









在我们搭建神经网络时,通常的做法是每一层后面都需要添加一个激活函数。它的作用是将一个线性的模型转化为非线性模型。因为现实生活中很多场景需要解决的都是非线性问题。而线性模型是有局限性的。比如一层线性神经网络就无法解决异或问题。
Sigmod
sigmod:1/(1+e^-x)
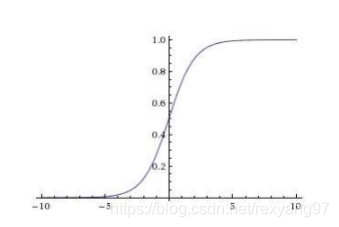
是最经典的激活函数,一层的神经网络加上sigmod其实就是最传统逻辑回归的做法。
它能够把任何数映射到[0,1]之间,十分直观。你可以把它想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。
同时我们可以发现,在本身的绝对值大于5的情况下,梯度就会变得非常小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了。可能上一个节点的梯度是下一个节点的百分之一还不到,这就导致前面的节点改变速度非常慢。结果可能就是后面的层数可能已经收敛到某一个局部最小值了,而前面的节点可能还接近初始的随机化值。这就意味着我们训练出来的神经网络是基于初始化随机的一部分层做的一个局部最优化。类似于此图:
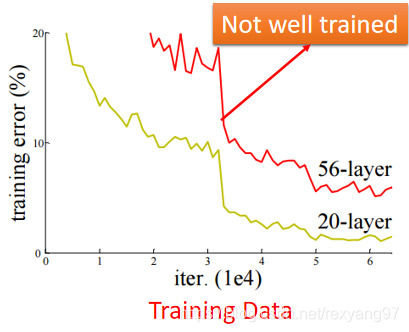
这就叫做梯度消失问题,解决这个问题的一种方法就是更换激活函数。
sigmod的另外一个缺点是它的输出是单边的,是非0均值输出。这会引入一个问题,当输入均为正值的时候,由于f = sigmoid(wTx+b)),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致收敛缓慢。而且它需要进行指数运算,比较复杂。
tanh
![]()
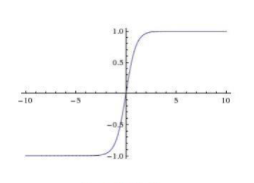
tanh相对于sigmod并没有解决梯度消失与运算复杂的问题,但它解决了输出非0均值的问题。这使得tanh的收敛速度要比sigmoid要快的多。
Relu
Relu:f(x)=max(0,x)
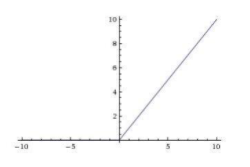
relu函数的梯度分布很均匀,在正区间解决了梯度消失的问题,而且运算十分简便,收敛速度上也比sigmod和tanh快。但是在负区间恒等于0,这代表一旦某个节点输入全为负数,节点值就等于0,梯度也为0.相当于节点死掉。参数永远不会更新。而且relu输出也不是以0为中心。
Leaky Relu and PRelu
Leaky Relu:
PRelu:
f(x)=max(ax,x)
(a一般为0.01-0.1)为0.01时就位Leaky Relu

是 ReLU 激活函数的变体,解决了Relu 函数输出不以0为中心的问题,当 x 小于 0 时,函数值为 ax,有很小的坡度 a,一般为 0.01,0.02,或者可以作为参数学习而得。一定程度上也解决了死节点的问题
对于激活函数的选择:
如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让你的网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU。
最好不要用 sigmoid(在二分类问题的最后输出层可以使用),可以试试 tanh,不过可以预期它的效果会比不上 ReLU。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









