







 本文介绍了Google如何利用深度强化学习让机器自学玩Atari 2600游戏,打破人类纪录。算法通过游戏屏幕图像和得分作为输入,通过卷积神经网络和强化学习策略,逐渐学习最佳游戏策略。通过Q-learning和Temporal Difference方法,算法在没有监督的情况下自我学习和改进,最终达到高水平游戏表现。
本文介绍了Google如何利用深度强化学习让机器自学玩Atari 2600游戏,打破人类纪录。算法通过游戏屏幕图像和得分作为输入,通过卷积神经网络和强化学习策略,逐渐学习最佳游戏策略。通过Q-learning和Temporal Difference方法,算法在没有监督的情况下自我学习和改进,最终达到高水平游戏表现。


今年上半年(2015年2月),Google在Nature上发表了一篇论文:Human-level control through deep reinforcement learning。文章描述了如何让电脑自己学会打Atari 2600电子游戏。Atari 2600是80年代风靡美国的游戏机,总共包括49个独立的游戏,其中不乏我们熟悉的Breakout(打砖块),Galaxy Invaders(小蜜蜂)等经典游戏。Google算法的输入只有游戏屏幕的图像和游戏的得分,在没有人为干预的情况下,电脑自己学会了游戏的玩法,而且在29个游戏中打破了人类玩家的记录。
Google到底是如何做到的呢?答案当然是深度学习了。
先来看看Google给出的神经网络架构。

网络的最左边是输入,右边是输出。游戏屏幕的图像(实际上是4幅连续的图像,可以理解为4个通道的图像)经过2个卷积层(论文中写的是3个),然后经过2个全连接层,最后映射到游戏手柄所有可能的动作。各层之间使用ReLU激活函数。
这个网络怎么看着这么眼熟?这和我们识别MNIST数字时用的卷积神经网络是一样一样的。
可是转念又一想,还是不对。我们识别MNIST数字的时候,是Supervised Learning(监督学习)。每个图像对应的输出是事先知道的。可是在游戏中并不是这样,游戏环境给出的只是得分。算法需要根据得分的变化来推断之前做出的动作是不是有利的。
这就像训练宠物一样。当宠物做出了指定动作之后,我们给它一些食物作为奖励,使它更加坚信只要做出那个动作就会得到奖励。这种训练叫做Reinforcement Learning(强化学习)。
强化学习并没有指定的输出,环境只对算法做出的动作给出相应的奖励,由算法来主动发现什么时间做出什么动作是合适的。强化学习的难处在于,奖励往往是有延时的。比如在一个飞机游戏中,玩家指挥自己的飞机在合适的时机发射子弹,相应的奖励要等到子弹击中敌机才会给出。从发射子弹到击中敌机之间有一个时间延迟。那么算法如何跨越这个时间延迟,把击中敌机所得到的奖励映射到之前发射子弹的这个动作上呢?
要解释这个问题,我们需要首先来谈一下强化学习是怎么一回事。
Reinforcement Learning(强化学习)
先借用一下维基百科的描述:
| 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。 |
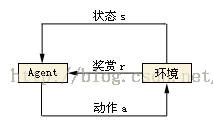
在强化学习的世界里,我们的算法(或者说人工智能)被称为Agent,它与环境发生交互。Agent从环境中获取状态(state),并决定自己要做出的动作(action)。环境会根据其自身的逻辑给Agent予以奖励(reward)。这个奖励有正向和反向之分。比如动物生活在大自然中,吃到食物即是一个正向的奖励,而挨饿甚至失去生命就是反向的奖励。动物们靠着自己的本能趋利避害,增大自己得到正向奖励的机会。如果反过来说,就是避免得到反向的奖励,而挨饿什么的最终会导致死亡。所以动物生存的唯一目的其实就是避免死亡。
在电子游戏世界(特指Atari 2600这一类的简单游戏。不包括推理解密类的游戏)中:
- 环境指的是游戏本身,包括其内部的各种逻辑;
- Agent指的是操作游戏的玩家,当然也可以是指操作游戏的AI算法;
- 状态就是指游戏在屏幕上展现的画面。游戏通过屏幕画面把状态信息传达给Agent。如果是棋类游戏,状态是离散的,状态的数量是有限的。但在动作类游戏(如打飞机)中,状态是画面中的每个物体(飞机,敌人,子弹等等)所处的位置和运动速度的组合。状态是连续的,而且数量几乎是无限的。
- 动作是指手柄的按键组合,包括方向键和按钮的组合,当然也包括什么都不按(不做任何动作)。
- 奖励是指游戏的得分,每击中一个敌人都可以得到一些得分的奖励。
- 策略是Agent脑子里从状态到动作的映射。也就是说,每当Agent看到一个游戏画面(状态),就应该知道该如何操纵手柄(动作)。Reinforcement Learning算法的任务就是找到最佳的策略。策略的表示方法可以有很多。比如:
- 当状态的个数是有限的情况下,我们可以给每个状态指定一个最佳动作,以后只要看到某种状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









