








数据库是什么
mysql数据库是一种基于网络的服务,它基于client,server模式为用户提供数据存储和组织的服务。
在我们下载了数据库后,在linux下,存在mysql(客户端)和mysqld(服务端),用户在客户端中,输入各种指令,这些指令被送到mysqld服务端服务器中,帮我们对数据库进行操作。
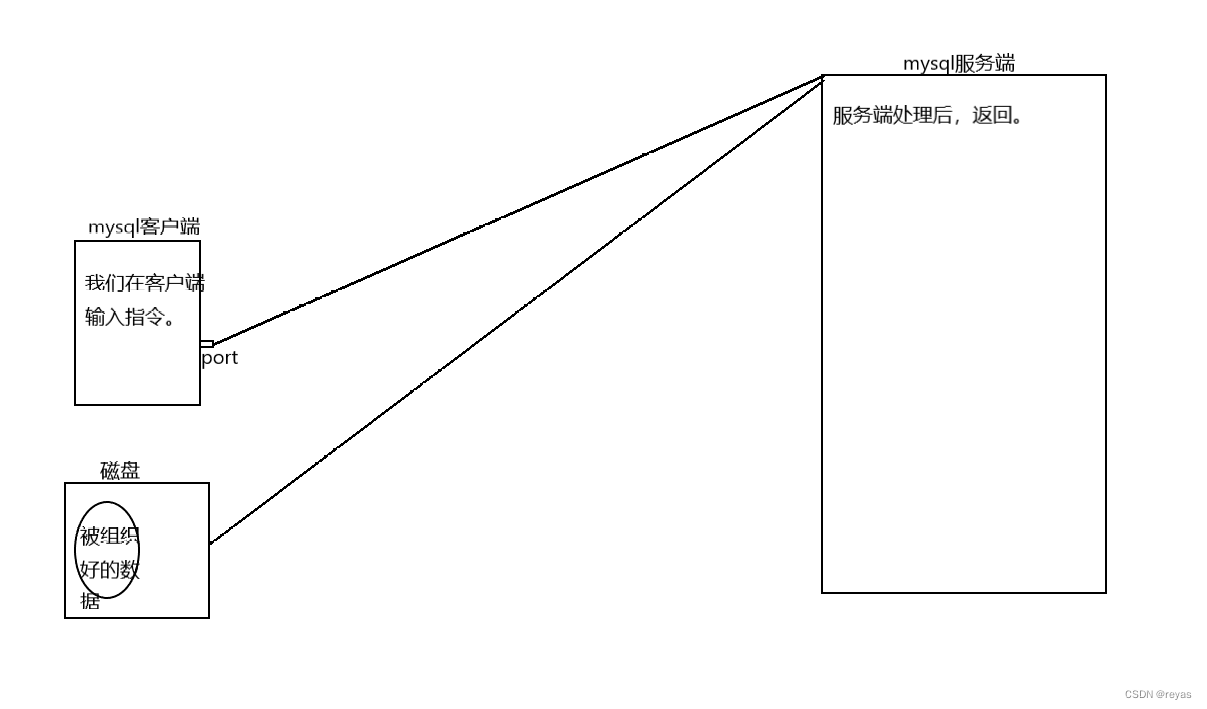
mysql是典型的网络数据库,当然还有非网络数据库如redis
数据库的架构
数据库大概可以分为4层
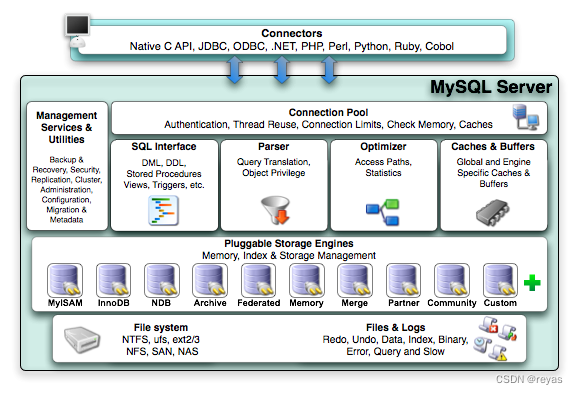
1).connection pool :该层的主要作用是连接处理,身份验证,安全性等等。
2).核心服务层:在SQL处理数据处理服务前,所有的工作都要在该层完成,包括权限判断, sql解析等等。
3).存储引擎层:该层才是真正开始对数据进行处理的层次,可以完成如数据的存取操作,该层存在许多存储引擎,各有优劣,在MySQL中,最常用的是InnoDB,MyISAM。
4).最后一层为文件系统等OS底层,最终数据库操作的也是OS的底层。
所以数据库实际上是用户级的一个程序。
为什么要有数据库
在OS层面,因存在文件系统,文件的管理似乎已经做的很好了,但是在用户层面,并没有很好的管理,这就导致用户操作数据不够方便。
于是便有了数据库,数据库实际上就是在用户层面,给用户提供了良好的操作数据的方法,我们只需要在数据库的客户端输入一些命令,我们就能得到我们想得到的数据,提高了程序员的开发效率。
我们口语中所说的数据库,一是指数据库软件,如mysql,redis等等,二数据库还可以指被数据库软件组织起来的数据,用户不用在意这些数据是如何组织起来的,我们只需要通过数据库的指令操作即可。
如何使用数据库
1.链接数据库
mysql -h[主机ip] -P[链接的端口号] -u[指定链接的用户] -p[输入密码]
主机号和端口号可以不用输入。
退出数据库程序quit指令

数据库中指令类型
1).ddl(数据定义语言),该类语言用于定义数据库的数据类型,如database,table…
2).dml(数据操作语言),该类语言用于操作数据类型,如删除,插入…
3).dcl(数据控制语言),该类语言用于控制数据类型,如给数据库设置副本…
数据库组织结构
数据库实际是由数据库文件夹和表文件组成的。
它们属于从属关系,数据库文件夹内可能存在很多表结构。
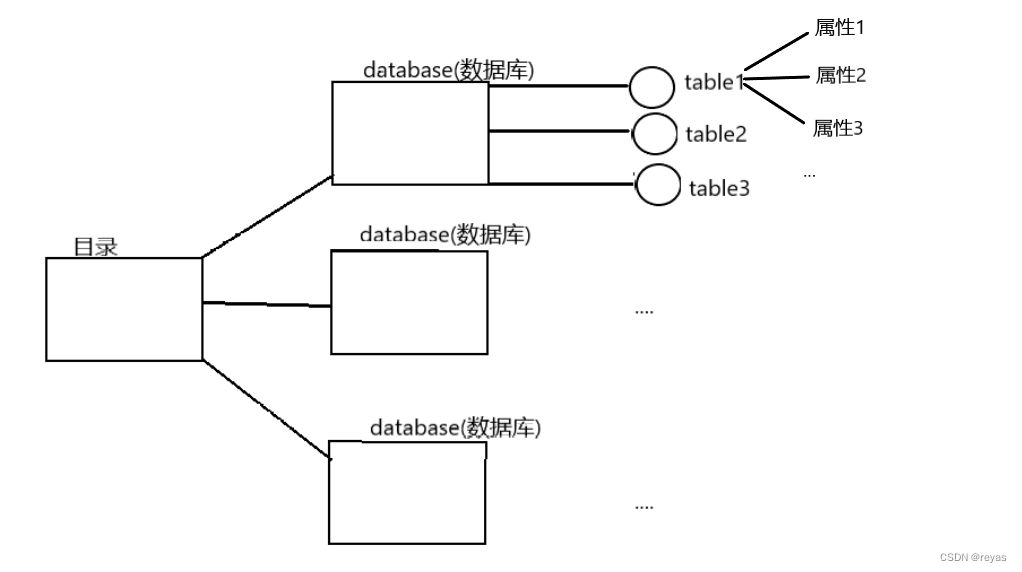
我们层层分析,首先是目录结构,在数据库的配置文件中,已经指明了这些数据放在那里。

在该目录下,我们的Linux中显示的文件和数据库中使用命令显示的数据库文件的关系。
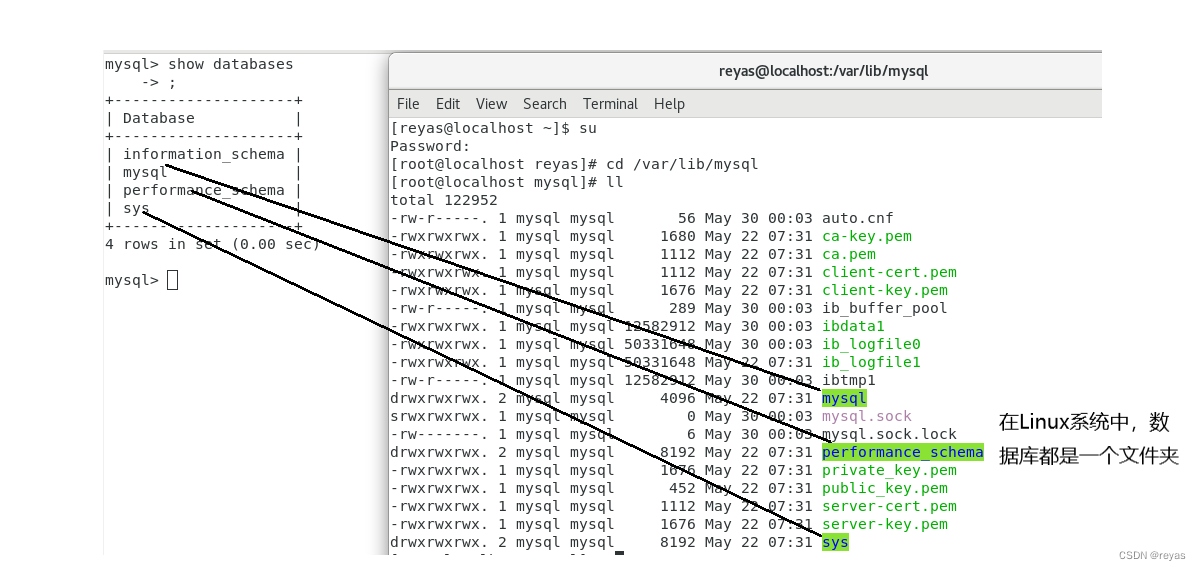
我们可以发现在Linux系统中,数据库都是一个文件夹,那么我们就可以对文件夹进行操作来影响数据库,但我们十分不建议这么做,因为这会导致很多预料之外的问题。
那么数据库中的表在Linux系统下又是什么结构呢?

我们创建了一个测试数据库,并且在该数据库内创建了一个表,我们发现,表中除了操作问文档外,多了两个文件,一个.frm格式,一个.idb格式,这两个都是Innodb数据库引擎为我们创建的文件,当然不同的引擎也会为我们创建不同格式的文件。
数据库的编码
数据库中存在两种编码。
1).数据库编码集。
数据库编码集,代表了未来将数据存入数据库用的是那种编码。
2).数据库校验集。
数据库校验集,代表了未来我们使用,比较…我们使用的编码。
比如我们按照数据库字符大小排序,如果是utf8,则排序分大小写,若是utf8_general_ci,则排序不分大小写。
在每个数据库中,都会存在一个.opt文件,该文件内就存放了当前数据库的数据库编码集和数据库校验集。

实际上在配置文件中,我们也设置了默认的编码集。
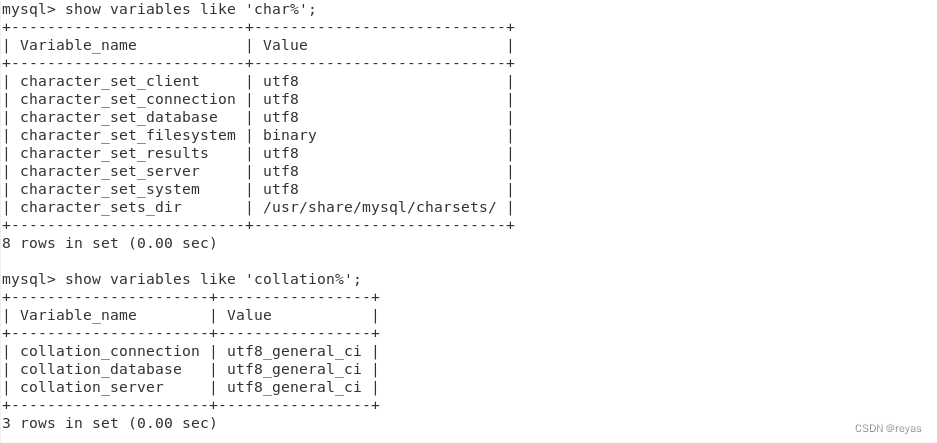
使用 show variables like ‘char% / collation%’ 查看当前数据库,表等编码和校验码。
我们也可以使用show character set / collation查看mysql支持多少种编码集和校验集。
数据库的操作
1).创建
create database (if not exists) name_database;
如果加入()内的,则当名字为name_database的数据库存在时,就不创建。
在创建时,我们也可以指定数据库的编码集和校验码。
create database (if not exists) name_database character set … collate…
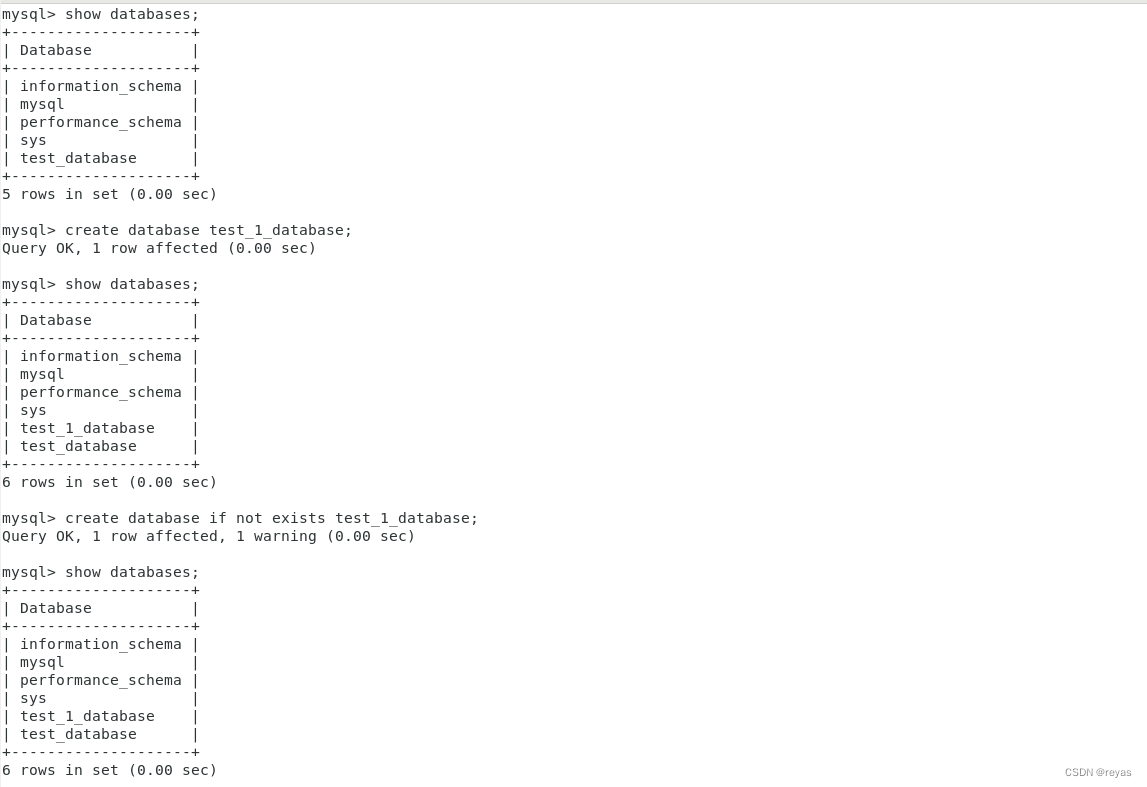

2).展示数据库
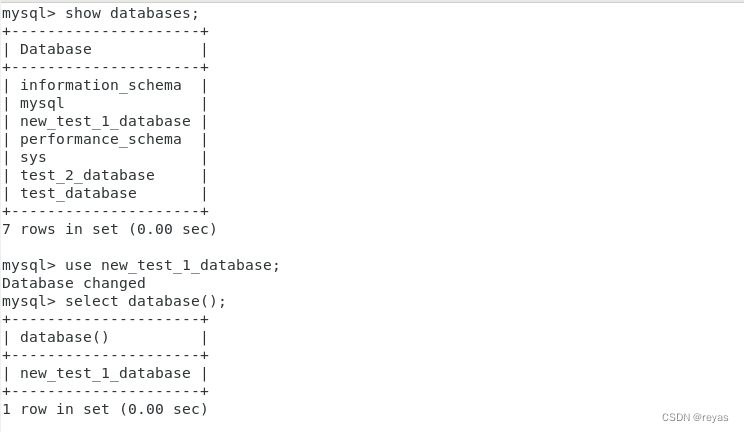
show databases

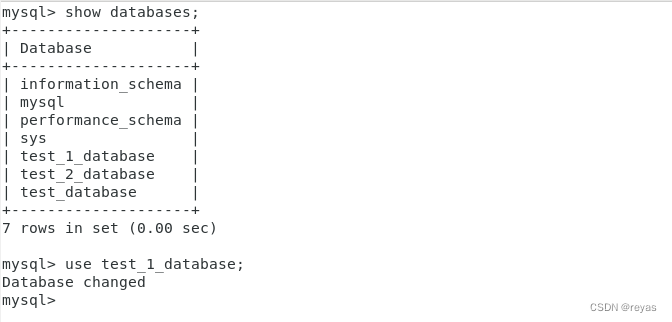
3).我们要对某个数据库操作时,我们先需要进入某个数据库
use name_database;
我们可以通过指令查看我们当前在那个数据库下。
select database();

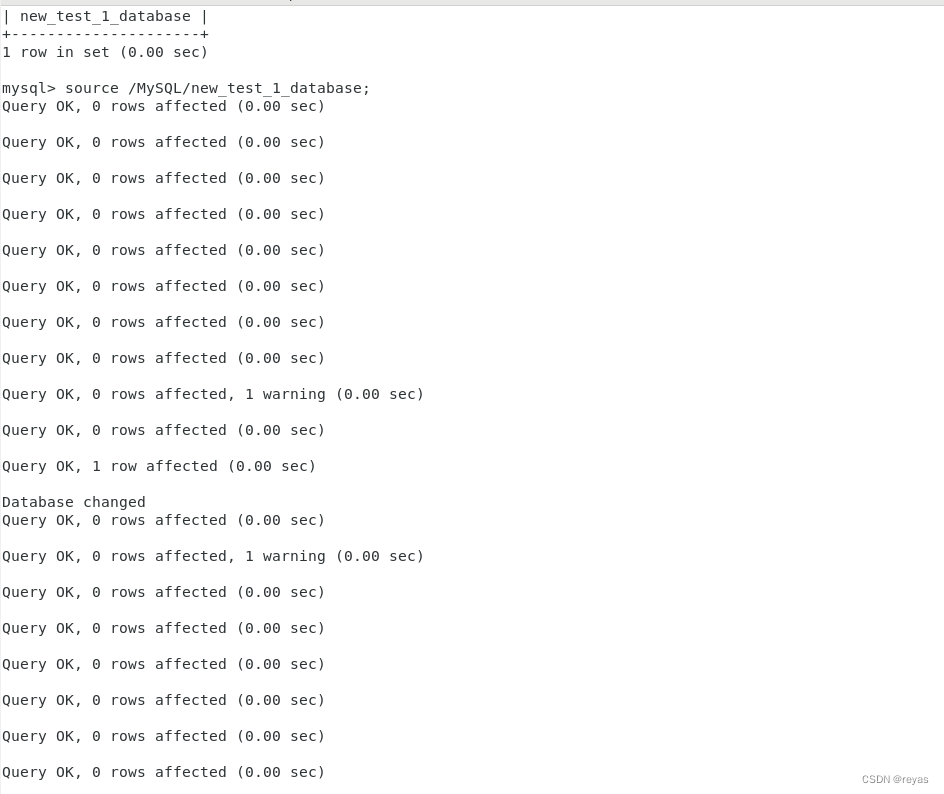
3).修改库
要注意,mysql没有提供修改数据库名字的方法,我们只能通过备份数据库和还原数据库来修改数据库的名字,因为数据库是给用户使用的,如果随便可以修改数据库的名字,则可能会导致上层使用出现问题。
在Linux指令环境下。
mysqldump -P[端口] -u[用户] -p[密码] -B name_database1 > name_database2
恢复库,在Linux环境下
1).mysql -p -u[用户] < path
2).可以在数据库内对库进行恢复,在备份库中,如果不加 -B 选项,则先需要创建数据库,进入数据库,使用指令。
source path;
上述指令也可以用于表。
修改库的编码方式。
alter database name_database character set … collate …;


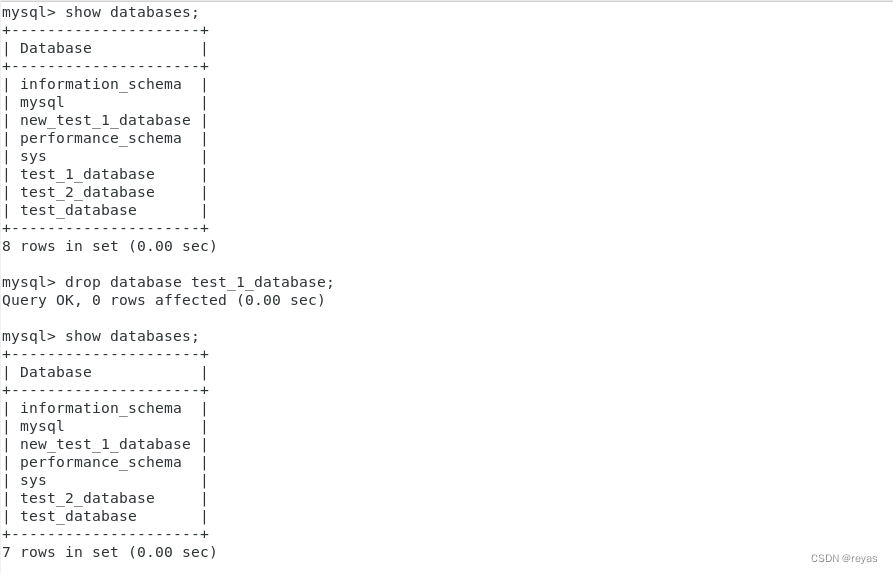
4).删除库
我们最好别删除库,因为可能会导致上层用户使用起来会出现问题。
drop database name_database;
表的操作
表是数据库内的资源组织的基本单位,在Linux系统中,所谓表及代表Linux中的普通文件,不同的SQL引擎,会生成不同类型的文件。
1).表的创建
表是数据库内的数据类型,只能先进入数据库内,才能创建表。
create table (if not exists) name_table(
data1 datatype (comment 'mgs‘),
data2 datatype (comment 'mgs‘),
…
)(character set … collate …);
comment 后可以加入该列的说明信息。
表的每个元素被称为表的属性。

2).展示表
show tables;
展示表的结构
desc name_table;
展示表创建时的信息
show create table name_table (\G);



3).修改表
修改表的名字,虽然可以修改表的名字,但是不建议修改。
alter table o_name rename to n_name;
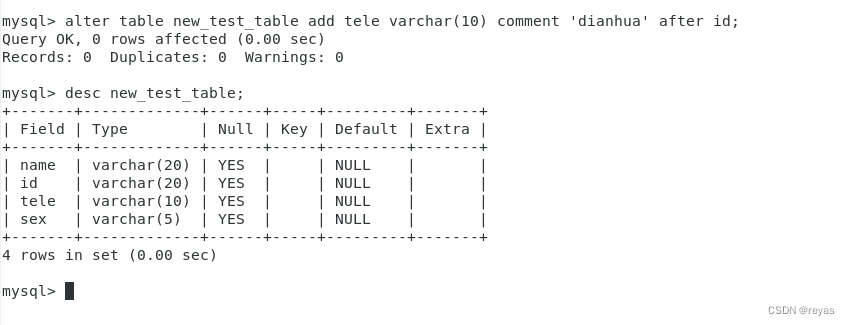
增加一列
alter table name_table add data datatype (comment ‘msg’) after data;
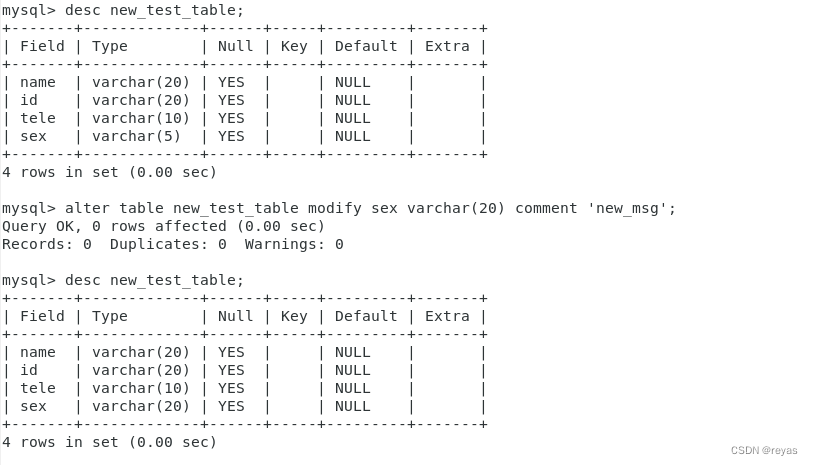
修改一列的属性
alter table name_table modify data new_datatype;
所谓的修改属性,其实是覆盖这个属性,包括之前的comment也会被修改。
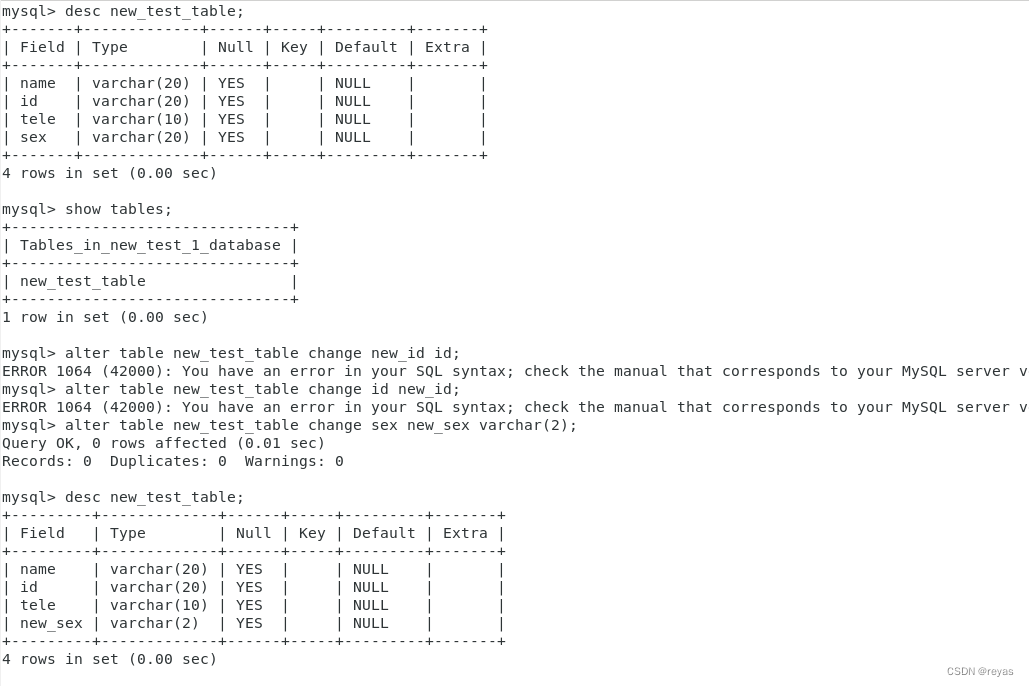
修改一列的名字
alter table name_table change o_name n_name datatype;
删除一列
alter table name_table drop name;

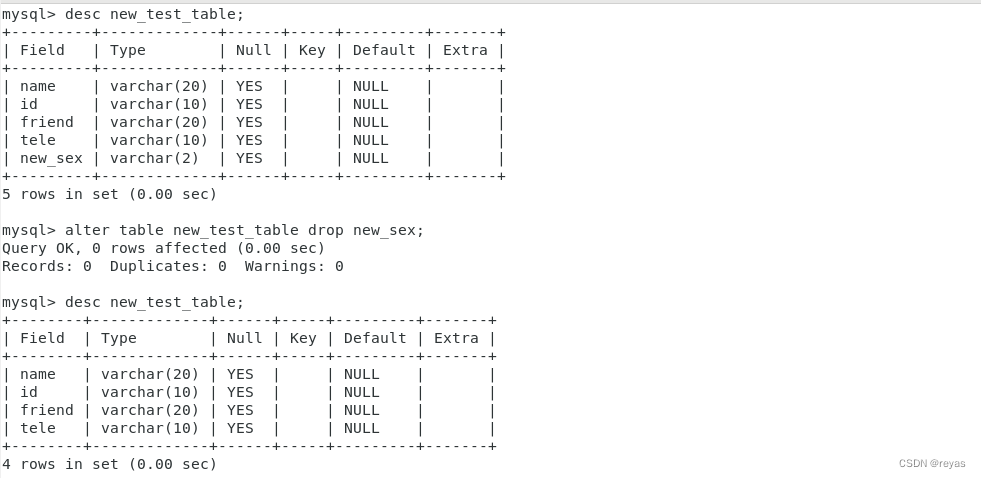
4).删除一个表
尽可能不要删除表
drop table name_table;

总结
1).备份指令可以对数据库和表备份。
2).上述操作只是对数据库和表的属性进行操作。
3).对于数据库的指令,记忆方面,alter代表修改,show代表展示,drop代表删除。















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









