







 本文详细阐述了DataX作业的执行过程,包括Job对象的初始化、全局与局部准备、任务切分、调度分配以及读写操作的具体步骤。DataX在处理不同读写插件时的差异性和通道模型的实现,如channel数量的计算与分配,以及reader和writer的启动、读写数据和后置工作的执行。此外,还介绍了如何通过命令行启动DataX作业以及内部的调度执行机制。
本文详细阐述了DataX作业的执行过程,包括Job对象的初始化、全局与局部准备、任务切分、调度分配以及读写操作的具体步骤。DataX在处理不同读写插件时的差异性和通道模型的实现,如channel数量的计算与分配,以及reader和writer的启动、读写数据和后置工作的执行。此外,还介绍了如何通过命令行启动DataX作业以及内部的调度执行机制。
DataX的执行顺序
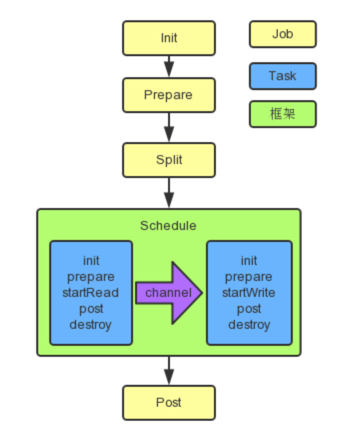
init:Job对象初始化工作,获取与job有关的配置参数等
prepare:全局准备工作,比如清空目标表,清空hdfs目标文件
split:拆分Task
schedule:负责任务的调度分配。
init:task对象的初始化,获取与task相关的配置参数
prepare:局部的准备工作
startRead:从数据源读数据,写到RecordSender中。RecordSender再将数据写入连接Reader和Writer的缓存队列。
channel:Reader和Writer的缓存队列就由其来维护,是Reader和Writer进行数据传输的通道。
startWrite:从RecordReceiver中读取数据。RecordReceiver的数据读取自连接Reader和Writer的缓存队列。
post:局部的后置工作。
destory:task对象的销毁。
post:数据写完后的完善工作
destory:job对象的销毁
DataX一个普通作业的执行流程
一个作业由读写作业组成,不同的读写插件,在作业初始化、作业准备、作业的任务切分、作业的post和作业的销毁等的一些具体细节上是不同的。 这里没有具体到哪个读写插件的流程逻辑,只是大体上的一个流程。
-
命令行执行datax.py脚本,getOptionParser()将配置参数保存起来,然后将参数项和值解析后,交给buildStartCommand生成startCommand,其中一条ENGINE_COMMAND引擎启动指令,就是开启datax引擎的指令。subprocess.Popen()方法将指令通过shell执行。
-
通过command,运行Engine.main(), 调用自身的entry方法,将参数set到配置对象中;
-
Engine.start()依据配置对象生成JobContainer对象,最后调用JobContainer.start()方法,去完成Job的整个工作流程;
-
先执行JobContainer.init(),完成Job对象初始化工作,即reader和writer的初始化。先调用initJobReader方法,在其内部调用相关读插件的init()对reader进行初始化;reader初始化完成之后,用相同的方式初始化writer;
-
接着执行JobContainer.prepare(),全局准备工作,先执行prepareJobReader(),在其内部调用读插件的prepare(),对读进行准备。相同的,调用写插件的prepare(),对写进行准备;
-
然后执行JobContainer.split(),在其中调用adjustChannelNumber,adjustChannelNumber计算Byte和Record的两者限制下的不同channel数量,并取其最小值作为channel数量。如果,Byte和Record都未设置,便启用配置参数中配置的channel数量;都未设置,则为1;但是,有些读插件会根据自身的判断,设置channel数,不会启用前面的方式来获取channel数量。
-
紧接着在JobContainer.split()方法内调用不同Reader的split()方法,并把channel数量作为adviceNumber切片建议数,传递给split();
-
Reader.split(adviceNumber)会依据 不同策略(不同读插件可能不同) 切分出readerTask的数量,大都会切分出大于等于channel的任务数;
-
JobContainer.split()再依据readertask数量调用doWriterSplit,进行writertask的切分,达到切分后两者数目相等,满足1:1的通道模型;
-
切分完成后,由JobContainer.schedule()来调度。先获取每个taskGroup的channel上限数量,由core.container.taskGroup.channel参数指定,如果未指定,则默认为5,再获取needChannelNumber;然后由assignFairly()函数分配任务给taskGroup,分配的方式为轮询。
-
分配完成后,初始化一个scheduler。JobContainer.schedule()中调用scheduler.schedule()方法,依据任务组设置获取各种参数,调用startAllTaskGroup()方法,生成线程池;然后循环调用线程池的execute方法,执行任务,即执行TaskGroupContainerRunner.run()
-
由taskGroupContainer.start()方法启动线程,在其中先获取一些配置参数,开启一个循环,在其中创建TaskExecutor对象,即线程执行器对象。TaskExecutor对象构建时会生成writerThread和readerThread两个线程,在生成每个线程的前一步分别创建recordSender(用来写数据到channel的缓存队列)和recordReceiver(用来读channel的缓存队列)。然后通过taskExecutor.doStart()去执行reader线程和writer线程。
-
先启动writer线程,紧接着启动reader线程,两个线程分别执行他们的init()方法,进行task对象的初始化,获取与task相关的配置参数;
-
接着执行他们各自的prepare()方法,一般都是设置参数等的操作,不同插件可能不同;
-
准备就绪后,调用taskReader.startRead(recordSender)去读取源数据,然后依据数据条数循环通过transportOneRecord()方法生成record,再在transportOneRecord()方法内由recordSender.sendToWriter(record)方法将record写到缓冲区列表内。当列表到达刷写时机,调用flush()方法,将缓冲区内record刷写道channel的queue中。
-
再来看读数据的线程,prepare()方法后,执行taskWriter.startWrite(RecordReceiver),不同插件的的实现大致为连接到写目的地,开启一个循环,调用recordReceiver的getFromReader()方法,该方法首先是排查队列是否为空。如果为空,然后调用receive()方法将数据批量写入 writer 的缓冲区,pull数据的过程中会上锁,pull结束后会解锁。循环直到获取的record为null时结束;
-
写完数据后,读写两个线程执行post,进行局部的后置工作。一般地,读的post大都为空,即没有后置工作;而写的post会涉及到rename的工作;
-
读写任务执行post之后,执行destory,将task对象的销毁;
-
task阶段完成,执行Job的post,进行数据写完后的完善工作,例如,关闭连接,移除配置参数。在post内先执行postJobWriter(),调用对writer作业的post()方法进行写的完善工作;再执行postJobReader(),在内部调用相关readerJob的post(),对读进行善后;
-
最后,执行Job的destory,先执行写作业的destory,再执行读作业的destory,将job对象销毁。


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











