1.算法简述
分类是指分类器(classifier)根据已标注类别的训练集,通过训练可以对未知类别的样本进行分类。分类被称为监督学习(supervised learning)。如果训练集的样本没有标注类别,那么就需要用到聚类。聚类是把相似的样本聚成一类,这种相似性通常以距离来度量。聚类被称为无监督学习(unspervised learning)。
k-means是聚类算法中常用的一种,其中k的含义是指有k个cluster。由聚类的定义可知,一个样本应距离其所属cluster的质心是最近的(相较于其他k-1个cluster)。实际上,k-means的本质是最小化目标函数:
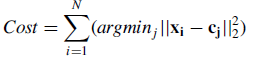
x为样本点,c为cluster。为了表示cluster,最简单有效的是取所有样本点平均,即质心(cluster centroid);这便是取名means的来由。
k-means算法流程如下:
选取初始k个质心(通常随机选取)
循环重复直至收敛
{ 对每个样本,计算出与k个质心距离最近的那个,将其归为距离最新质心所对应的cluster
重新计算质心,当质心不再变化即为收敛
}
代码参考[1,2],结果可视化请参考[2]
- import numpy as np
- import scipy.spatial.distance as ssd
- import matplotlib.pyplot as plt
-
- def read_file(fn):
- raw_file=open(fn)
- dataSet=[]
- for raw_row in raw_file.readlines():
- row=raw_row.strip().split('\t')
- dataSet.append((float(row[0]),float(row[1])))
-
- return np.array(dataSet)
-
- def firstCentroids(k,dataSet):
-
-
- num_columns=dataSet.shape[1]
- centroids=np.zeros((k,num_columns))
- for j in range(num_columns):
- minJ=min(dataSet[:,j])
- rangeJ=max(dataSet[:,j])-minJ
- for i in range(k):
- centroids[i,j]=minJ+rangeJ*np.random.uniform(0,1)
- return np.array(centroids)
-
- def kmeans(k,dataSet):
- num_rows,num_columns=dataSet.shape
- centroids=firstCentroids(k,dataSet)
-
-
- clusterAssment=np.zeros((num_rows,2))
- clusterChanged=True
- while clusterChanged:
- clusterChanged=False
-
-
- for i in range(num_rows):
- minDis=np.inf;minIndex=-1
- for j in range(k):
- distance=ssd.euclidean(dataSet[i,:],centroids[j,:])
- if distance<minDis:
- minDis=distance;minIndex=j
-
- if(clusterAssment[i,0]!=minIndex): clusterChanged=True
- clusterAssment[i,:]=minIndex,minDis**2
-
-
- for cent in range(k):
- ptsInCent=dataSet[np.nonzero(clusterAssment[:,0]==cent)[0]]
- centroids[cent,:]=np.mean(ptsInCent,axis=0)
-
- return centroids,clusterAssment
缺点:
- k-means是局部最优,因而对初始质心的选取敏感。换句话说,选取不同的初始质心,会导致不同的分类结果(当然包括差的了)。
- 选择能达到目标函数最优的k值是非常困难的。
2. Referrence
[1] Peter Harrington, machine learning in action.
[2] zouxy09, 机器学习算法与Python实践之(五)k均值聚类(k-means).
[3] the top ten algorithm in data mining, CRC Press.






















 9135
9135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









