







 本文介绍了Aho-Corasick自动机,一种用于高效多模式匹配的算法。讲解了其原理,包括字典树的构建、失配指针(Next和fail指针)、匹配过程及后缀链接优化。通过拓扑排序和预计算失败指针,提升了在大量模式串搜索时的性能。
本文介绍了Aho-Corasick自动机,一种用于高效多模式匹配的算法。讲解了其原理,包括字典树的构建、失配指针(Next和fail指针)、匹配过程及后缀链接优化。通过拓扑排序和预计算失败指针,提升了在大量模式串搜索时的性能。
Aho-Corasick automaton
1. 介绍
A C AC AC自动机( A h o − C o r a s i c k a u t o m a t o n Aho-Corasick automaton Aho−Corasickautomaton),是一种多模匹配算法,就是在一个文本里面找多个模式串
- 我们知道 K M P KMP KMP算法的时间复杂度是 O ( l o g ( n + m ) ) O(log(n+m)) O(log(n+m)),如果有 k k k个模式串,那么进行查找总的时间复杂度就是 O ( l o g ( k × ( n + m ) ) ) O(log(k\times(n+m))) O(log(k×(n+m))),看起来也还不错,但是问题是如果 k k k很大 ( 1 e 5 ) (1e5) (1e5)呢?如果文本串也是这么大那么显然不能在规定的时间内得到答案,由此引入 A C AC AC自动机进行改进
- 这两种算法思想上有相似之处,但是用来解决不同问题的不同算法,相互之间并没有什么直接联系
2. 原理
2.1 建树
- 我们首先要知道字典树建树的原理,让我们简要复习一下
- 举个实例,以刘汝佳老师白书中这个为例,假设有这样一组模式串
{
h
e
,
s
h
e
,
h
i
s
,
h
e
r
s
}
\{he,she,his,hers\}
{he,she,his,hers}首先建立字典树如下图
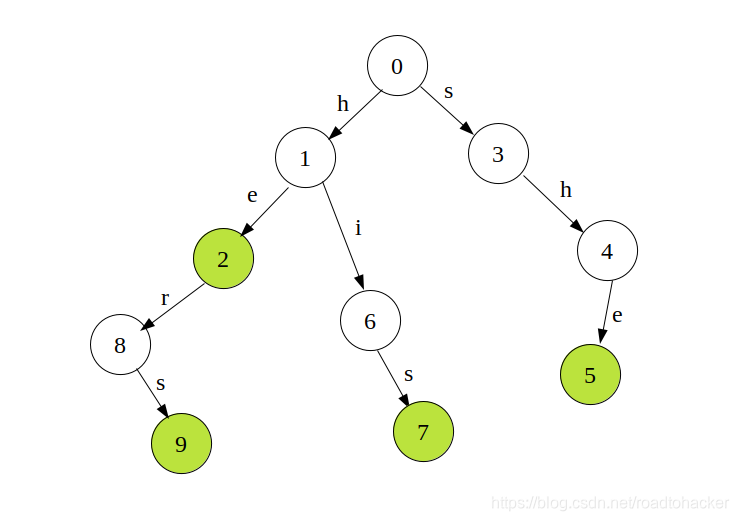
- 图中带颜色的节点表示单词结尾,在普通的 t r i e trie trie树中我们只需要染色即可,但是在这里我们可以记录更多一些的信息比如单词数量,因为这个结点可能表示多个单词的结尾
- 复习一下 t r i e trie trie树的代码,其中 s z sz sz表示节点编号,对于已经存在的节点, s z sz sz值不变,对于不存在且当前需要添加的同一个单词的节点, s z sz sz值是连续递增的,这里面清空 c h [ s z ] ch[sz] ch[sz]的含义就是防止清除掉之前建立的 t r i e trie trie树的这个节点,对于单组数据,不清空也可; u u u的含义就是一个索引,记录当前单词的每一个节点编号,最后记录单词的最后一个字母编号, v a l [ u ] val[u] val[u]表示以编号 u u u为结尾的单词数量
- 如果不理解建议手推一遍
const int SIGMA_SIZE = 26;
int ch[MAXN][SIGMA_SIZE + 10];
int val[MAXN];
struct Trie{
int sz;
Trie(){
memset(ch[0], 0, sizeof ch[0]);
sz = 1;
}
void insert(string &s){
int len = s.length();
int u = 0;
for(int i=0;i<len;i++){
int c = s[i] - 'a';
if(!ch[u][c]){
memset(ch[sz], 0, sizeof ch[sz]);
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] += 1;
}
};
2.2 失配指针
2.2.1 回顾Next
- 先回忆一下 K M P KMP KMP的 N e x t Next Next数组, N e x t [ j ] Next[j] Next[j]记录的是模式串子串 s u b s t r ( j ) substr(j) substr(j)的最长公共前后缀(不含自身),从而使得模式串指针不需要总是回退到起始位置,那退到哪去呢?
- 如果想不好,可以慢慢的想,如果不是很熟悉,这里容易乱. 因为我们的 N e x t Next Next数组下标是从 1 1 1开始的(一般写法),而字符串下标是从 0 0 0开始的,这中间差了 1 1 1,如果模式串的 j j j位置失配了,那么根据 N e x t Next Next数组的定义,它其实读取的是模式串的子串 s u b s t r ( j − 1 ) substr(j-1) substr(j−1)的最长公共前后缀(不含自身),也就是如果 j j j位置上发生了失配,应该让 j = N e x t [ j ] j=Next[j] j=Next[j],保持相差 1 1 1,因为前面公共部分已经比较过了,不需要再次比较,保持这样的差值对于编程而言很方便
- 举个例子,串 { a a a b } \{aaab\} {aaab}, N e x t = { 0 , 1 , 2 , 0 } Next=\{0,1,2,0\} Next={0,1,2,0},如果 b b b这里失配,那么由于 b b b的字符串下标是 3 3 3, N e x t [ 3 ] = 2 Next[3]=2 Next[3]=2( N e x t Next Next下标从 1 1 1开始),那么 j j j指针应该回到 2 2 2位置上,这个位置是字符串的第三个位置,因为前面的 a a aa aa是最长公共前后缀,已经比较过了
- 说的有点啰嗦了,这个位置说起来真的不太容易(即使晕掉了也没事,不影响接下来的学习)
2.2.2 fail指针
- 接下来是 t r i e trie trie树上的失配指针,一般叫做 f a i l fail fail指针,这里先提出概念,如果说 i i i节点的 f a i l fail fail指针指向 j j j,那么以 j j j为终止节点的单词是以 i i i为终止节点的单词的最长后缀
- 我们走一遍流程尝试构建
f
a
i
l
fail
fail指针,首先对
t
r
i
e
trie
trie树进行层次遍历,以最上面的图为例子,首先根节点的子结点的
f
a
i
l
fail
fail指针都指向根节点,并把这些节点都入队,如下图所示
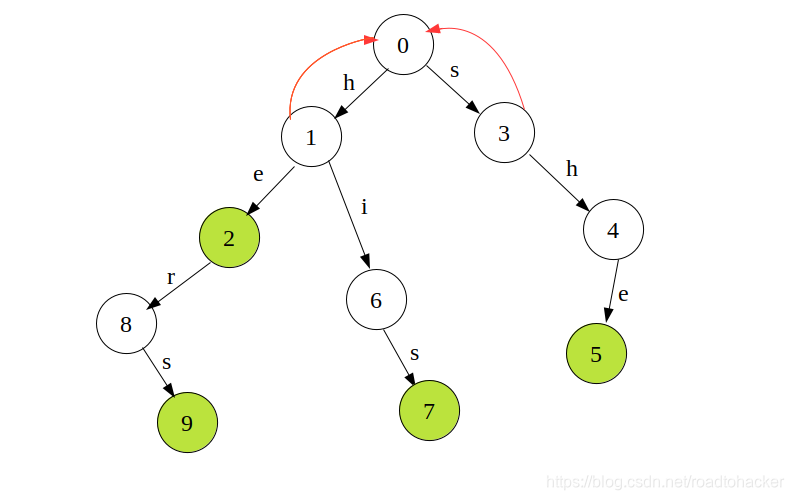
队列元素: { 1 , 3 } \{1,3\} {1,3} - 接着,处理队列中的元素的子节点,现在处理 2 2 2号节点,它的 f a i l fail fail指针应该指向谁呢?回顾一下 f a i l fail fail指针的定义, f a i l [ i ] → j fail[i]\rightarrow j fail[i]→j,那么 j j j是 i i i的最长后缀,既然最长,显然要看父亲节点指向的是谁,因为如果能够接在父亲结点的 f a i l fail fail指针之后,那一定是最长的,一看,指向根节点,那根节点有没有字母 e e e的边呢?没有,所以指向根节点即可
- 等到处理
4
4
4号节点的时候,情况变了,这时候根节点有字母为
h
h
h的边,所以这时候我们就把
f
a
i
l
[
4
]
=
1
fail[4]=1
fail[4]=1,构建这一层的
f
a
i
l
fail
fail指针如下图

队列元素: { 2 , 6 , 4 } \{2,6,4\} {2,6,4} - 接下来看下一层,
8
8
8号父亲指向根节点,根节点没有
r
r
r,所以
8
8
8号指向根节点;同理
7
7
7号指向3,
5
5
5号指向
2
2
2,因为父亲
f
a
i
l
fail
fail指针指向的是
1
1
1,需要看
1
1
1有没有
e
e
e边,一看是有的,如下图
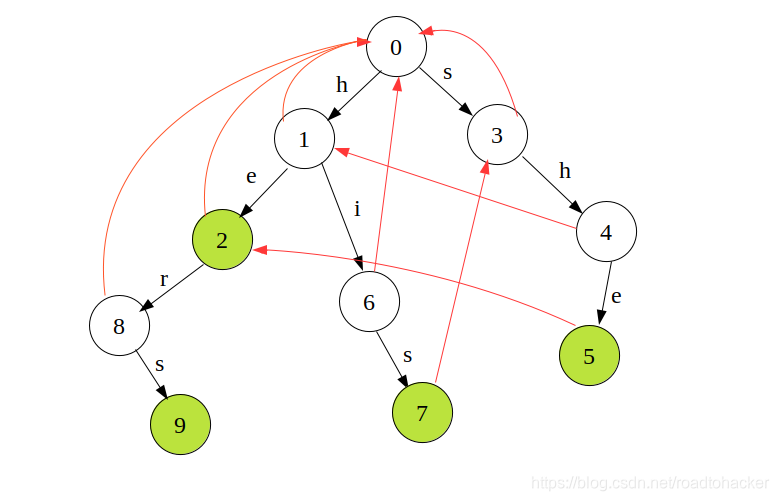
队列元素: { 8 , 7 , 5 } \{8,7,5\} {8,7,5} - 接下来就剩下一个
9
9
9号了,它应该指向
3
3
3号节点
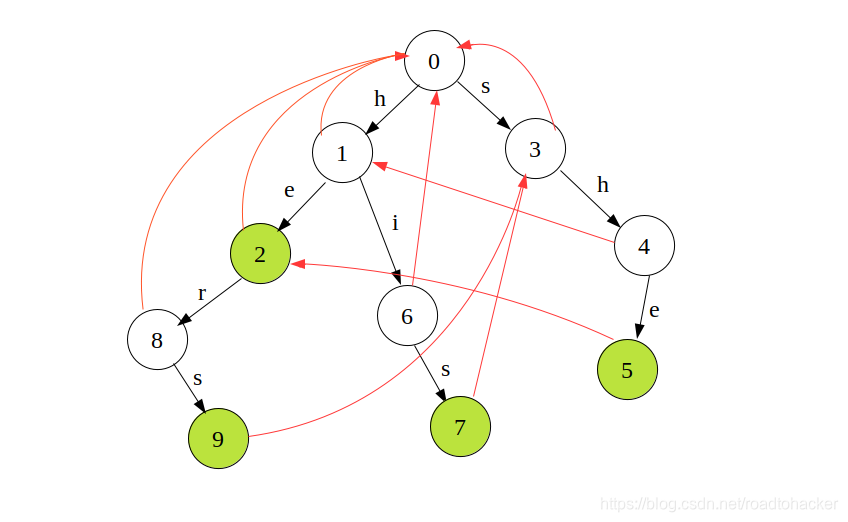
- 这样 F a i l Fail Fail指针就构建完成了,接下来面临一个严峻的问题,代码怎么写??
2.2.3 Get_Fail函数
- 其实如果上面的过程理解了以后,代码不难理解,首先我们需要一个队列存储层次遍历的当前层元素(接下来我把根结点的子结点所在的层数叫做第一层,往下以此类推),需要一个数组 f a i l fail fail
- 显然第一层元素的 f a i l fail fail指向根节点即可,接下来进行层次遍历,第二层的元素的 f a i l fail fail指针应该指向谁呢?应该找它父亲的 f a i l fail fail指针指向的那个元素的孩子里面有没有这个元素,如果有就连过去,如果没有,应该反复跳 f a i l fail fail,因为这个节点也是有 f a i l fail fail指针的,直到 f a i l fail fail指针指向根节点,这时候看根节点有没有孩子是这个元素的,如果有就连过去,没有就直接连根节点,所以程序如下
void Get_Fail(){
queue<int> q;
f[0] = 0;
for(int c=0;c<SIGMA_SIZE;c++){
int u = ch[0][c];
if(u){
q.push(u);
f[u] = 0;
}
}
while(!q.empty()){
int r = q.front();
q.pop();
for(int c=0;c<SIGMA_SIZE;c++){
int u = ch[r][c];
if(!u){
continue;
}
q.push(u);
int v = f[r];
while(v && !ch[v][c]) v = f[v];//跳fail
f[u] = ch[v][c];//根节点是0,要是没有也就直接连过去了
}
}
}
- 应该不难理解,前面说的非常详细了
2.3 匹配过程
- 准备工作都完成了,现在开始字符串匹配,以我刚才构建好的
A
C
AC
AC自动机为例,现在文本串是
h
i
s
h
e
r
s
h
hishersh
hishersh,看看怎么匹配呢?
- 从根节点出发,首先遇到的是 h h h,一看有这条边,就过去,到 1 1 1号节点。接下来是 i i i, 1 1 1号节点有这条边,走到 6 6 6号节点,接下来到 7 7 7号节点之后,发现没有子结点了,那我的 h h h怎么办呢?
- 这时候 f a i l fail fail指针开始工作,直接跳到 3 3 3号节点,一看有 h h h了(这时候如果没有就继续跳 f a i l fail fail直到到根),接下来就继续走走走,如果不匹配了,就沿着 f a i l fail fail指针走;如果匹配,还得往回跳 f a i l fail fail,为什么?
2.3.1 后缀链接
-
注意!这是可能会陷入的一个误区,看下面的例子
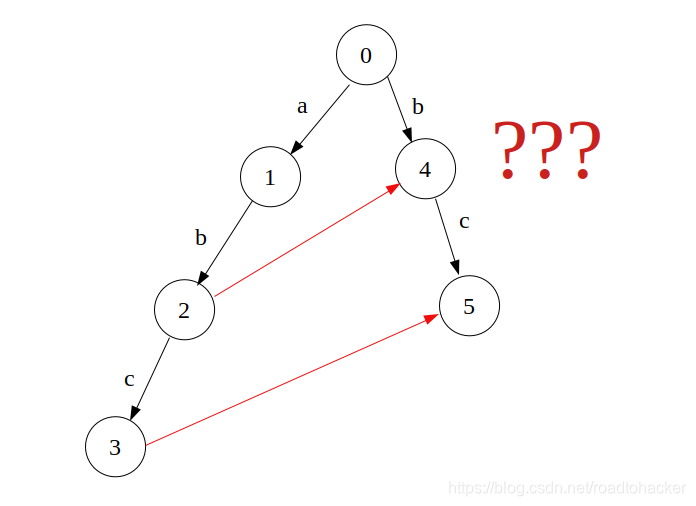
-
如果文本串是 a b c abc abc,现在看这个图里有两个模式串分别是 { a b c , b c } \{abc,bc\} {abc,bc},那么如果我们简单的根据 f a i l fail fail指针来跳转就会漏掉右侧这个 b c bc bc串,那么怎么解决这个问题呢?我们必须沿着 f a i l fail fail往回走,统计所有的这些单词,那么可以引入一个 l a s t last last指针,记录它沿着 f a i l fail fail指针往回走的时候遇到的下一个单词节点编号,这里不仅解决了这一问题,还提高了查找下一个单词的效率(像是路径压缩?)
-
详细一点说,就是比如现在匹配到了文本串的第 i i i个字母,不仅要看他是不是单词的结尾,还要看它的 f a i l fail fail指向的整条链有多少个单词,这样查询程序如下
void print(int j){
if(j){
ans[mp[j]] += 1;
print(last[j]);//统计fail链
}
}
void Find(string &T){
int len = T.length();
int j = 0;
for(int i=0;i<len;i++){
int c = T[i] - 'a';
while(j && !ch[j][c]) j = f[j];
j = ch[j][c];
if(val[j]) print(j);//当前即为单词结尾
else if(last[j]) print(last[j]);//统计fail这条链
}
}
- G e t _ f a i l Get\_fail Get_fail中,求 f a i l fail fail的核心代码如下, u u u表示当前节点编号
last[u] = val[f[u]] ? f[u] : last[f[u]];
2.3.2 改进
- 考虑到在查找的过程中需要不断的跳 f a i l fail fail,如果在 G e t _ F a i l Get\_Fail Get_Fail的过程中直接标记好每个节点能够匹配的 f a i l fail fail位置,就会很方便,只需要把每个不存在的节点和它的 f a i l fail fail指针指向的该字符的节点连接即可,这样就不需要跳 f a i l fail fail了
- 改进之后得到程序如下
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
#include <vector>
#include <cmath>
#include <queue>
#include <stack>
#include <map>
#include <iomanip>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const int INF = 0x3f3f3f3f;
const int MAXN = 1e6 + 100;
const int SIGMA_SIZE = 26;
int ch[MAXN][SIGMA_SIZE + 10];
int vis[MAXN];
int ans;
int val[MAXN];
struct Trie{
int sz;
Trie(){
memset(ch[0], 0, sizeof ch[0]);
sz = 1;
}
void Insert(string &s){
int len = s.length();
int u = 0;
for(int i=0;i<len;i++){
int c = s[i] - 'a';
if(!ch[u][c]){
memset(ch[sz], 0, sizeof ch[sz]);
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] += 1;
}
};
int last[MAXN], f[MAXN];
void Get_Fail(){
queue<int> q;
f[0] = 0;
for(int i=0;i<SIGMA_SIZE;i++){
int u = ch[0][i];
if(u){
q.push(u);
f[u] = 0;
last[u] = 0;
}
}
while(!q.empty()){
int r = q.front();
q.pop();
for(int c=0;c<SIGMA_SIZE;c++){
int u = ch[r][c];
if(!u){
ch[r][c] = ch[f[r]][c];//把所有不存在的边连上
continue;
}
q.push(u);
int v = f[r];
while(v && !ch[v][c]) v = f[v];
f[u] = ch[v][c];
last[u] = val[f[u]] ? f[u] : last[f[u]];
}
}
}
void print(int j){
if(j && !vis[j]){
ans += val[j];
vis[j] = 1;
print(last[j]);
}
}
void Find(string &T){
int len = T.length();
int j = 0;
for(int i=0;i<len;i++){
int c = T[i] - 'a';
//while(j && !ch[j][c]) j = f[j];
j = ch[j][c];
if(val[j]) print(j);
else if(last[j]) print(last[j]);
}
}
int main(){
#ifdef LOCAL
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
#endif
ios::sync_with_stdio(false);
int n;
cin >> n;
Trie trie;
string s;
while(n--){
cin >> s;
trie.Insert(s);
}
Get_Fail();
cin >> s;
Find(s);
cout << ans << '\n';
return 0;
}
2.4 时间复杂度分析
设模式串有 k k k个,平均长度为 n n n,文本串长度为 m m m
- 建 t r i e trie trie树和求 f a i l fail fail均为 O ( k n ) O(kn) O(kn),模式匹配是 O ( n m ) O(nm) O(nm),(因为需要不断往上跳 f a i l fail fail),总时间复杂度是 O ( k n + n m ) O(kn+nm) O(kn+nm)
- 如果使用 K M P KMP KMP,时间复杂度显然为 O ( k n + k m ) O(kn+km) O(kn+km),所以如果模式串个数远小于文本串长度的时候,使用 A C AC AC自动机优势很大
- 但是有一个问题,匹配的过程暴力跳 f a i l fail fail最坏事件复杂度将达到 O ( n m ) O(nm) O(nm),如果文本串和模式串都很长,每次跳 f a i l fail fail如果只能往上走一层,那么时间复杂度就会爆炸,所以问题仍然需要解决
2.5 拓扑优化
- 因为 f a i l fail fail指针肯定是向上指的,所以若干个 f a i l fail fail指针必然形成一个 D A G DAG DAG图,我们在计算 f a i l fail fail的时候统计一下它们的入度;之后使用文本串进行匹配,如果发现了一个单词就对它标记一下(+1),在 f a i l fail fail树上,从下往上更新节点,还是利用 f a i l fail fail这条链上都是可能出现的单词这条性质,所有点都需要统计到,这里使用拓扑排序的方法,也就是从入度为 0 0 0的点开始往上更新
- 这里就不画图了,比较容易理解
3. 三道模板题
https://www.luogu.com.cn/problem/P3808
- 数据非常弱,主要是数据量大,卡不正确的复杂度,上面程序交上去即可通过
https://www.luogu.com.cn/problem/P3796
- 因为保证单词之间不重复,确保每个节点之可能表示一个单词结尾,记录不同单词结尾,统计出现数量即可,单词数量也不多
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
#include <vector>
#include <cmath>
#include <queue>
#include <stack>
#include <map>
#include <iomanip>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const int INF = 0x3f3f3f3f;
const int MAXN = 1e6 + 100;
const int SIGMA_SIZE = 26;
string Data[MAXN];
int ch[MAXN][SIGMA_SIZE + 10];
int val[MAXN];
int ans[MAXN];
map<int, int> mp;
struct Trie{
int sz;
Trie(){
memset(ch[0], 0, sizeof ch[0]);
sz = 1;
}
void Insert(string &s, int j){
int len = s.length();
int u = 0;
for(int i=0;i<len;i++){
int c = s[i] - 'a';
if(!ch[u][c]){
memset(ch[sz], 0, sizeof ch[sz]);
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] += 1;
mp[u] = j;
}
};
int last[MAXN], f[MAXN];
void Get_Fail(){
queue<int> q;
f[0] = 0;
for(int i=0;i<SIGMA_SIZE;i++){
int u = ch[0][i];
if(u){
q.push(u);
f[u] = 0;
last[u] = 0;
}
}
while(!q.empty()){
int r = q.front();
q.pop();
for(int c=0;c<SIGMA_SIZE;c++){
int u = ch[r][c];
if(!u){
ch[r][c] = ch[f[r]][c];
continue;
}
q.push(u);
int v = f[r];
while(v && !ch[v][c]) v = f[v];
f[u] = ch[v][c];
last[u] = val[f[u]] ? f[u] : last[f[u]];
}
}
}
void print(int j){
if(j){
ans[mp[j]] += 1;
print(last[j]);
}
}
void Find(string &T){
int len = T.length();
int j = 0;
for(int i=0;i<len;i++){
int c = T[i] - 'a';
j = ch[j][c];
if(val[j]) print(j);
else if(last[j]) print(last[j]);
}
}
int main(){
#ifdef LOCAL
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
#endif
ios::sync_with_stdio(false);
int n, q;
while(cin >> n && n){
Trie trie;
string s;
for(int i=0;i<n;i++){
cin >> Data[i];
trie.Insert(Data[i], i);
}
Get_Fail();
cin >> s;
Find(s);
int MAX = -1;
for(int i=0;i<n;i++){
MAX = max(MAX, ans[i]);
}
cout << MAX << '\n';
for(int i=0;i<n;i++){
if(MAX == ans[i]){
cout << Data[i] << '\n';
}
ans[i] = 0;
}
}
return 0;
}
https://www.luogu.com.cn/problem/P5357
- 这道题如果采用上面的方式,会 T L E TLE TLE一部分测试点
- 这里也可使用 u n o r d e r e d _ m a p unordered\_map unordered_map,速度能快一些
- 使用拓扑优化,时间复杂度合格,这里程序就是对上面的程序加了一个拓扑,写得比较随意,有点乱了
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
#include <vector>
#include <cmath>
#include <queue>
#include <stack>
#include <unordered_map>
#include <iomanip>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const int INF = 0x3f3f3f3f;
const int MAXN = 1e6 + 100;
const int SIGMA_SIZE = 26;
string Data[MAXN];
int ch[MAXN][SIGMA_SIZE + 10];
int val[MAXN];
int ans[MAXN];
int in[MAXN];
int vis[MAXN];
int last[MAXN], f[MAXN];
unordered_map<int, int> mp;
unordered_map<string, int> times;
struct Trie{
int sz;
int num;
Trie(){
memset(ch[0], 0, sizeof ch[0]);
sz = 1;
num = 0;
}
void Insert(string &s, int j){
int len = s.length();
int u = 0;
for(int i=0;i<len;i++){
int c = s[i] - 'a';
if(!ch[u][c]){
memset(ch[sz], 0, sizeof ch[sz]);
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] += 1;
mp[u] = j;
}
void topu(){
queue<int> q;
for(int i=1;i<sz;i++){
if(in[i] == 0) q.push(i);
}
while(!q.empty()){
int u = q.front();
if(mp.count(u)){
ans[mp[u]] += vis[u];
}
q.pop();
int v = f[u];
in[v] -= 1;
vis[v] += vis[u];
if(in[v] == 0) q.push(v);
}
}
};
void Get_Fail(){
queue<int> q;
f[0] = 0;
for(int i=0;i<SIGMA_SIZE;i++){
int u = ch[0][i];
if(u){
q.push(u);
f[u] = 0;
last[u] = 0;
}
}
while(!q.empty()){
int r = q.front();
q.pop();
for(int c=0;c<SIGMA_SIZE;c++){
int u = ch[r][c];
if(!u){
ch[r][c] = ch[f[r]][c];
continue;
}
q.push(u);
int v = f[r];
while(v && !ch[v][c]) v = f[v];
f[u] = ch[v][c];
in[f[u]] += 1;
last[u] = val[f[u]] ? f[u] : last[f[u]];
}
}
}
void Find(string &T){
int len = T.length();
int j = 0;
for(int i=0;i<len;i++){
int c = T[i] - 'a';
j = ch[j][c];
vis[j] += 1;
}
}
unordered_map<string, int> pp;
int main(){
#ifdef LOCAL
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
#endif
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, q;
cin >> n;
Trie trie;
string s;
for(int i=0;i<n;i++){
cin >> Data[i];
if(!times.count(Data[i])){
trie.Insert(Data[i], i);
pp[Data[i]] = i;
}
times[Data[i]] += 1;
}
Get_Fail();
cin >> s;
Find(s);
trie.topu();
for(int i=0;i<n;i++){
cout << ans[pp[Data[i]]] << '\n';
}
return 0;
}
有问题请留言交流




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











