






上学期数据结构课程学习过程当中,我感觉到希尔排序是高级排序算法中比较好用的一种。他的时间复杂度还是O(n^x)(x>1)形式,理论上感觉并不如归并排序,快速排序,堆排序等更加高大上的 O(nlogn)算法,但在实际应用中他的表现却非常亮眼,写起来也比较方便。这次实验目的为:实现对整数数组进行希尔排序的函数;使用不同的增量序列,测试两种增量序列的性能。
工具及环境:Intellij IDEA community edition
实验过程:
1.使用一个简单的数组,并基于此完成希尔排序的函数。
希尔排序的核心在于“缩短增量”的操作。每一个增量的使用都能够使得数组的无序性下降,从而降低小增量(尤其是最后的1)排序的工作量,极大的提高效率。
希尔排序的发明者对增量序列的选择并未深入研究,他提出的增量序列也是正常思维所容易想到的:数组长度的一半,然后依次减半,直到减到1.依据此序列进行函数的编写。

循环内部的操作类似于插入排序,即对某一个增量值所对应的增量序列分别进行插入排序。注意插入排序中的 j-- 替换为 j-=gap.
使用小数组测试,该函数运行无误。
2.更改增量序列
这个增量序列是最普通,容易想到的。效率更高的增量序列也已经研究出了一些,比较有名的是Hibbard增量和Sedgewick增量(具体内容可以参考Mark Allen Weiss的 “数据结构与算法分析”一书)。这里测试书中所提到的“目前实践中表现最好的”Sedgewick增量序列。推导过程和通项公式从略,这里直接以常数数组的形式给出此序列(前20个数)。
对上面的希尔排序函数略加修改,得到使用新的增量序列的排序函数:

先利用flag找到数组适用的最大增量,然后进行排序,可见只是做了一点微调。使用小数组验证,函数功能实现正确。
3.性能比较:Sedgewick增量真的有用吗?
对两个不同的增量进行测试。主函数生成一个8,000,000个数的随机数组,每个元素在0-999,999,999之间。为了保证实验的公平性,将一个数组的元素拷贝到第二个数组当中,并用两个函数对他们进行分别排序。主函数中对两个函数运行时间进行记录并输出。测试主函数和测试效果如下:

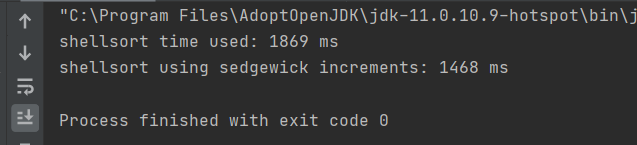
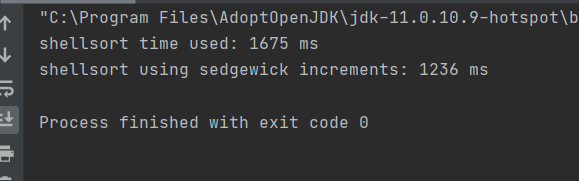
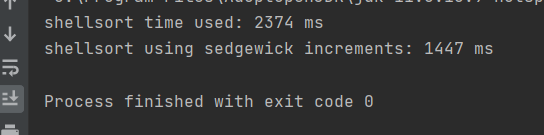
可以看到,Sedgewick增量序列使得排序时间减少了20%以上,个别情况下甚至接近40%。(后面又进行了一些测试,一般都是20%多一点)。
总结:
希尔排序的优越性在这种数据量大,数据复杂的情况下表现仍然十分出色,而且写起来也方便快捷,是值得学习和掌握的。Sedgewick增量序列也体现出相比于常用序列有较明显的性能提升。ps:可以用O(n^2)算法来尝试这个主函数,时间可能要以小时来计算。















 1906
1906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









