







目录
find_element_by_link_text() 源码
find_element_by_partial_link_text() 源码
find_element_by_class_name() 源码:
find_element_by_css_selector()
driver.maximize_window() # 最大化浏览器
driver.minimize_window() #最小化浏览器
current_window_handle() #获得当前窗口的句柄
window_handles() #获得当前所有打开的窗口的句柄
get_window_position # 获得当前窗口的坐标
switch_to_active_element # 返回当前的焦点对象
switch_to_default_content # 嵌套frame操作
switch_to_alert 和switch_to_window的区别?
driver.set_page_load_timeout()
driver.get_screenshot_as_file("D:\\Test\\1.png") # 截图,并设置保存路径
driver.save_screenshot() #保存截图
driver.get_screenshot_as_png() #截图,保存为二进制数据
driver.get_screenshot_as_base64() #截图,保存为base64格式
一 Webdriver介绍
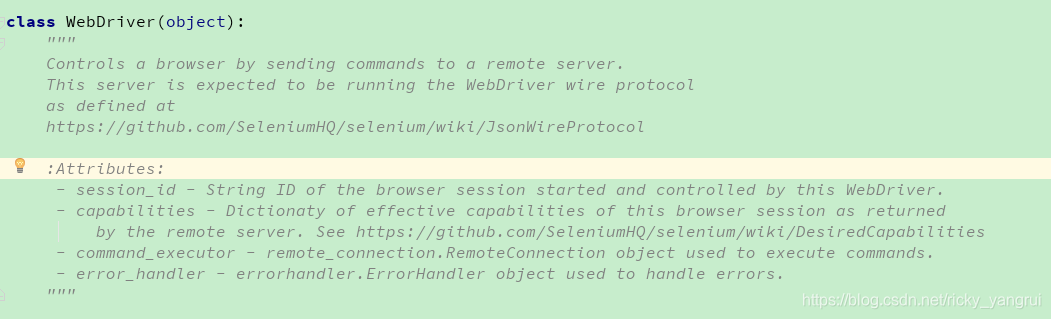
通过向远程服务器发送命令来控制浏览器。
该服务器应该运行WebDriver有线协议
属性:
- session_id - 此WebDriver启动和控制的浏览器会话的字符串ID。
- 功能 - 返回此浏览器会话的有效功能
- command_executor - 用于执行命令的remote_connection.RemoteConnection对象。
- error_handler - 用于处理错误的errorhandler.ErrorHandler对象。
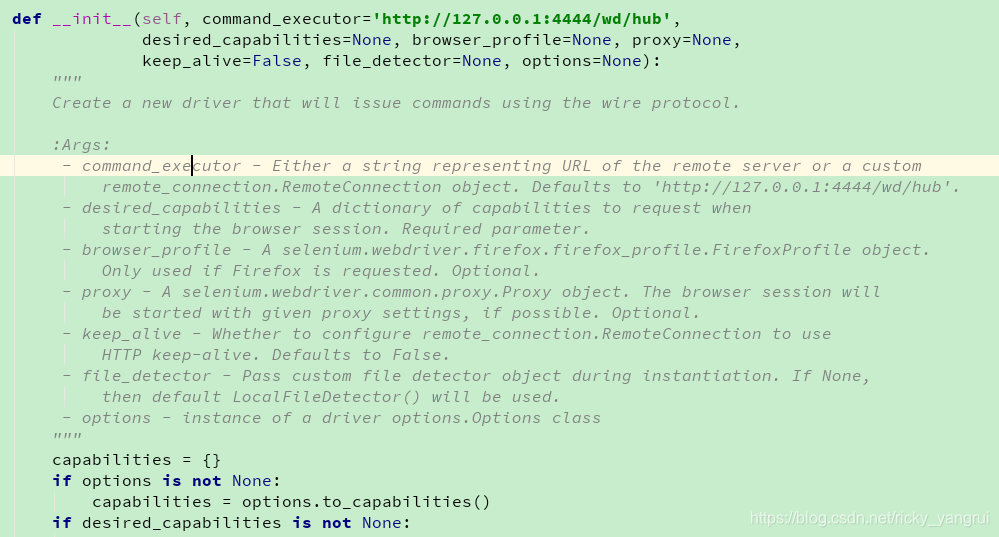
创建一个使用有线协议发出命令的新驱动程序。
:参数数量:
- command_executor - 表示远程服务器的URL或自定义的字符串
remote_connection.RemoteConnection对象。默认为“http://127.0.0.1:4444/wd/hub”。
- desired_capabilities - 请求何时的功能字典
启动浏览器会话。必需参数。
- browser_profile - selenium.webdriver.firefox.firefox_profile.FirefoxProfile对象。
仅在请求Firefox时使用。可选的。
- proxy - 一个selenium.webdriver.common.proxy.Proxy对象。浏览器会话将
如果可能,请使用给定的代理设置启动。可选的。
- keep_alive - 是否配置要使用的remote_connection.RemoteConnection
HTTP保持活跃。默认为False。
- file_detector - 在实例化期间传递自定义文件检测器对象。如果没有,
然后将使用默认的LocalFileDetector()。
- options - 驱动程序options.Options类的实例
二 webdriver实现的原理
关于实现的原理,可以看下这个博主的总结:
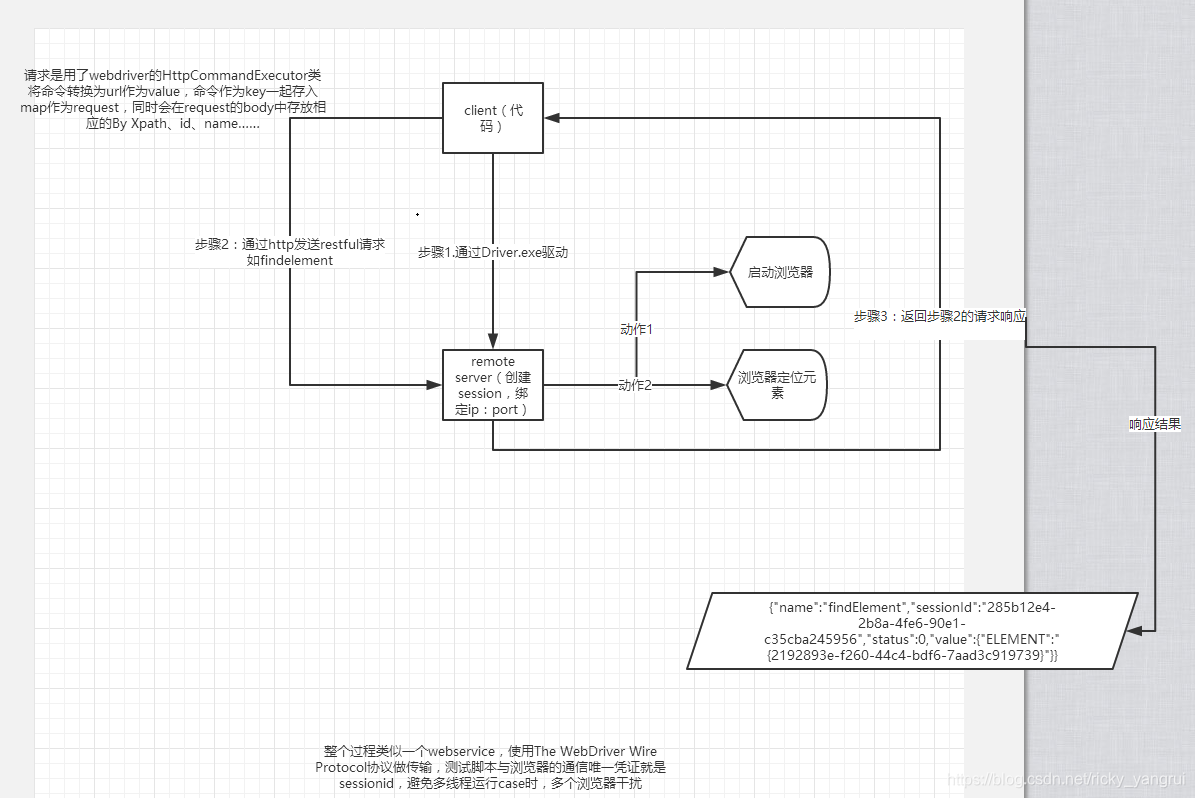
WebDriver 是按照 server – client 的经典设计模式设计的。
server 端就是 remote server,可以是任意的浏览器。当我们的脚本启动浏览器后,该浏览器就是 remote server,它的职责就是等待 client 发送请求并做出相应。client 端简单说来就是我们的测试代码,我们测试代码中的一些行为,比如打开浏览器,转跳到特定的 url 等操作是以 http 请求的方式发送给被 测试浏览器,也就是 remote server;remote server 接受请求,并执行相应操作,并在 response 中返回执行状态、返回值等信息。
webdriver 的工作流程:
1. WebDriver 启动目标浏览器,并绑定到指定端口。该启动的浏览器实例,做为 WebDriver 的 remote
server。
2. Client 端通过 CommandExcuter 发送 HTTPRequest 给 remote server 的侦听端口(通信协议: the
webriver wire protocol)
3. Remote server 需要依赖原生的浏览器组件(如:IEDriverServer.exe、chromedriver.exe),来转化转
化浏览器的 native 调用
webdriver 利用的是驱动来操作浏览器中的页面元素。 具体的过程是这样的,利用各种驱动(谷歌的 chromedriver 等)来控制浏览器 ,这里也就是为什么我们每次新建一个 webdriver 对象时,需要这样定义。driver=webdriver.Chrome() 不同的浏览器需要使用不同的方法,驱动也不一样。然后操作浏览器时使用的是与浏览器之间的通信协议 The WebDriver Wire Protocol 。
每次都使用 json 来传输数据。客户端发送一个 requset,服务器端返回一个 response。代码控制驱动器然后驱动去控制浏览器 然后浏览器完成我们代码的需要的操作。
每次都需要借助一个 ComandExecutor 发送一个命令,实际上是一个 HTTP request 给监听端口上的 Web Service。在我们的 HTTP request 的 body 中,会以 WebDriver Wire 协议规定的 JSON 格式的字符串来告诉浏览器怎么做。
三 API介绍
详细的API介绍,这个从网上找的别人写好的总结,非常棒。

Webdriver 元素的查找的八种方式
- find_element_by_id()
- find_element_by_name()
- find_element_by_class_name()
- find_element_by_tag_name()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_xpath()
- find_element_by_css_selector()
-
find_element_by_id() 源码

例子
driver.find_element_by_id("kw")-
find_element_by_name() 源码

例子:
find_element_by_name("wd")-
find_element_by_link_text() 源码

例子:
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图</a>
find_element_by_link_text("地图")-
find_element_by_partial_link_text() 源码
parial link 定位是对 link 定们的一个种补充,有些文本连接会比较长,这个时候我们可以取文本链接的有一部分定位,只要这一部分信息可以唯一的标识这个链接。

例子:
<a class="mnav" name="tj_lang" href="#">链接非常的长长长哒哒哒哒哒哒多点对点</a>
find_element_by_partial_link_text("链接非常的长")-
find_element_by_tag_name() 源码
Args: tag定位取的是一个HTML页面的 tag(标签) 比如:h1, a, span
缺点:元素很多都是相同的tag,定位会不准确,不推荐使用

-
find_element_by_class_name() 源码:

-
find_element_by_css_selector()

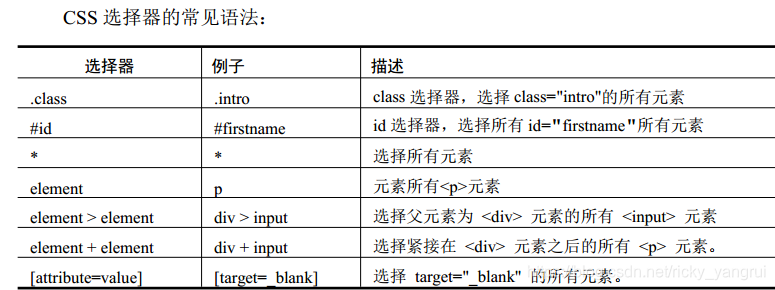
CSS语法:
例子:
find_element_by_css_selector(".s_ipt")
find_element_by_css_selector("#kw")-
find_elements_by_xpath()

例子:
find_element_by_xpath("//input[@id='kw']")-
execute_script() # JS操作
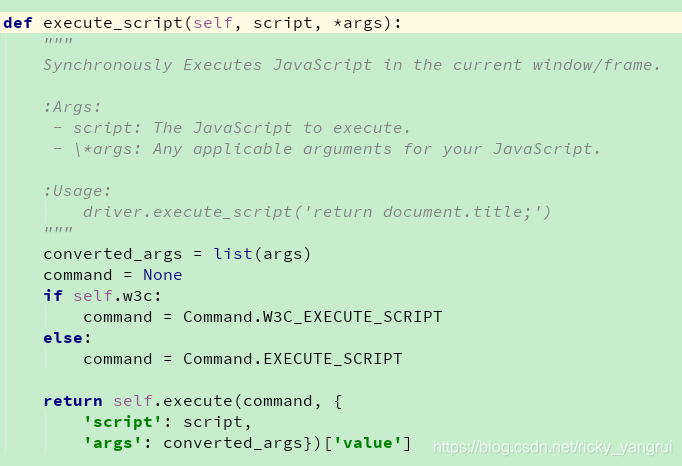
js="return $('#nv a')"
link = driver.execute_script(js)-
复数形式的8中元素查找
- find_elements_by_id()
- find_elements_by_name()
- find_elements_by_class_name()
- find_elements_by_tag_name()
- find_elements_by_link_text()
- find_elements_by_partial_link_text()
- find_elements_by_xpath()
- find_elements_by_css_selector()
四 浏览器的基本操作
-
driver.get() #打开地址

例子:
from selenium import webdriver
driver = webdriver.FireFox()
driver.get("http://www.baidu.com")
-
driver.title 获取title
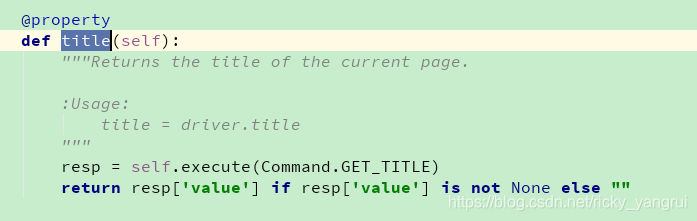
例子:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com/")
time.sleep(1)
driver.find_element_by_link_text("新闻").click()
time.sleep(1)
print (driver.title) # title方法可以获取当前页面的标题显示的字段
-
current_url 获取当前页面的URL

import time
from selenium import webdriver
driver = webdriver.FireFox()
drive.get("htt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}