个打败率就自然是偏低的。重点在于掌握思想。
-
合并两个有序数组
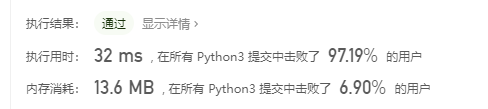
我的算法:
归并排序的三指针实现,需要额外的空间。
先进思想:
如何实现不需要额外空间也可以达到O(m+n)的时间复杂度呢,由于本题的特殊设置,是可以做到这一点的。那就是指针从后往前
走,这一次是谁大谁就进nums1。如果相等就选一个进去就可以,直到两个指针都小于0就不再比较。如果p1指针遍历完成了但
p2指针还没遍历完,此时应该继续遍历p2指针并填入p指针,由于p2是有序的,就直接用复制数组代替了遍历写入。 如果p2指针
遍历完了但p1指针还没遍历完,此时应该继续遍历p1并填入p指针,但由于此时p1指针和p指针重合,所以可以省略遍历操作。同
样也是两部曲,首先直至一个为空,最后将余下的直接写入。
-
杨辉三角
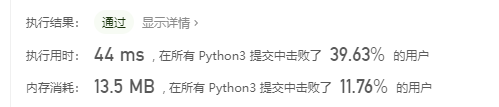
我的算法:
可累死我了,首先以为要严格按照居中格式输出,另外不知道输出和stdout的区别。测试了下发现是return就是输出。害。可被坑惨了,折腾好久,效果也一般。在append方法那里也折腾了好久,发现一个append方法的不知道是bug还是我不会用,反正对二维数组进行append的时候,append会把一维数组中的所有数组都加上这个新加元素。在改为一行一行生成之后再append之后才跑通。这个至少耗我半个小时,而且自信心颇受打击。
先进思想:
基本思想是对的,即已知上一行的内容之后计算下一行。在计算之前,先将首尾的值置1。而且对于第0行不需要单独列出,因为第0行符合这个生成规律,首尾置1,只是不需要补充计算了。
-
两数之和:
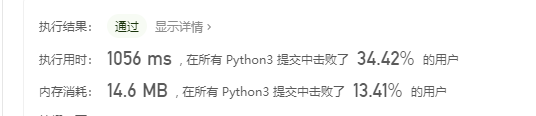
我的算法:
在做题的时候我就意识到了,这个难点在于解决查找问题,而已知值去查找索引的方法很容易就能联想到哈希表。但是野路子的我虽然学过,但是没有知识系统,就靠土方法解的,那就是遍历查找,从时间复杂度上能看出来这一点。
先进思想:
(1)害,没想起来list的index功能,直接list.index(值)即可返回索引。
(2)java语言直接有map这种映射函数,python也有啊,就是字典啊妹妹!怎么没想起来呢。
(3)掌握映射和字典之后,也有两种,一种是建立映射关系或者字典之后查找,这就需要两个循环;另一种是在建立映射关系的时候就判断差是不是在映射关系里面,就是一边建立一边判断,只需要一个循环。
插播重要通知:由于本人做题之后后续处理较多,既在leetcode上写题解,又在csdn上记录(仿佛有很多人看一样),有点累。于是今日起改革,leetcode上记录我的算法,csdn上仅仅记录先进思想,以免重复和混乱(只想偷懒)。
-
最大子序和:

先进思想:
对八起,这个我用暴力算法超出时间限制了。
和我之前理解的动态规划不大一样,之前的有个连续性,这个题在这里就断层了。不过区别也不大哈。
这里求解的量是什么呢?是至少连续两个数的和,也就是我们要求的子序和。
如果前面连续至少两个数的和是负数,我为啥要加呢,因此就不加。这个不加非常灵性,相当于把前面的一截给砍了。
但是当前面连续至少两个数的和是正数,对我现在有大大滴贡献,我当然就要加了。
最后就返回max(nums)即可。注意,这个求解的量可以直接覆盖原数组的值,节约空间。
时间上仅仅遍历了一遍,复杂度为O(n),空间上安排了一个n变量,复杂度为常数级,即O(1)。
有关动态规划的新思考:之前的一些理解是动态规划就是“填表中的数据”,表可以是一维或者二维,至于数据是什么物理意义要看题目要求的是什么。比如这个就是求解子序和,这里的判断节点是是否为正。之后拿到动态规划的题目,首先看求什么,其次列表,最后填表(找到前项和后项的依赖关系,很多时候都要分类讨论)。
PS:不过动态规划的题目千变万化,只是大体上是这样的解题结构,不拘泥于细节。
-
1比特与2比特字符:
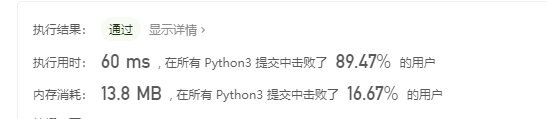
先进思想:
我的解码思想就是在线性扫描,遇到1就跳两个,遇到0就跳一个,用一个变量去记录最后结束的状态,中间分多种情况讨论了,但是其实不需要。只需要看最后扫描的指针停在哪,这只有两种情况。 这是第一,线性扫描的优化。
第二,可以观察规律。会发现最后0的定性取决于整串数字中1的个数,1的个数判断可以转化为整串数字的奇偶性,如果1的个数是奇数的话就是奇数串,反之为偶的话就是偶数串。使用整串数字的异或去反映其奇偶性,如果所有数字依次进行异或运算,结果为1则说明是奇数个1,反之为偶数个1。很好解释,因为不管是偶数个0还是奇数个0,异或之后都是0,而奇数个1异或之后为1,再和0异或,就得到1,偶数个1异或之后为0,再和0异或,就得到0。
-
买卖股票的最佳时机:

先进思想:
这的确是一个动态规划问题,当前是否卖取决于前面的状态。连续性地记录状态变化量,也是动态规划的一个特点。始终用当前状态下的最大利润和之前的最大利润进行比较, 保证最小值和最大利润的更新同时进行。一次遍历就能解决,最大利润的更新就是之前的最大利润和当前价格减去当前最小值中的较小者,最小值的更新就是之前的最小值和当前的价格中的较小者。
-
两数之和:

先进思想:
凡是遇到有序数组,使用双指针或者二分查找。
双指针不是一种算法,是一种编程技巧,善于利用序列的有序性(升序或者降序),使用两个下标对序列进行遍历(可以同向,可以反向)。这里使用的是反向的双指针,从最小+最大开始,利用两个下标的移动去逼近目标和。非常巧妙。
二分查找:设定上下限,不断地和序列索引中值进行比较之后更新上下限,如果中值更小,那么更新下限为中值+1,反之则更新下限为中值-1。
-
乘最多水的容器:
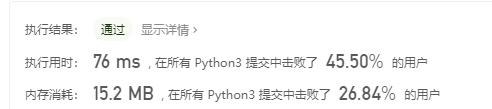
先进思想:
1.双指针可以利用有序数组的有序性,但是不一定一定是利用的有序性。
2.数组的逼近问题是可以使用双指针的,一时半会想不出具体解法的话,其实就可以这样思考,总共就两种,一种是同向,第二是反向。然后分别想想两种方式该怎么移动是最符合逼近要求值的,也是符合直觉的。
-
三数之和:

先进思想:
三数之和实际上是三指针问题了,只不过三指针问题又可以转化为双指针问题,而双指针问题只需要一重循环,因此总共需要两重循环。在实现上,三数之和比两数之和的要求更高,不允许出现重复,因此细节更多。在处理之前也有一些技巧性判断,例如(1)首先判断输入数组是否是数组和是否元素个数小于3,如果不是数组或者小于3那么就直接返回[ ]
(2)三个数都必须去除重复,两处,一处在第一重循环里面,如果当前值等于上一个值那么就continue,第二处在两数之和的第二重循环判断三数之和等于0那段里面。此处使用了两个while循环,如果left<right而且当前左指针等于上一个左指针,那么就左指针右移。
(3)注意这里两数之和的while条件是left<right,不能取等号,否则会出现重复。
(4)在两重循环结束之后记得返回三元组集合。
-
数组拆分
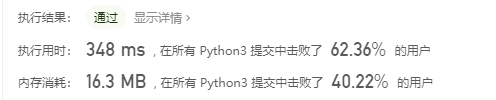
先进思想:
哈哈,这次还有点开心。只用了两分钟一次提交就通过,而且看了一些题解,貌似我这种还是最优解。emmm,不过毕竟是个简单题。而且还是在之前看了算法书和听了算法课的基础上,才稍微在简单题上找到了那么一点感觉。那么接下来就继续努力把!另外就是,我发现做了难题之后再来看简单题简直就是如鱼得水,害,还是不能贪图舒适区,一定程度的训练之后就要勇敢地往上走,这样才能有较大的进步。
-
多数元素
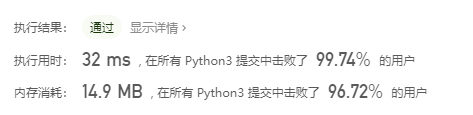
先进思想:
这次首先是有点困难,但是在把握了一遍题意之后,忽然就灵光一现,既然多数是超过半数的存在,那么排序之后,中值一定在那个多数的范围内。因此只需要排序,然后返回中值即可。 可以说这次是思考之后绕开方法,走了捷径。是因为这个题库有限而且有规律可循,但其实吧,现实中就不可能耍这样的小聪明了。当然,这只是其中一种比较好的解法,还有包含优秀编程技巧的解法。
(1)哈希计数法,利用字典这种数据结构去存储每个元素出现的元素,python中专门有一个模块去实现,那就是collections模块中的Counter(输入数组)类别,也是两句话的事儿,counts=colletions.Counter(nums),最后直接return max(counts.keys(),key=counts.get),max函数中的key意思就是按照counts的值去求最大,最后返回的是键值。
(2)随机法虽然听起来很不靠谱,但是不失为一种思路。就是利用random.choice(nums)去每次随机选取一个数,直到这个数统计的出现次数是大于一半的。统计方法:sum(1 for i in nums if i==candidate)。
(3)投票法,思路就还蛮新奇的。是求众数的一种方法,先搞个候选人,再往后走,碰到相同的就count+1,不同的就conut-1,如果count==0,那么就换下一个数为候选人。这里是怎么保证最后候选人一定是众数的呢,是这样的,分两种极端情况讨论,如果候选人等于众数,那么最好的情况是,众数会连续性地保证投票始终为正,也就是候选人为众数一直到底;如果候选人不是众数,那么由于众数对当前候选人都投了反对票,所以还是不敌众数,候选人会扭转为众数。
-
最接近的三数之和:
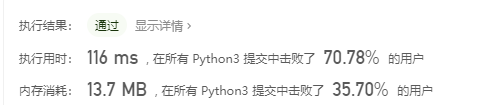
先进思想:
主题思想我还是知道的,就是排序加双指针。但是这个出口我就不知道怎么出来了,另外就是忘记了去重,去重需要去三次。出口就是很简单,如果等于就出来,不等于就接着算下去,同时不断更新绝对值最小值,如果没有等于的就算完了然后返回最终的最小值就行。中间添加了一个update函数去更新,使用了nonlocal的变量使得最小值能被修改。
在 出口 怎么出上耗费太久时间导致开始怀疑人生,接连开始怀疑方法,甚至有“如果不能中途return就浪费了排序,和暴力解法有什么区别“的完全错误想法。排序加双指针的算法,即使没有中途return,它找目标值的路径也要比暴力的短很多。
-
下一个排列:
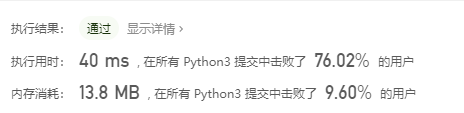
先进思想:
本题就是考察字典序算法。四步走:找左小右大的第一个a,找第一个比a大的b,交换ab,将a之后的数全部升序。
好像能理解一些了,就是所谓对数字的字典序,其实是在找,比这个数大的最小数。
-
最小路径和:

先进思想:
动态规划的题目简单级别的我还是比较熟悉...毕竟期末考试考到了,害。真的考试是第一生产力。题解里面的思路大都是相似的,只不过有的填表顺序不一样,是从右下角往左上角开始填的。但是我个人更加偏向从左上角填到右下角,因为动态规划的本质是问题的最优解包含子问题的最优解,也就是是自底向上解决问题的。
-
螺旋矩阵:
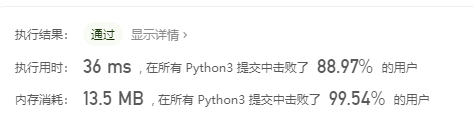
先进思想:
这个题目我想了很久,还是没有成功。最后看到题解的时候觉得妙蛙种子吃了妙脆角进了米奇妙妙屋——妙到家了。在思考的时候我觉得最难解决的问题就是边界在不断更新的问题,为了避免这个问题,我采用了十分麻烦的先赋值外面一圈,再按照顺时针方向赋值的想法,导致失败的一个重要原因是一个个赋值的,而不是一行行赋值的。因为一个个的赋值规律是不断变化的,只有一行行地赋值的规律才是一直稳定不变地保持“从左往右、从上往下、从右往左、从下往上”这个顺序的。按行赋值的话,注意就需要更新边界。另外,按行赋值的好处就在于每次赋值的时候有一维的坐标值始终是某个边界,只需要控制另一维度的循环就行。
-
合并数组:

先进思想:
害,今天不大爽。今天写的两道题都是看题解了之后写的,实乃自信心之打击,只能说积累了经验了吧。合并区间注意两点:1.需要按照左边界先排序,使用sort(key=lambda x:x[0]) 2.要一个个地加进去参与融合,而不能两个两个融合,那样会工作量繁杂。一个个加进去就能保证再一遍循环结束后融合结束。
-
四数之和:
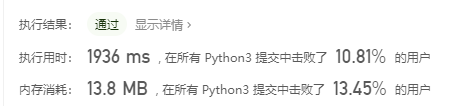
先进思想:
虽然我觉着我的方法还不算太差,但是效率并不是很好。就算之前写过好几个两数之和和三数之和,在这里还是卡壳两次。一次 是循环的初始值,另一次是在找到符合要求的组之后去重的那块。还是要多些代码,锻炼手感,提升找bug能力,不要灰心。框架是对的,答案不对的话就是细节问题,有耐心地调就行,除非超出时间限制,那就是框架不对。
-
子集:

先进思想:
这个看到题目有一点点想法,对,就一点点,就是我之前有接触到的递归。就是一个个元素地往上加,但是反映在代码上反而没有“调用自身”。感觉挺神奇的。每次都有加一个列表,这个列表是用一个列表解析式表达的。如何表达呢,就是用新加进来的这个元素和output中已经有的所有集合融合。
官方总结:递归/回溯/基于二进制掩膜的列举
(1)递归是最好理解的,因为每增加一个数,就是把当前数和之前的所有子集都相加一遍就得到了。
(2)回溯算法和动态规划其实都是大问题转化为小问题的求解方法,都是自底向上的顺序,也都可能暗含了递归思想(调用函数自身)。回溯和动态规划的区别就在于,回溯每一步的路径选择是不确定性的,而动态规划的每一步选择是确定性的。回溯的模板:def huisu(track):
if len(xxx)==n:
print/append等操作
return
for 选择 in 选择列表:
track.append(当前选择)
huisu()
track.pop(当前列表的最后一个选择)
回溯算法的理解难点就在于一个“前一次调用的现场保留”,返回的时候返回的是上一个时间点的函数。
(3)把子集问题转化为生成二进制掩膜的问题,注意bin()函数转化之后的是以字符串形式保存,而且不包含前面的0。因此我们要保证前面有个1来使得0都显示。
-
从前序遍历和中序遍历构造二叉树:

先进思想:
害,这种树的我是一点都没接触过,就不瞎那啥挣扎了。就直接看题解了哈。构建二叉树的关键就在于不断构建新的根节点root(当然,首先是要定义类treenode,三个属性,一个是节点值,一个是左节点,一个是右节点),然后用递归去求root.left和
root.right,在递归的过程中自然又建立了新的根节点。这个新的根节点一方面是根节点,一方面是之前建立的根节点的子节点。另外就是从前序和中序遍历的算法,是先从前序遍历获得根节点的值,再在中序遍历中确定根节点的位置,由此就可以确立两个遍历中的左右子树的区间端点值。在由前序遍历中的根节点去找中序遍历的对应根节点的值的时候,为了便于查找,首先就用字典生成式去构建以中序遍历值去查找索引值的哈希表字典。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









