







数据库复杂查询
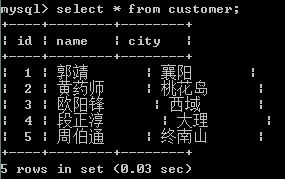
准备好两张表



1.连接查询
实质上也是一种多表查询
select * from table1 join_type table2 [on(jion_condition)] [where(query_condition)];
table1是左表,table2是右表;
join_type表示连接类型:cross join交叉;inner join 内连接;outer join 外连接
on语句为连接条件,where为查询条件,都是可选的;
1.1 交叉连接:做笛卡尔积查询,也就是直积,从表上来说,就是两张表里的每个id都要配对一次
连接查询默认的就是交叉连接方式
/*
* 连接查询
*/
//默认的连接查询
select * from customer,orders;
//交叉连接
select * from customer cross join orders;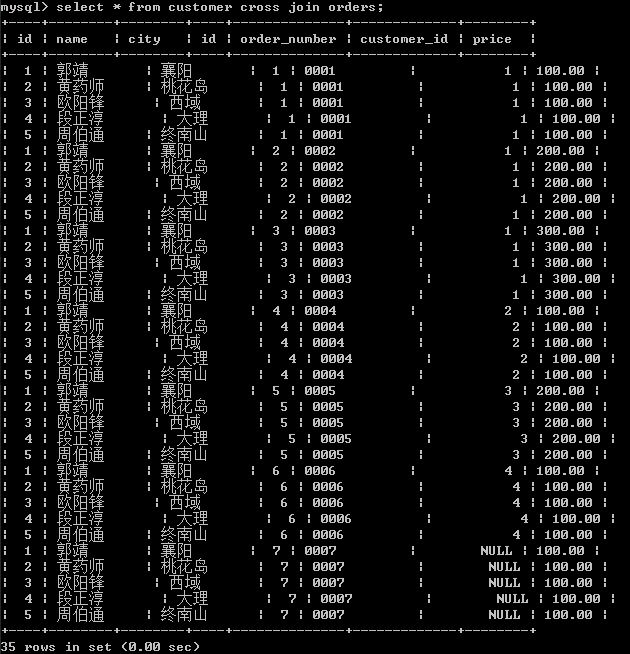
可以看到,产生了大量无用的冗余数据
1.2 内连接:显式和隐式
显式:使用inner join关键字,在on语句里设定关联条件
//显式内连接,以下两个写法效果一样,只是前者更简洁点
select * from customer c inner join orders o on c.id=o.id;
select * from customer inner join orders on customer.id=orders.id;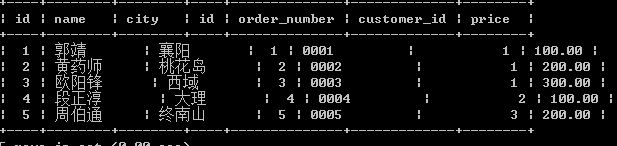
隐式:不包含inner join和on语句,两个表名之间有逗号,在where语句里设置连接条件。
隐式连接对两张表的左右位置不敏感,查询结果实质是相同的(前面的表名,后面的条件语句里位置随便换,不过查询结果看的是表名位置)
//隐式内连接,
select * from customer c,orders o where c.id=o.customer_id;
select * from customer,orders where customer.id=orders.customer_id;
//交换位置也相同
select * from orders o,customer c where c.id=o.customer_id;
select * from customer c,orders o where o.customer_id=c.id;
select * from orders o,customer c where o.customer_id=c.id;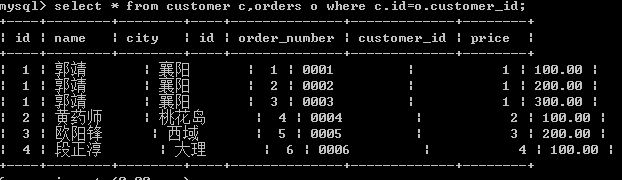

1.3 外连接
分为左外和右外
查询结果除了显示符合条件语句里条件的数据,还显示左表或者右表的其他列数据以左外为例
显然换位置,查询结果是不同的
//左外连接
select * from customer c left outer join orders o on c.id=o.customer_id;
select * from customer c left outer join orders o on c.id=o.customer_id where o.price>250;
//交换位置
select * from orders o left outer join customer c on c.id=o.customer_id;

2.子查询,嵌套查询
例如在订单表里查询郭靖的订单,如果已知郭靖的顾客号为1,那么可以直接查询
//已知顾客号直接查
select * from orders where customer_id=1;//嵌套查
select * from orders where customer_id=(select id from customer where name='郭靖');

更进一步,查找郭靖的订单中价格大于100的,这就是多层嵌套
其实就是要在上面这张表上再查一次,要考虑到给这张表命个名,以便做条件查询
//多层嵌套
select * from (select * from orders where customer_id
=(select id from customer where name='郭靖')) as a where a.price>100;
3.联合查询
将两个查询的结果去掉不同的地方再返回,前提是子查询的表结构应该相同,关键词union
//联合查询
select * from orders where price>100 union
select * from orders where customer_id=1;4.报表查询
4.1 count:统计某一字段有多少行,也可以加上条件,查询符合条件的某个字段的行数
//统计行数
select count(id) from orders;
select count(price) from orders where price=100;
现在要按价格分组,查询价格和他的数量
group(*)表示的是个数,下面这两个查询结果相同
不过前者是查对应id 个数,后者是对被分组的属性本身计算个数,如果某个价格没有对应id,这里结果就不同了
select price,count(id) from orders group by price;
select price,count(*) from orders group by price;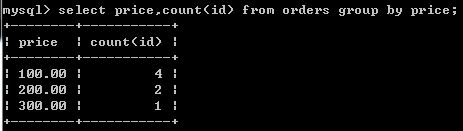
select customer_id,count(id) from orders group by
customer_id having customer_id in(1,2) order by customer_id desc;
4.2求和 sum

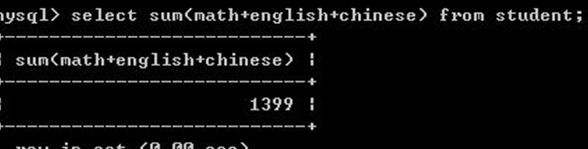
4.3 求平均值 avg
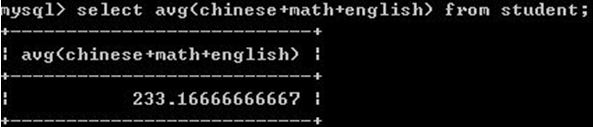
4.4 最值
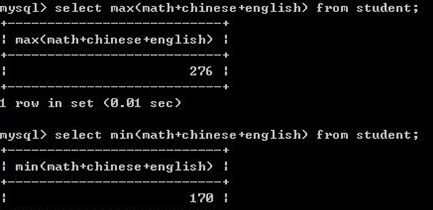
注意,在查询时如果要显示的数据是混合着min max count等方法时,必须带上group

单独查询count等方法就没问题
最后关于备份
可以单独点开一个系统的命令行而不是MySQL的命令行,而且并不是完整的数据库,而只是操作语句
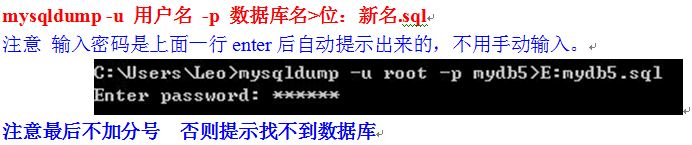
对备份的数据库恢复
















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









