







文章结尾有CSDN官方提供的学长的联系方式!!
欢迎关注B站
本系统从零开始构建一个基于GraphRAG的红楼梦项目
视频
从零开始红楼梦GraphRAG问答系统
01 本项目的目标
本系统目标是从零开始构建一个基于GraphRAG的红楼梦项目,基于红楼梦的文本通过GraphRAG抽取知识图谱,搭建问答系统。
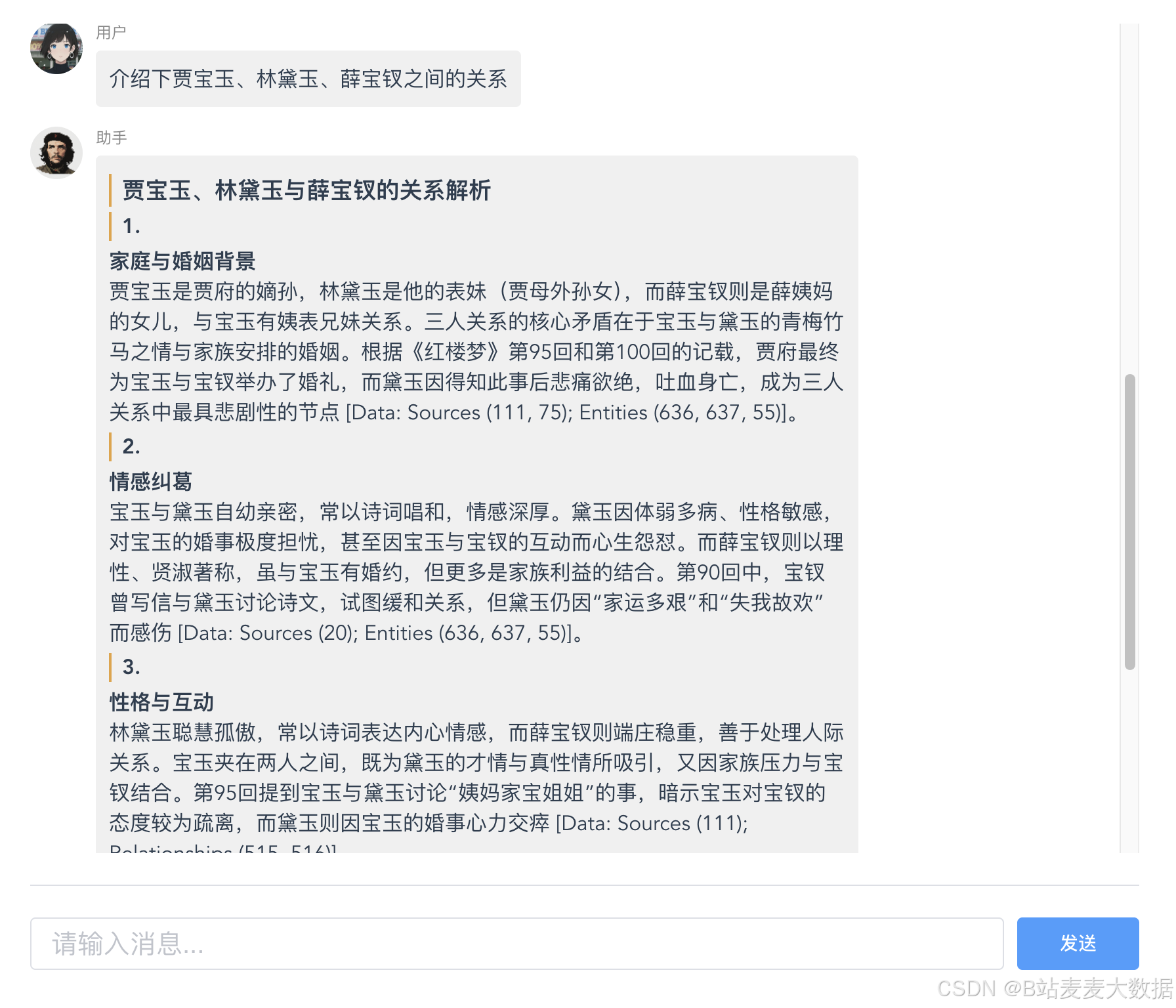
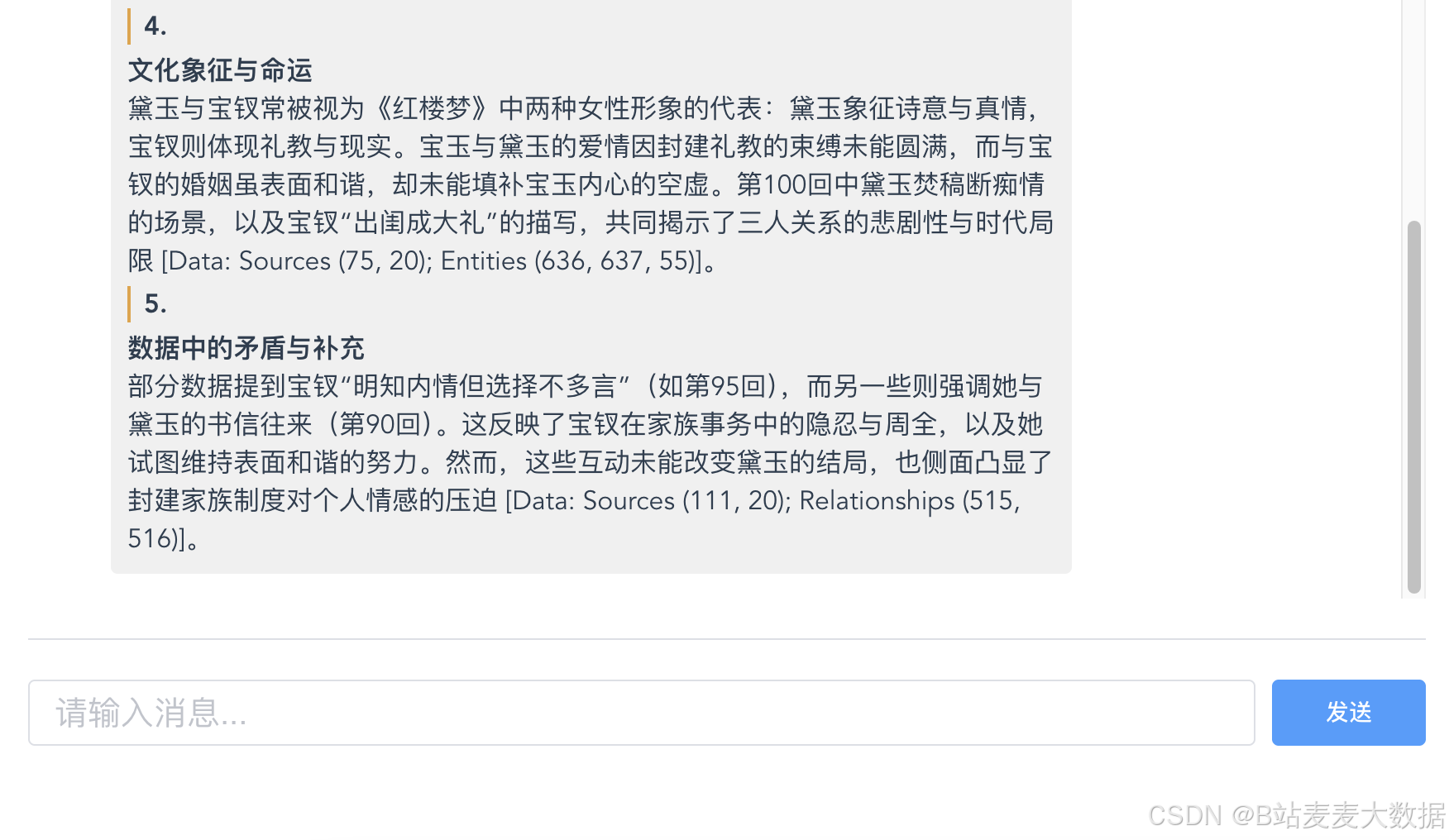
初步搭建效果展示
利用vue开发的一个前端
后端为基于GraphRAG的问答服务端
项目环境
- 使用macbook开发
- 开发工具为Pycharm
- Python 3.12
- 使用到的chat模型为:Qwen/Qwen3-32B
- 嵌入模型为:BAAI/bge-m3
02 RAG VS GraphRAG
GraphRAG是微软研究院发布的一套数据处理流水线及转换工具集,通过大语言模型(LLM)能力从非结构化文本中提取富含语义的结构化数据。
若需深入了解GraphRAG如何提升大语言模型对特定领域私有数据的推理能力,如果需要更多的信息,可以参阅微软研究院的技术博客
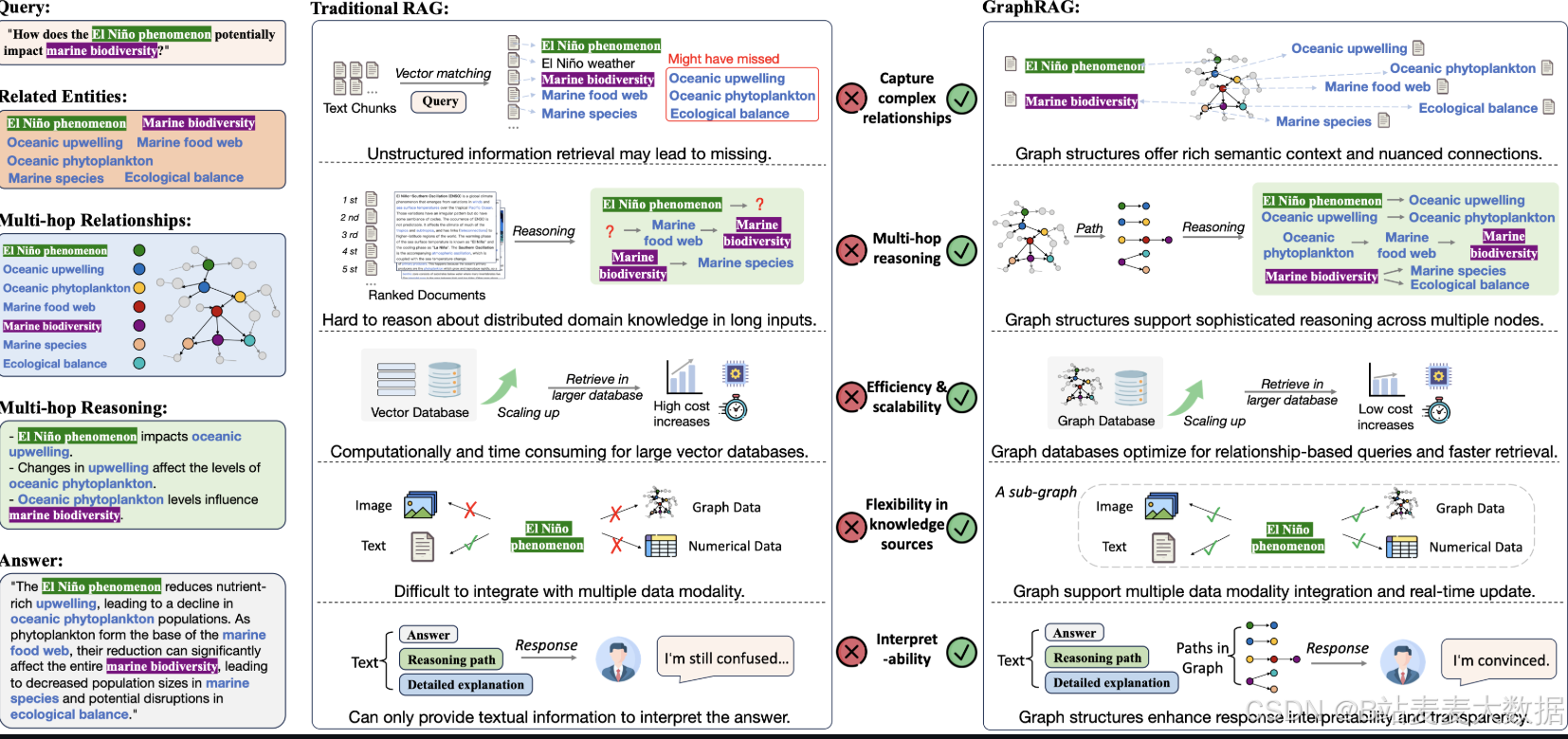
GraphRAG 作为 RAG 的全新范式,通过三大关键创新突破传统 RAG 的局限,深度优化面向特定领域的大语言模型(LLM)应用:
(i) 图结构化知识表征:显式捕获实体关系与领域层级结构;
(ii) 图感知检索机制:支持多跳推理与上下文保全的知识获取;
(iii) 结构引导知识搜索算法:保障超大规模知识库中的高效检索。
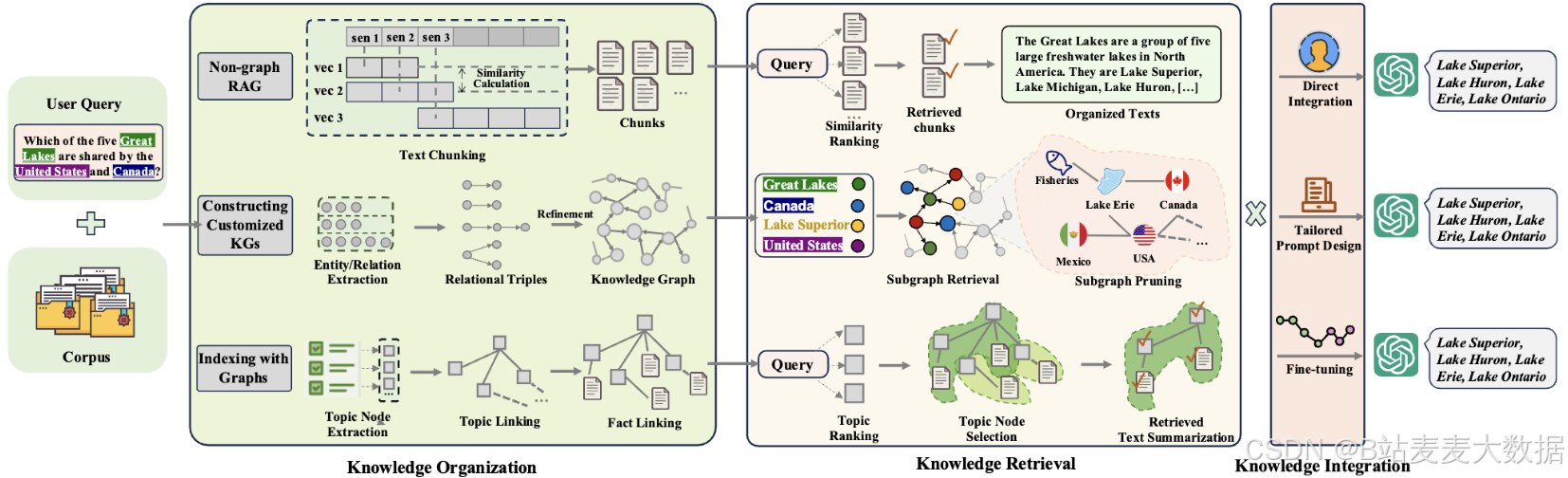
03 RAG VS 两种GraphRAG
传统RAG与两种典型GraphRAG工作流程概述
- 非图RAG:将文本数据分割为片段,按相似度排序,并检索最相关的文本来生成响应。
- 基于知识的GraphRAG:利用实体识别和关系抽取技术,从文本中提取细粒度知识图谱,提供面向领域的精细信息。
- 基于索引的GraphRAG:将文本概括为高层级主题节点,通过节点链接形成索引图谱,同时通过事实关联将主题映射回原文。
04 创建环境
4.1 创建项目
使用PyCharm创建一个项目叫GraphRAG001,并且选择创建一个虚拟环境,是python3.12的
然后创建一个requirements.txt
内容如下
fastapi==0.112.0
uvicorn==0.30.6
pandas==2.2.2
tiktoken==0.7.0
graphrag==0.3.0
pydantic==2.8.2
python-dotenv==1.0.1
asyncio==3.4.3
aiohttp==3.10.3
numpy==1.26.4
scikit-learn==1.5.1
matplotlib==3.9.2
seaborn==0.13.2
nltk==3.8.1
spacy==3.7.5
transformers==4.44.0
torch==2.2.2
torchvision==0.17.2
torchaudio==2.2.2
future
安装python依赖
pip install -r requirements.txt
注意,版本要和我一致,否则后续容易出问题。
4.2 创建目录
同时在根目录创建三个文件夹
- cache
- input
- inputs
4.3 拷贝数据集
数据集拷贝到input文件夹中
05 运行GraphRAG
5.1 初始化
python3 -m graphrag.index --init --root ./
这个步骤的可能要花一点时间

这个步骤执行完,会给我们的目录中添加
- output 文件夹
- prompts 文件夹
- .env 环境文件
- settings.yaml 配置文件
5.2 修改配置文件
修改.env
GRAPHRAG_API_BASE=你的地址/v1
GRAPHRAG_CHAT_API_KEY=你的api-key
GRAPHRAG_CHAT_MODEL=deepseek_r1_llama_70b
GRAPHRAG_EMBEDDING_API_KEY=你的地址
GRAPHRAG_EMBEDDING_MODEL=bge-m3
GRAPHRAG_ENTITY_EXTRACTION_PROMPT_FILE=prompts/entity_extraction.txt
GRAPHRAG_SUMMARIZE_DESCRIPTIONS_PROMPT_FILE=prompts/summarize_descriptions.txt
GRAPHRAG_CLAIM_EXTRACTION_PROMPT_FILE=prompts/claim_extraction.txt
GRAPHRAG_COMMUNITY_REPORT_PROMPT_FILE=prompts/community_report.txt
GRAPHRAG_INPUT_DIR=input
GRAPHRAG_CACHE_DIR=cache
修改settings.yaml
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_CHAT_API_KEY}
type: openai_chat # or azure_openai_chat
model: ${GRAPHRAG_CHAT_MODEL}
model_supports_json: true # recommended if this is available for your model.
max_tokens: 2000
# request_timeout: 180.0
# api_base: https://<instance>.openai.azure.com
api_base: ${GRAPHRAG_API_BASE}
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# temperature: 0 # temperature for sampling
# top_p: 1 # top-p sampling
# n: 1 # Number of completions to generate
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_EMBEDDING_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: ${GRAPHRAG_EMBEDDING_MODEL}
# api_base: https://<instance>.openai.azure.com
api_base: ${GRAPHRAG_API_BASE}
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 1200
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
# base_dir: "input"
base_dir: ${GRAPHRAG_INPUT_DIR}
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
# base_dir: "cache"
base_dir: ${GRAPHRAG_CACHE_DIR}
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# base_dir: "inputs/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "inputs/${timestamp}/reports"
# base_dir: ${GRAPHRAG_REPORTING_DIR}
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# prompt: "prompts/entity_extraction.txt"
prompt: ${GRAPHRAG_ENTITY_EXTRACTION_PROMPT_FILE}
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# prompt: "prompts/summarize_descriptions.txt"
prompt: ${GRAPHRAG_SUMMARIZE_DESCRIPTIONS_PROMPT_FILE}
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# 开启协变量
enabled: true
# prompt: "prompts/claim_extraction.txt"
prompt: ${GRAPHRAG_CLAIM_EXTRACTION_PROMPT_FILE}
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# prompt: "prompts/community_report.txt"
prompt: ${GRAPHRAG_COMMUNITY_REPORT_PROMPT_FILE}
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
global_search:
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
5.3 优化提示词
python3 -m graphrag.prompt_tune --config ./settings.yaml --root ./ --no-entity-types --language Chinese --output ./prompts

这个步骤执行完之后,工具会根据数据情况对提示词进行优化。
我们可以查看prompts目录下的文件:
5.4 构建索引
python3 -m graphrag.index --root ./
这个步骤的过程比较长,执行过程:

执行完成之后是这样的:
生成的结果位置:
06 测试
python3 -m graphrag.query --root ./ --method global "宝玉和宝钗、黛玉之间的关系?"
python3 -m graphrag.query --root ./ --method local "宝玉和宝钗、黛玉之间的关系?"





















 4195
4195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











