







引言
shell,我们经常会用到,以其强大的功能,会帮助我们解决很多棘手的问题。最近遇到一个问题,要跑很多case,如果串行的执行,需要很久。能不能让他们并行起来,但又不能所有case都并行运行呢?,因为所有case同时运行,机器会挂掉的。
1,方式1
比较直接的一种方式是,维护两个文件队列(*.start和*.stop)分别记录所有case的运行状态,然后根据并发数量来获取和分配资源。
代码如下:
multi.sh:
#!/bin/bash
#Rill create to run cases parallel
#2014-05-22
#mkdir ./case_status
#declare -i pc_num
readonly pc_num = 3
case_list = "a b c d e f"
function get_start_num()
{
num = 0
for var in $case_list
do
if [ -e $var.start -a -f $var.start]; then
num = num + 1
fi
done
return $num
}
function get_case_stop()
{
case $1 in
"a")
echo "get case: $1 not stop"
rerurn 0
;;
"b")
echo "get case: $1 stop"
return 1
;;
"c")
echo "get case: $1 not stop"
rerurn 0
;;
"d")
echo "get case: $1 stop"
rerurn 1
;;
"e")
echo "get case: $1 stop"
rerurn 1
;;
"f")
echo "get case: $1 stop"
rerurn 1
;;
*)
echo "case $1 not exist"
exit 1;
;;
}
for each_d in ${case_list};
do
if [ get_start_num -lt $pc_num ];then
if [ ! -e $each_d.start ]; then
if [ ! -e $each_d.stop ]; then
touch $each_d.start
#start one new case
else
echo "$each_d already stoped"
rm $each_d.start
fi
else
if [ ! -e $each_d.stop ]; then
echo "$each_d running......"
if[ get_case_stop $each_d eq 1];then
touch $each_d.stop
rm $each_d.start
fi
else
echo "$each_d error!"
fi
fi
fi
done需要注意的是采用这种方式的话,需要获得每个case的结束状态,这个可以通过case运行结束时的输出log中分析得到。
虽然有awk等强大的工具,但是,分析获得不同case的结束信息仍然是一项艰巨的任务。
有没有其他的方式呢?
有。
2,方式2
仔细分析所有的cases开始,结束的情景,发现和fifo文件的特性很类似,于是就想到用fifo来实现并发控制。
如下:
multi.sh:
#!/bin/bash
#Rill create to run cases parallel
#2014-05-22
case_list="a b c d e f g h i j k l m n o"
readonly parallel_num=3
readonly fifo_id=9
readonly fifo_name=fd2
readonly log_name=log.log
#create log file
if [ -e ${log_name} -a -f ${log_name} ];then
rm -f ${log_name}
fi
touch ${log_name}
echo "all cases begin time:$(date +%Y-%m-%d-%H:%M:%S)" >>${log_name}
#create fifo file
if [ -e ${fifo_name} -a -f ${fifo_name} ];then
rm -f ${fifo_name}
fi
mkfifo ${fifo_name}
#bind fifo to fifo_id
eval "exec ${fifo_id}<>${fifo_name}"
#init fifo
for (( idx=0;idx<${parallel_num};idx=idx+1 ))
do
echo -n -e "1\n" >>${fifo_name}
done
#multi main body
for each_case in ${case_list};
do
read -u ${fifo_id}
{
echo "${each_case} start:$(date +%Y-%m-%d-%H:%M:%S)" >>${log_name}
sleep 1 #case running
echo "${each_case} stoped:$(date +%Y-%m-%d-%H:%M:%S)" >>${log_name}
echo -ne "1\n" >>${fifo_name}
} &
done
#wait all the cases stoped
wait
echo "all cases finish time:$(date +%Y-%m-%d-%H:%M:%S)" >>${log_name}
#remove the fifo
rm -f ${fifo_name}
从中可以发现,我们不需要再为获得case的结束状态而烦恼了。
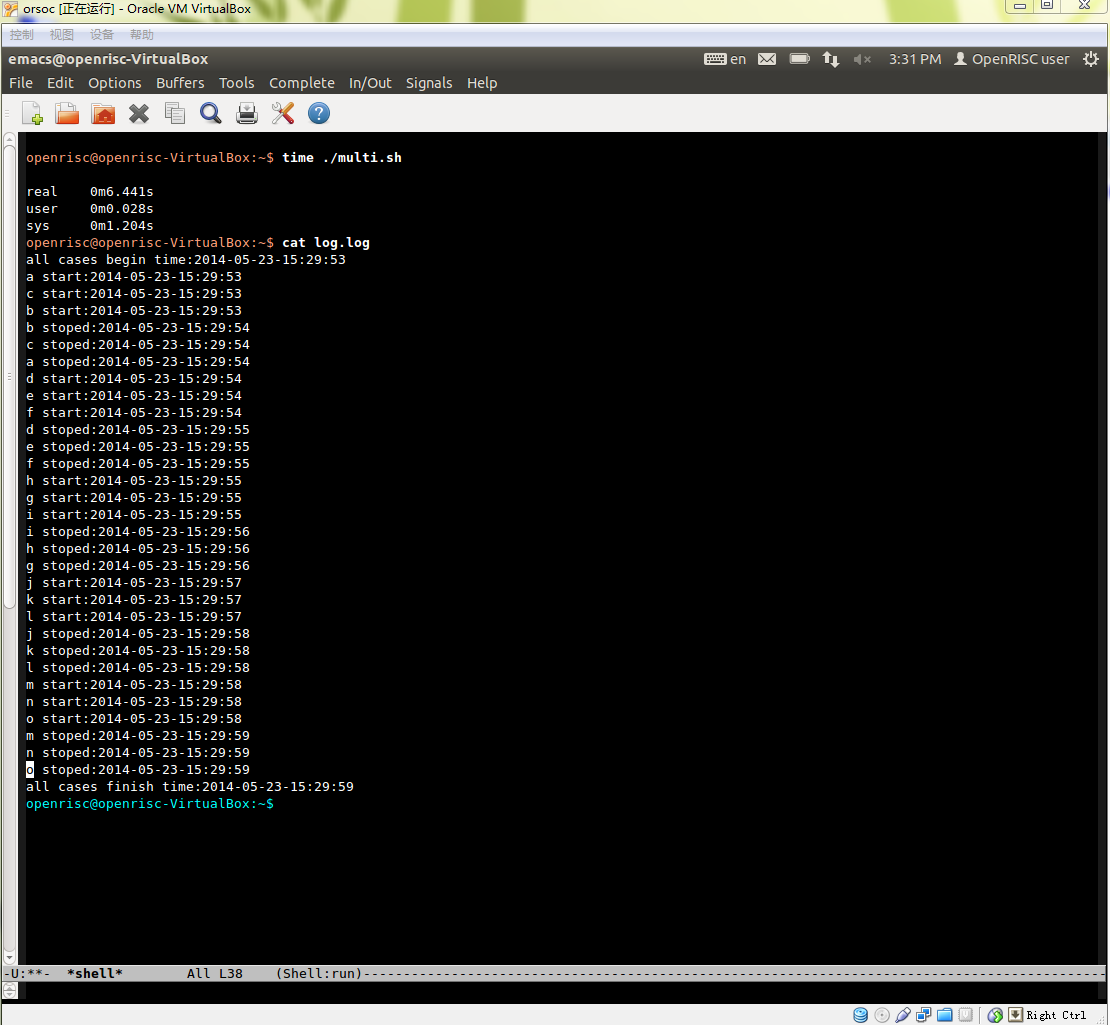
下面是运行结果,一共15个case,每个case运行1秒,并发数量设置为3,所有case运行完需要6.4秒左右。
3,shell参数传递
平时我们在使用shell脚本时,往往要向脚本中指定参数,这些参数可以直接写在命令行的后面,但是这样做对参数顺序要求很强,使用起来比较困难。
这时我们可以通过在参数前面增加标示来实现。
#!/bin/bash
#
# shell test
# Rill
# 2014-09-28
opr1=x
opr2=x
opr3=x
while [ -n "$(echo $1 | grep '-')" ];do
case $1 in
-h | --help)
echo "./test.sh -opr1 a -opr2 b -opr3 c"
exit 0
;;
-opr1)
opr1=$2
shift
;;
-opr2)
opr2=$2
shift
;;
-opr3)
opr3=$2
shift
;;
esac
shift
done
echo "opr1=${opr1} opr2=${opr2} opr3=${opr3}"
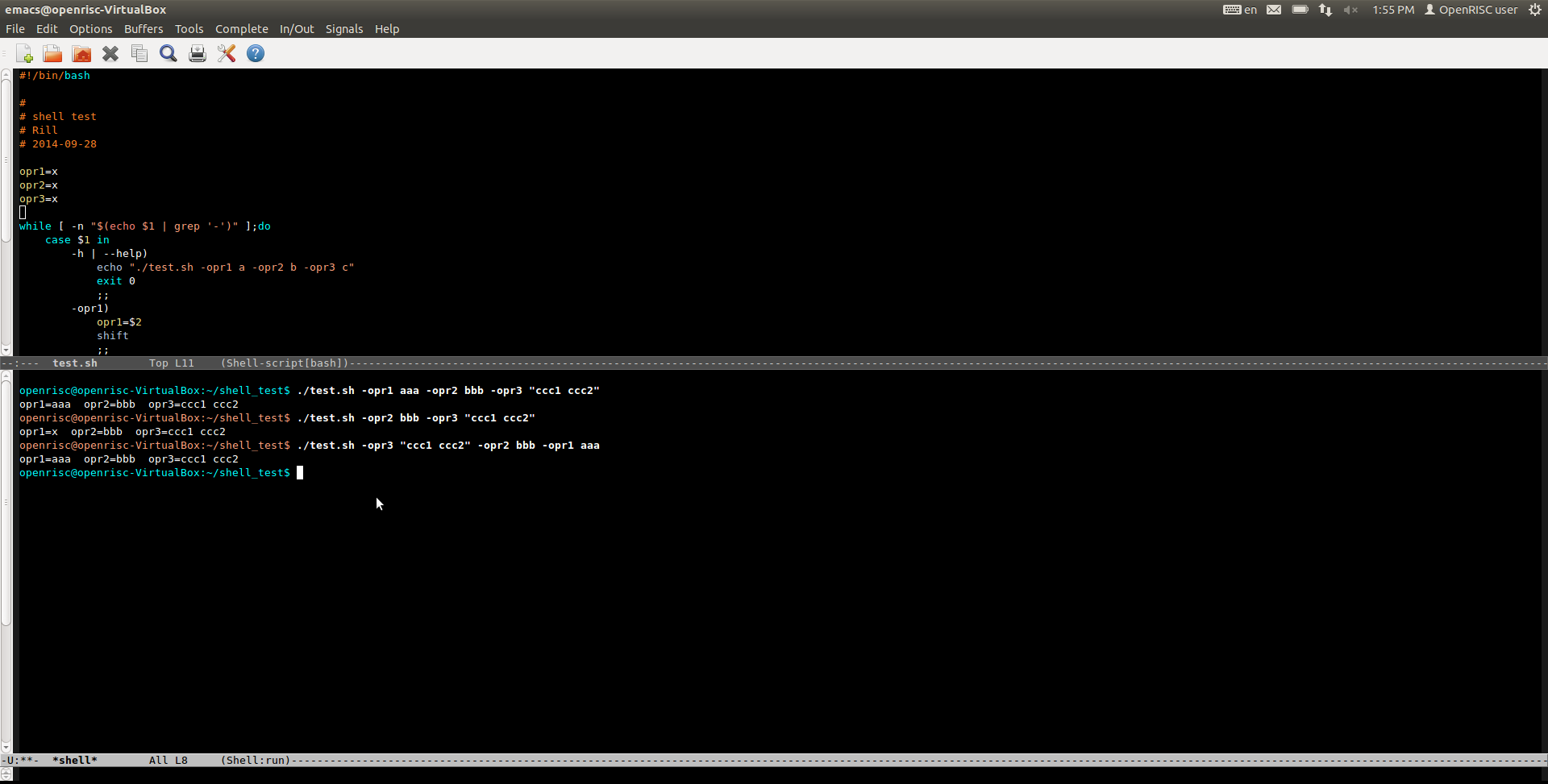
验证结果:
4,小结
shell很久都不用了,本小结就当“朝花夕拾”吧。















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









