







hadoop 是个平台,关于数据处理的平台。经常做后台数据抓取,处理,解析等coder会深刻理解。
不是好看的游戏,不是有意思的app。它是一搜航母,规模庞大,运维复杂,开销巨量。
运载庞大,处理数据如同排山倒海,翻云覆雨,普通的小服务程序在它面前就是个玩具。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hadoop 1.0
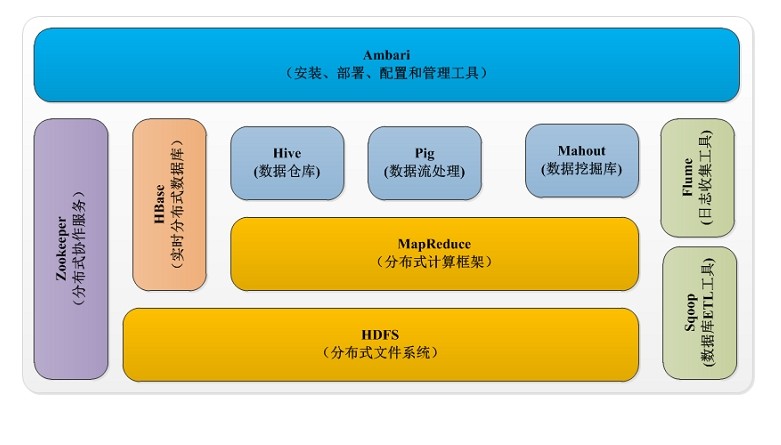
包含内容 HDFS MapReduce Pig Hive Mahout Zookeeper HBase flume sqoop
有意思的是:
HDFS 克隆自 google 2003年发表的GFS。 分布式文件系统 :扩展性 容错性可靠性 PB级数据量
MapReduce 克隆自 google 2004年发表的Googlemapreduce 分布式计算框架:适合离线 (曾有人
要我拿这个做实施计算,汗!) 易编程好扩展PB以上数据处理量。
hive 克隆自 facebook开源的 解决海量结构化日志数据统计问题
基于hadoop的数据仓库: HQL 语言 (类sql) 适合离线分析。
Pig 克隆自 yahoo 的 数据流分析工具 基于hadoop的数据流系统:Pig Latin 适合离线分析。
Mahout 机器学习和数据挖掘的分布式计算框架 (这里是不是很惊喜,算法的平台。)
实现三大算法: 推荐 recommendation 聚类 clustering 分类 classification。
Hbase 克隆自google 2006年发表的bigtable。 需要依托zookeeper 高可靠高性能面向列良好的扩展性
Zookeeper 克隆自google2006年发表的chubby。 统一命名 ,状态同步,集群管理,配置管理。
(作用体现在对于机群扩展的管理,配置状态改变的同步机制)
sqoop 数据库 和 hadoop的桥梁, 导数据的工具。mapreduce计算框架的实践。
flume cloudera 开源项目 日志收集工具:可靠容错 定制 和扩展。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
有意思的点:
1 拥有大数据公司(google最多)的程序产物的进化有不有
2 依次看下来:存数据,批量处理,日志统计工具,算法实现,配置文件管理,导数据,日志管理。
是不是和后台数据处理小程序的步骤很类似有木有
3 都是分布式(所为分布式,就是不在一个机器上分工做同样的事情,典型的工头和农民工模式)的有不有
4 都需要多台机器的有木有,数据量大的有木有,我说是航母级别的平台难道过分吗
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hadoop 2.0
进化理由:
工头 挂掉,工头生病,工头记忆力有限 会导致 农民工 没人管理怎么办? 一代航母只支持一种飞机起飞,别类型飞机起飞肿么办?
mapreduce 是分布式离线计算框架,那我想实施计算框架呢,我想。。。。。。
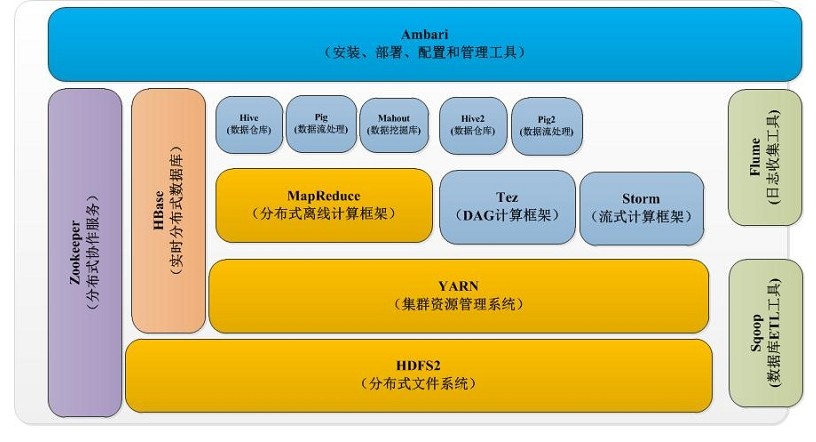
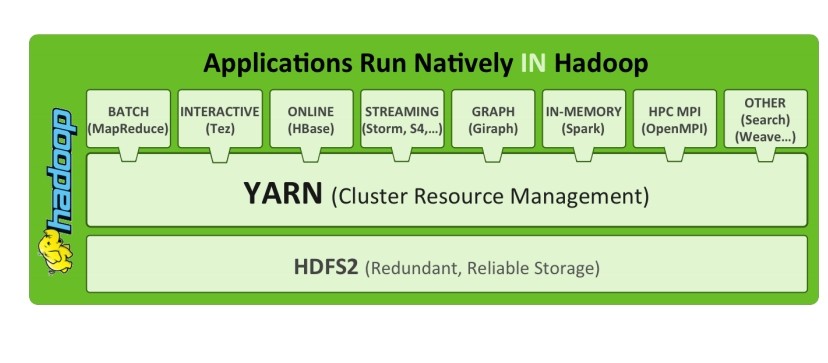
改进方案:在 计算层面 和 数据层面之间 隔离一个 集群资源管理系统 YARN ,从此以后妈妈再也不用担心我想干啥了
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
总结 hadoop 1.0的核心就是 mapreduce 计算框架 和 hdfs 文件系统。2.0的核心就是 mapreduce 计算框架和 其他的计算框架 衔接在 YARN 管理系统之上 再 接上 HDFS。
感觉好难啊,这么多框架,这么多分布式,这么多配置,这么多linux管理操作。好吧,一个馒头一个馒头啃吧。















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









