









文章目录
1. Spark Streaming中的离散流特征
- Spark Streaming 处理单位是数据片段,又称作离散数据流。每次处理的数据片段会被Spark Streaming包装成不可变的RDD推送到Spark内核进行处理,应用代码基于每次处理的单个数据片段来执行Job,即一个数据片段对应一个RDD,而一个RDD则对应一个被Spark Streaming封装的Job实例,RDD的模板类称为离散流类即DStream。
- 实际上,Spark Streaming是针对流式处理的特征对Spark内核的一种RDD封装,以时间为分片将拉取的离散数据流封装为一系列独立的RDD实例,封装的离散RDD之间彼此独立,相互之间无任何关系,离散数据流是一种无状态流。
2. Spark Streaming统计Socket出现数据个数
功能:设置时间间隔扫描Socket端口源数据,并将拉取到的数据进行打印和统计个数。
package streaming;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
public class SocketToPrint {
public static void main(String[] args) throws InterruptedException{
SparkConf conf = new SparkConf();
conf.setMaster("local[*]");
conf.setAppName("WordCountOnLine");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
//Joblines属于离散流集合,对应于一个特定的时间片段收集的数据记录行
JavaReceiverInputDStream<String> JobLines = jsc.socketTextStream("master001", 9999);
JobLines.foreachRDD(new VoidFunction<JavaRDD<String>>() {
public void call(JavaRDD<String> stringJavaRDD) throws Exception {
long size = stringJavaRDD.count();
System.out.println("-----foreachRDD-call-collection-size:"+size+"---------");
stringJavaRDD.foreach(new VoidFunction<String>() {
public void call(String s) throws Exception {
System.out.println(s);
}
});
}
});
jsc.start();
System.out.println("-----already start------");
jsc.awaitTermination();
System.out.println("-----already await------");
jsc.close();
System.out.println("-----already close------");
}
}
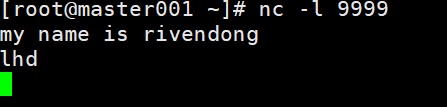
在master001节点启动9999端口
nc -l 9999
然后输入,得出如下结果:


3. Spark Streaming扫描socket端口数据并写入HDFS当中
package rdd;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.*;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author lhd
*/
public class RDDToHdfsJson {
private static FileSystem fs;
private static final String HDFS = "hdfs://master001:9000";
static{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
try {
fs = FileSystem.get(new URI(HDFS), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RDD To HDFS Cluster");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(SparkSession.builder().sparkContext(sc.sc()).getOrCreate());
Dataset<Row> userDataSet = sqlContext.read().format("json").load(HDFS + "//spark//input2//user.json");
userDataSet.show();
}
}

4. Spark Streaming以I/O流的形式写入HDFS
package streaming;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Iterator;
public class SocketToHDFS2 {
private static int count;
private static FileSystem fs;
private static final String HDFS = "hdfs://master002:9000";
static {
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
try {
fs = FileSystem.get(new URI(HDFS), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
private static void saveLine(Iterator<String> its) throws IOException{
Path outFile = new Path(HDFS + "//spark//streaming//output2" + "//part-" + count++);
FSDataOutputStream dos = fs.create(outFile, true);
try {
while(its.hasNext()){
String line = its.next();
dos.writeUTF(line + "\n");
}
dos.flush();
}finally {
dos.close();
}
}
public static void main(String[] args) throws IOException, InterruptedException{
Path output = new Path(HDFS + "//spark//streaming//output2");
if(fs.exists(output)){
fs.delete(output, true);
}
boolean flag = fs.mkdirs(output);
if(!flag) return;
SparkConf conf = new SparkConf();
conf.setMaster("local[*]");
conf.setAppName("WordCountOnLine");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
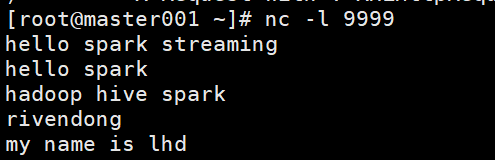
JavaReceiverInputDStream<String> JobLines = jsc.socketTextStream("master001", 9999);
JobLines.foreachRDD(new VoidFunction<JavaRDD<String>>() {
public void call(JavaRDD<String> stringJavaRDD) throws Exception {
long size = stringJavaRDD.count();
System.out.println("-----foreachRDD-call-collection-size:"+size+"---------");
if(0 == size) return;
stringJavaRDD.foreachPartition(new VoidFunction<Iterator<String>>() {
public void call(Iterator<String> stringIterator) throws Exception {
saveLine(stringIterator);
}
});
}
});
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









