






1. 要关注的问题
2. 解决问题的传统方法
3. 传统方法的优化以及优化过程中问题
4. Hadoop是什么?Hadoop中的HDFS、MapReduce与HBase。
5 利用HBase如何解决要关注的问题
1. 要关注的问题
青岛高信大网关和庚顿实时数据库都要面对的一个问题就是海量数据的高效存储、管理与分析。
海量数据的概念?站在实时数据库历史数据存储的角度来说,海量数据的概念不是实时数据库中包含的数以十万计、百万计甚至是千万计的测点,而是历史数据存储需要面对的成百上千G字节, 甚至是以T为单位的巨型存储文件。对于多级部署方式的数据库,越靠近顶端承载的数据量也就越大 ,在行业应用中因为一系列技术的突破带来了数据爆炸性的增长,测点数量不断增多 、测点刷新频率不断加快 、数据在线时间不断延长,从而使历史数据文件的容量轻而易举的突破百G、千G甚至是几十几百T字节。当单服务器模式无法承载如此大量的数据文件,而带来的一系列问题,如数据文件创建缓慢、管理低效、备份困难,读写耗时。那么分布式存储应用解决方案自然地走到我们面前。
2. 解决问题的传统方法
对于要处理动辄T级字节大小的文件,单个网关、单个数据库、单个服务器往往很难满足要求,所以采用多个网关、多个数据库、多台服务器联合部署方式,实现所谓的“群集数据库”。群集数据库一般由若干个实时/历史数据库和一个测点关系库组成,对外提供统一的访问接口,同时能够实现对测点位置、测点数据访问接口透明,即应用访问测点时无须关心测点具体存储在哪个数据库实体上,群集数据库是逻辑意义上的数据库。通过群集数据库的设计方式可以解决测点不断扩展等问题,但是解决不了巨型数据文件的问题。同时对于单库吞吐率的也没有帮助。数据库测点数量与历史数据文件的大小直接决定了分布式存储建设规模,特别是数据库服务器的配置数据量。
假设单台服务器能够支持的测点容量为X(测点容量与具体数据库产品有关),同时实时数据库服务器采用主备方式运行,某阶段建设时估算的所有测点数量为Y(包括了测点容量裕度), 则此阶段所需的数据库服务器数量为(INT(Y/X)+1)* 2。
例如:一个实时/历史数据库的最大测点容量为20万,某应用的所有测点数量为100万,则所需服务器的数量为(INT(100/20)+1)*2=12。
还是同样的应用场景,一个20万点数据库,设置为不压缩,不算索引文件和卫星数据,每秒钟数据全刷新一次,所产生的数据量为( 8B V + 2B Q +8B T)*200 000 = 3.4MB , 每年产生的数据量102TB,在这样的场景之下, 单服务器处理数据的能力迅速下降。可见简单的 “群集数据库”不能解决数据文件不断膨胀带来的单服务器处理能力不足的问题。
在建设的不同阶段,硬件配置的变化主要取决于接入测点数量的变化,因此在从速赢向基本成型进阶, 或者从基本成型向完善优化阶段进阶时,除了功能和应用的不断丰富以外,需要充分考虑由于测点增长、刷新频率高、在线时间长引起的数据库服务器的增加,以实现平滑升级。
3. 传统方法的优化以及优化过程中问题
对于简单的传统“群集数据库” ,随着测点量增加、刷新频率增高、在线时间长造成的单服务器数据文件负载过重的问题,除了在系统建设初始阶段做好规划外,在系统运行维护阶段可以采取类似关系数据库中分表的方法,把承载巨大数据文件的单个服务器中的实时/历史数据库的测点表、数据文件进行拆分。
“群集数据库”与生具来的一个特点是使用了多个硬件,其中任一硬件发生故障的几率将会变得非常高,避免数据丢失的方法是使用备份,使用磁盘阵列RAID是一种可选的方法。
“群集数据库”需要用某种方式结合大部分数据共同完成用户任务。即从一台服务器上读取的数据可能需要从另外N台服务器中读取的数据结合使用。结合多个来源的数据并实现分析,保证其正确性是一个非常大的挑战。
“群集数据库”在分布式的计算环境下,协调各进程的执行是一个很大的挑战,最困难的是合理的处理系统部分失效,程序员必须利用底层次的功能模块如套接字和高层次的数据分析算法控制数据流,显式的管理自身的检查点和恢复机制。“群集数据库”将更多的控制权交给了程序员,但也增加了编程的难度。
“群集数据库”每个节点采用双机备份,硬件资源浪费严重。同时也非常容易出现机器与机器之间磁盘利用率不平衡的情况,整个系统的性能受制于资源负载率最高的机器,也不会因为集群中机器的数量增加,而使集群的整个性能得到提升 。
4. Hadoop是什么?Hadoop中的HDFS、MapReduce与HBase。
今天,我们可以从很多渠道获取到Hadoop的信息,Hadoop可以做什么、Hadoop适用什么场合、Hadoop的技术实现。这些内容在互联网上有很多的资料可供查询。通过相关技术资料不难看出,Hadoop是一个分布式计算基础架构这把“大伞”下的相关子项目集合,这些项目数据Apache软件基金会,或者为开源软件项目社区提供支持。这些子项目可以简化表示为:
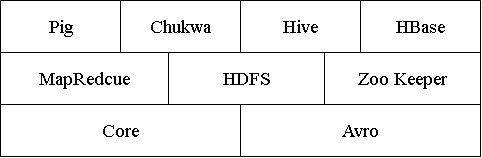
Core
一系列分布式文件系统和通用I/O的组件和接口
Avro
一种提供高效、跨语言RPC的数据序列系统,持久化数据存储。
MapReduce
分布式数据处理模式和执行环境,运行于大型商用机集群。
HDFS
分布式文件系统,运行于大型商用机集群。
Hbase
一个分布式的、列存储数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
在群集系统中, Hadoop主要解决了两个问题:
一、硬件故障
在故障发生时,可以使用数据的另一份副本。这就是冗余的磁盘阵列的工作方式。Hadoop的文件系统HDFS就是一个例子,虽然它采取的是另一种稍有不同的方法
二、任务的并行计算
不同的分布式系统组合多个来源的数据,在保证正确性方面,MapReduce提供了一个编程模型,气抽象出上磁盘读写的问题,将其转换为计算一个由成对key/value组成的数据集。
简而言之,Hadoop提供了一个稳定的共享存储和分析系统。存储由HDFS实现、分析由MapReduce实现。纵然Hdoop还有其他功能,但这些功能是它的核心所在。在实时数据库历史存储和大网关上Hbase是一个可使用、可改造、可扩展的基于开源分布式文件系统的数据库。
但是,虽然HDFS和MapReduce是用于对大数据集进行批处理的强大工具,但对于读或者写单独的记录,效率却很低。Hadoop是一个完成的生态圈,HBase正是用来填补它们之间的鸿沟。
5 利用HBase如何解决要关注的问题
对于实时/历史数据库和青岛高信要开发的大网关,采集的数据要包含越来越长的在线时间的上十万甚至百万、千万的传感器采集数据,这个数据集一直继续增长,它的大小几乎是无限的。在我们要构建的系统中来让各种应用进行更新、查询。为此,我们可以假设数据集非常大,采集数据达到上亿条记录,且采集数据到达的速度很快,不仅如此,构建的应用必须能够满足及时查询到采集的数据。即在收到数据后大约1秒能查询到结果。
对于数据集的第一个特性使我们排除了使用RDBMS产品,而可能选择HBase。对于第二个要求排除了直接使用HDFS。MapReduce作业可以用于建立索引以支持对采集数据进行随机访问,但HDFS和MpaReduce并不擅长在有更新到达时维护索引。
根据庚顿在实时数据库开发领域多年的经验,成熟稳定的Golden V2.0是在基于Windows系统上利用了大量COM技术、文件内存交换技术的单机服务器模式。Golden V2.0在单机系统上性能优秀,但是要单纯的将其中的历史存储模块独立分离出来,或者用Golden实时数据库构建“分布式群集”数据库,会有第三节涉及到的问题存在。所以排除了从零开始重新开发或者改造现有数据库的方法。
对于历史数据存储,在HBase中应该如何设计它的模式?(以下涉及的概念和术语,均可在google发布了一篇相当详细的论文“Bigtable: A Distributed Storage System for Structured Data ”中有解释) 。在我们的系统中,至少有两个表History 、 Section 。
Histroy
这个表存放实时部分传递的数据。行的主键是测点ID和逆序时间戳构成的组合键,这个表有一个列簇data,它包含列value , quality 。这样同一个测点ID收到的数据就会被分组放到一起,使用逆序时间戳的二进制存储,系统把每个测点的最新数据存储在最前面。行主键, HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描,因此Row key需要根据业务来设计以利用其存储排序特性提高性能。
| Row Key | Timestamp | data |
| 0000001 | 13171790000001 | data:value = 1.2f , data,quality= 0 |
| 13171790000002 | data:value = 1.3f , data,quality= 0 | |
| 13171790000003 | data:value = 1.4f , data,quality= 0 | |
| 0000002 | 13171790000001 | data:value = 1.3f , data,quality= 0 |
| 13171790000002 | data:value = 1.1f , data,quality= 0 | |
| 13171790000003 | data:value = 1.1f , data,quality= 0 |
Section
这个表存放断面的历史数据。行的主键是测点时间戳,这个表有一个列簇data,它包含列以测点ID为列名 。这样同一个时间断面的测点值就会存放在一起。只要列簇存在,列便可以有客户端随时添加。
在为HBase设计模式时,最重要的是考虑数据的访问方式。所有数据都是通过主键进行访问。所以在设计时,最主要的问题是知道如何查询这些数据。在对Hbase这样面向列(簇)的存储设计模式时,要知道它是可以以极小的开销管理较宽的稀疏表。
我们应以较多的精力设计行的键。一个精心设计的复合键可以用来对数据进行聚类,以配合数据的访问。















 8898
8898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









