










前言:
当今是信息爆炸的时代,在处理高频数据时,关系型数据库oracle/mysql明显表现出乏力,因秒级、毫秒级高频数据,分分钟可以把关系型数据库的表塞爆。在日常生活工作中,我们经常会遇到哪些需要高频分析的场景呢?本次我们借鉴时序数据库influxDB来引出高频数据分析的实践方案。
一、场景引导选型
1、高频数据场景
首先来说说我接触到的高频数据场景,因最近项目在做设备运行状态的分析,如车间24小时运行的反应釜、流量计、浓缩机、电表、水表等。我们需要收集对应运行数据,与工艺单关联进行产品生产质量的预判等。因某个因素的异常都会影响产品的最终质量,因此我们需要持续观测所有指标数据,并及时预警,处理异常。
如果我们有1000台设备,需要观测的参数为200个,我们需收集1秒频次的数据,那我们一天数据量=1000*200*24小时*60分钟*60秒=17,2800,000,000(十七亿二千八百万)条数据。因此在高频数据场景下,传统关系型数据是不能满足应用需要的。
在高频数据采集场景下,我们对数据库的要求是支持大量写入IO,存储占用空间少,并能及时完成运行异常预警。
其实还有一个我们每个人都会接触的高频数据预警的场景,就是我们自己电脑运行的监控。
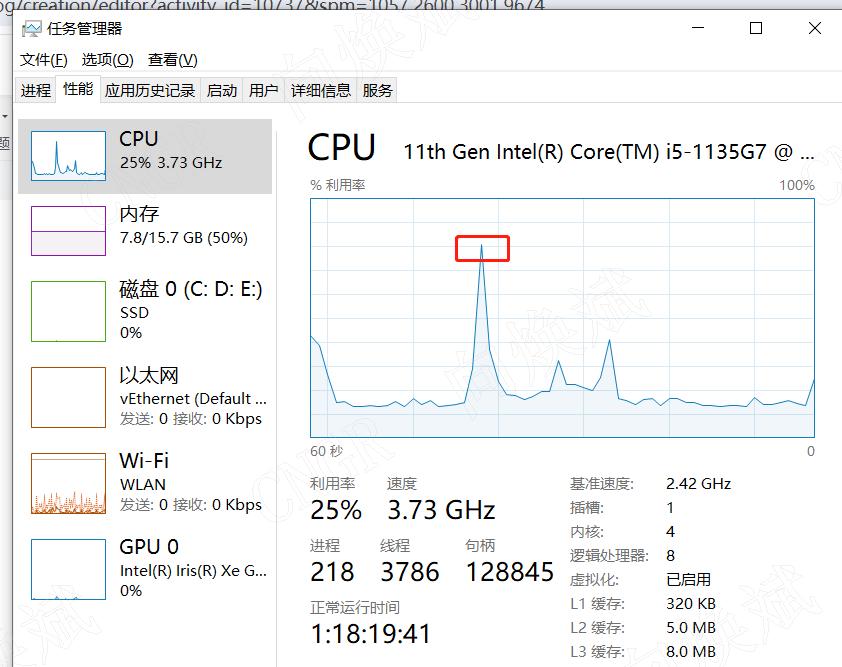
我们怎么去评价一台电脑或者服务器运行正常呢,那就是CPU利用率不能超90%,内存占用不能超90%,磁盘SSD不能超80%等,当我们的CPU突然飙到了90%以上,并持续了几分钟,那就证明我们的电脑或者服务器是存在问题的,如果我们没收集这些性能指标数据,我们可能很难知道哪里出问题了,因此我们收集高频数据还有一个很重要的场景就是做系统的运维监控。
因此高频数据常用场景为:iot数据采集分析+设备运行监控。
2、高频数据适配数据库
通过场景需求调研,时序数据库是最适配高频数据场景的数据库之一,时序数据库专门为时间标记的数据建立,对时间序列数据的存取有着天然的优势。在这类数据库中,数据通常会附带一个时间戳,优化了基于时间的查询和聚合操作。例如,在IoT(物联网)或金融行业中广泛应用的InfluxDB,能够快速处理和存储大量时序数据,并提供实时的分析功能。
二、InfluxDB优缺点
InfluxDB分为OSS社区版和 Enterprise企业版,OSS社区版是免费的,但是没开放集群功能,如果有集群需求可以选择Enterprise版本。但一般的应用场景OSS社区版就够用了,因此InfluxDB的优势还是在于高频的数据采集、预警,复杂的数据分析应用传统的关系型数据会是一个更好的方案。

1、优点
性能优化: 专为写入和查询时间序列数据而优化,处理大量写入操作快速,查询延迟低。
易扩展: 支持水平扩展(sharding),可轻松处理增长的数据量。
查询语言: 使用易于理解的SQL-like语法(InfluxQL)进行查询,方便用户熟悉。
灵活性: 支持多种数据聚合和处理,如窗口函数和连续查询语言(CQL)。
轻量级设计: 适合资源受限的环境,内存占用相对较低。
2、缺点:
复杂性: 对于非时间序列数据或复杂的数据模型,InfluxDB可能不够灵活,需要额外处理转换。
存储限制: 对于非实时数据,长期存储可能会面临挑战,需要定期归档或清理。
可视化工具: 相比于商业数据库,InfluxDB的可视化工具可能不够丰富或者定制化程度不高。
社区支持与商业支持: 如果需要高级支持或定制化服务,大型企业可能更倾向于使用商业化的时间序列数据库产品。
总的来说,时序数据库适合做高频数据采集、预警,如果是复杂数据分析就不是很合适。
三、influxDB应用分析
时序数据库拥有高性能是因为他们摒弃了复杂的数据结构设计,如采用列式存储、不支持删除和高频的更新数据操作。正如时序数据库的经典介绍,时间不可倒流,数据只写不改。
1、结构优化
如下图所示influxDB没有表的概念,数据采用列式存储的方式,通过_measurement(类似表名)+_field/_vaule(字段名及对应值:键值对)+_time(时间戳)组合时序数据库的“表”的必要元素。其中还有一个name为表索引,这个设计是为了提高数据查询效率和对应字段所属的分类。
这也是时序数据库能支持高写入、高查询吞吐量的场景的原因。
2、数据采集方式
influxDB支持CSV文件格式数据采集和符合influxDB语法行
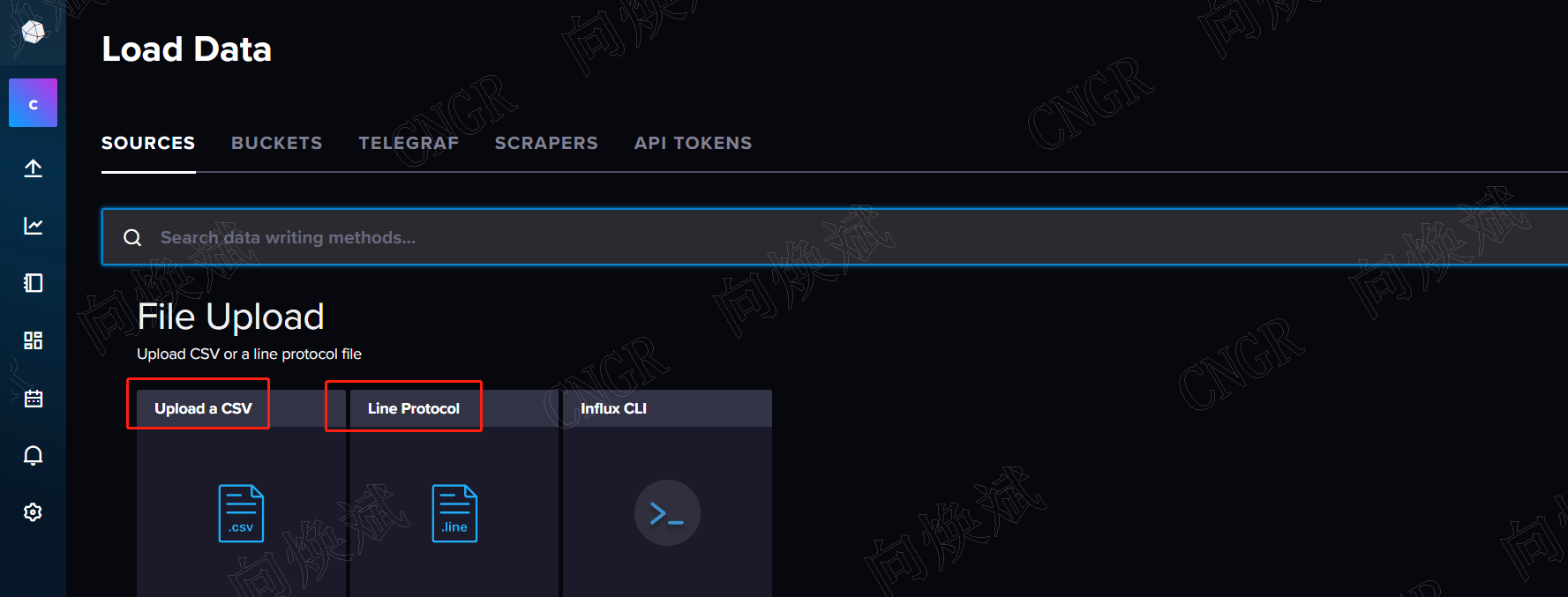
同时支持目前绝大多数编程语言

influxDB也有自己专门的数据采集工具 Telegraf
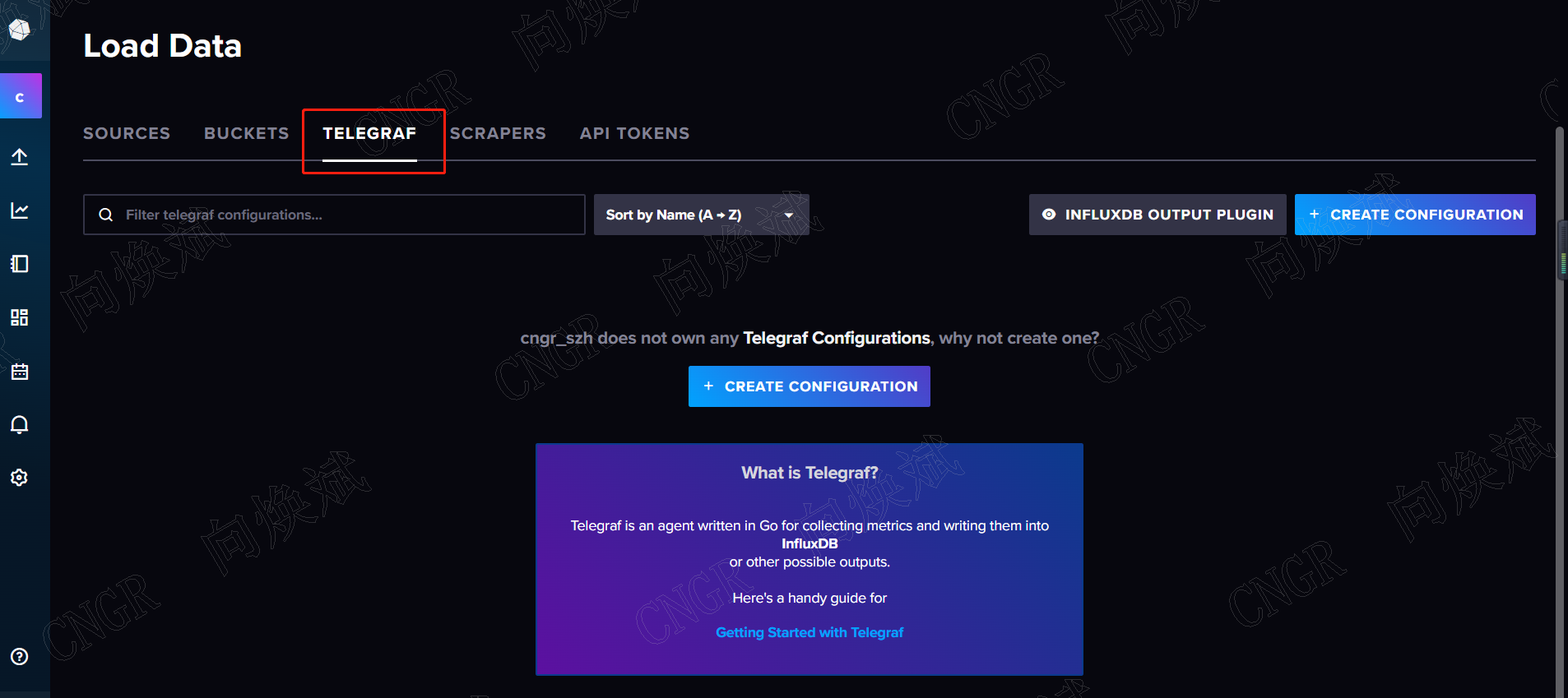
因此,我们可以使用自己熟悉的编程语言来完成数据的采集工作,同样也可以使用时序数据库的数据采集插件,如 Telegraf,因此influxDB数据采集的生态还是很完善的。
3、业务预警
上面提到一些预警的场景,同样的在influxDB里面就自带了一套预警系统,如我们要预警我们的CPU利用率,设置阀值为90%,当超过90%时我们进行预警提醒,这就是一个常用的预警场景。
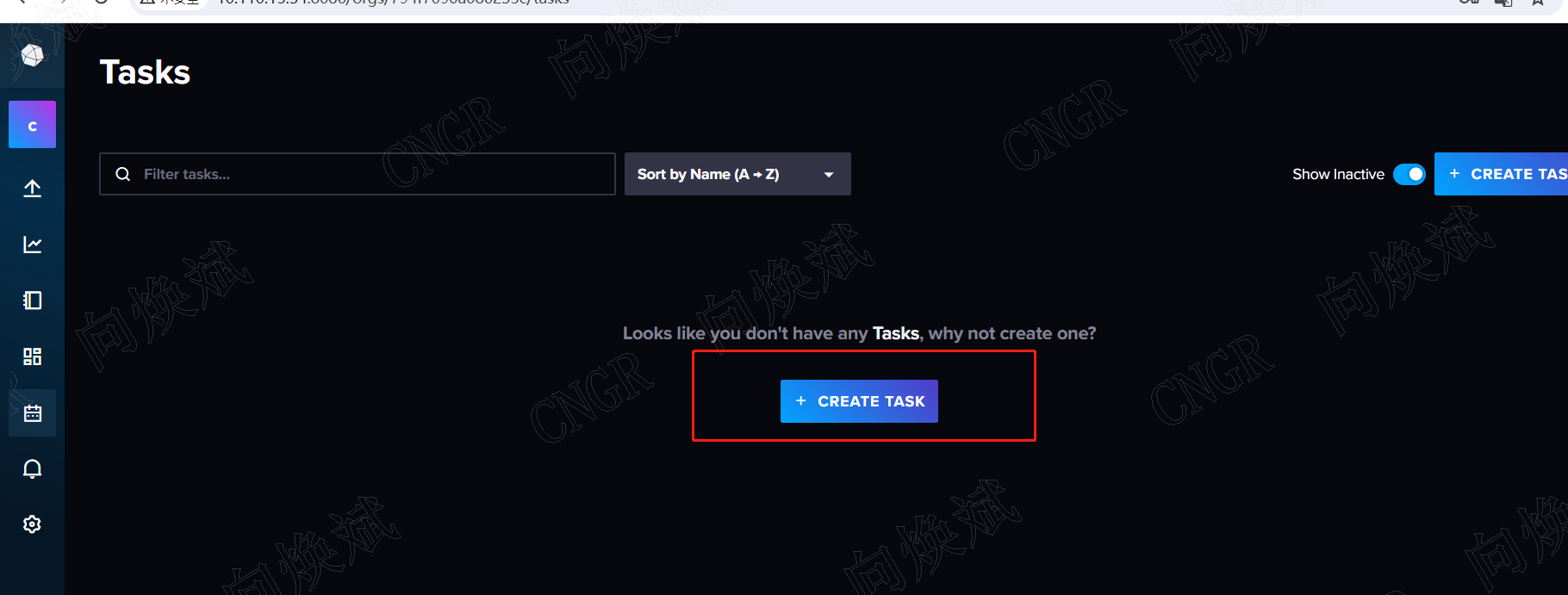
如上图所示,我们通过设置定时预警任务来完成我们需要的预警操作。
四、总结
总的来说,时序数据库能很好的解决高频数据采集、预警的问题,但是不适合做复杂的数据分析,因此我们在做数据库架构和调研时,可以根据自己的需求灵活选择。
GitHub - influxdata/influxdb-client-ruby: InfluxDB 2.0 Ruby ClientInfluxDB 2.0 Ruby Client. Contribute to influxdata/influxdb-client-ruby development by creating an account on GitHub.![]() https://github.com/influxdata/influxdb-client-ruby/GitHub - influxdata/influxdb: Scalable datastore for metrics, events, and real-time analyticsScalable datastore for metrics, events, and real-time analytics - influxdata/influxdb
https://github.com/influxdata/influxdb-client-ruby/GitHub - influxdata/influxdb: Scalable datastore for metrics, events, and real-time analyticsScalable datastore for metrics, events, and real-time analytics - influxdata/influxdb![]() https://github.com/influxdata/influxdb
https://github.com/influxdata/influxdb

















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











