






Datawhale 知识图谱组队学习 task3 neo4j图数据库导入数据
一、引言
在计算机科学中,图形作为一种特定的数据结构,用于表达数据之间的复杂关系,如社交关系、组织架构、交通信息、网络拓扑等等。在图计算中,基本的数据结构表达式是:G=(V,E),V=vertex(节点),E=edge(边)。图形结构的数据结构一般以节点和边来表现,也可以在节点上增加键值对属性。图数据库是 NoSQL(非关系型数据库)的一种,它应用图形数据结构的特点(节点、属性和边)存储数据实体和相互之间的关系信息。
Neo4j 是当前较为主流和先进的原生图数据库之一,提供原生的图数据存储、检索和处理。它由 Neo Technology支持,从 2003 年开始开发,1.0 版本发布于 2010 年,2.0版本发布于 2013 年。经过十多年的发展,Neo4j 获得越来越高的关注度,它已经从一个 Java 领域内的图数据库逐渐发展成为适应多语言多框架的图数据库。Neo4j 支持ACID、集群、备份和故障转移,具有较高的可用性和稳定性;它具备非常好的直观性,通过图形化的界面表示节点和关系;同时它具备较高的可扩展性,能够承载上亿的节点、关系和属性,通过 REST 接口或者面向对象的 JAVA API进行访问。
二、Neo4j简介
2.1 基本概念
Neo4j使用图相关的概念来描述数据模型,把数据保存为图中的节点以及节点之间的关系。数据主要由三部分构成:
- 节点。节点表示对象实例,每个节点有唯一的ID区别其它节点,节点带有属性;
- 关系。就是图里面的边,连接两个节点,另外这里的关系是有向的并带有属性;
- 属性。key-value对,存在于节点和关系中,如图1所示。
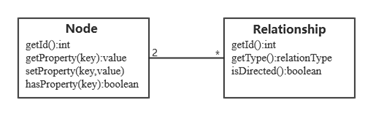
图 1 节点、关系和属性三者的关系
2.2 索引
- 动机:Neo4j使用遍历操作进行查询。为了加速查询,Neo4j会建立索引,并根据索引找到遍历用的起始节点;
- 介绍:默认情况下,相关的索引是由Apache Lucene提供的。但也能使用其他索引实现来提供。
- 操作:用户可以创建任意数量的命名索引。每个索引控制节点或者关系,而每个索引都通过key/value/object三个参数来工作。其中object要么是一个节点,要么是一个关系,取决于索引类型。另外,Neo4j中有关于节点(关系)的索引,系统通过索引实现从属性到节点(关系)的映射。
- 作用:
- 查找操作:系统通过设定访问条件比如,遍历的方向,使用深度优先或广度优先算法等条件对图进行遍历,从一个节点沿着关系到其他节点;
- 删除操作:Neo4j可以快速的插入删除节点和关系,并更新节点和关系中的属性。
2.3 Neo4j的优势
那么,如此引人入胜的 Neo4j,与其他数据库相比,具有哪些明显的优势呢?这可以从以下几个方面来分析,主要表现为查询的高性能、设计的灵活性和开发的敏捷性等。
- 查询的高性能
Neo4j是一个原生的图数据库引擎,它存储了原生的图数据,因此,可以使用图结构的自然伸展特性来设计免索引邻近节点遍历的查询算法,即图的遍历算法设计。图的遍历是图数据结构所具有的独特算法,即从一个节点开始,根据其连接的关系,可以快速和方便地找出它的邻近节点。这种查找数据的方法并不受数据量的大小所影响,因为邻近查询查找的始终是有限的局部数据,而不会对整个数据库进行搜索。所以,Neo4j具有非常高效的查询性能,相比于RDBMS,它的查询速度可以提高数倍乃至数十倍.而且查询速度不会因数据量的增长而下降,即数据库可以经久耐用,并且始终保持最初的活力。不像RDBMS那样,因为不可避免地使用了一些范式设计,所以在查询时如果需要表示一些复杂的关系,势必会构造很多连接,从而形成很多复杂的运算。并且在查询中更加可怕的是还会涉及大量数据,这些数据大多与结果毫无关系,有的可能仅仅是通过ID查找它的名称而已,所以随着数据量的增长,即使查询一小部分数据,查询也会变得越来越慢,性能日趋下降,以至于让人无法忍受。
- 设计的灵活性
在日新月异的互联网应用中,业务需求会随着时间和条件的改变而发生变化,这对于以往使用结构化数据的系统来说,往往很难适应这种变化的需要。图数据结构的自然伸展特性及其非结构化的数据格式,让 Neo4j的数据库设计可以具有很大的伸缩性和灵活性。因为随着需求的变化而增加的节点、关系及其属性并不会影响到原来数据的正常使用,所以使用Neo4j来设计数据库,可以更接近业务需求的变化,可以更快地赶上需求发展变化的脚步。
大多数使用关系型数据库的系统,为了应对快速变化的业务需求,往往需要采取推倒重来的方法重构整个应用系统。而这样做的成本是巨大的。使用Neo4j可以最大限度地避免这种情况发生。虽然有时候,也许是因为最初的设计考虑得太不周全,或者为了获得更好的表现力,数据库变更和迁移在所难免,但是使用Neo4j来做这项工作也是非常容易的,至少它没有模式结构定义方面的苦恼。
- 开发的敏捷性
图数据库设计中的数据模型,从需求的讨论开始,到程序开发和实现,以及最终保存在数据库中的样子,直观明了,似乎没有什么变化,甚至可以说本来就是一模一样的。这说明,业务需求与系统设计之间可以拉近距离,需求和实现结果之间越来越接近。这不但降低了业务人员与设计人员之间的沟通成本,也使得开发更加容易迭代,并且非常适合使用敏捷开发方法。
Neo4j本身可伸缩的设计灵活性,以及直观明了的数据模型设计,以及其自身简单易用的特点等,所有这些优势都充分说明,使用Neo4j很适合以一种测试驱动的方法应用于系统设计和开发自始至终的过程之中,通过迭代来加深对需求的理解,并通过迭代来完善数据模型设计。
- 与其他数据库的比较
在图数据库领域,除Neo4j外,还有其他如OrientDB、Giraph、AllegroGraph等各种图数据库。与所有这些图数据库相比,Neo4j的优势表现在以下两个方面。
(1)Neo4j是一个原生图计算引擎,它存储和使用的数据自始至终都是使用原生的图结构数据进行处理的,不像有些图数据库,只是在计算处理时使用了图数据库,而在存储时还将数据保存在关系型数据库中。
(2)Neo4j是一个开源的数据库,其开源的社区版吸引了众多第三方的使用和推如开源项目Spring Data Neo4j就是一个做得很不错的例子,同时也得到了更多开发者的拥趸和支持,聚集了丰富的可供交流和学习的资源与案例。这些支持、推广和大量的使用,反过来会很好地推动Neo4j的发展。
- 综合表现
Neo4j 查询的高性能表现、易于使用的特性及其设计的灵活性和开发的敏捷性,以及坚如磐石般的事务管理特性,都充分说明了使用Neo4j是一个不错的选择。有关它的所有优点,总结起来,主要表现在以下几个方面。
- 闪电般的读/写速度,无与伦比的高性能表现;
- 非结构化数据存储方式,在数据库设计上具有很大的灵活性;
- 能很好地适应需求变化,并适合使用敏捷开发方法;
- 很容易使用,可以用嵌入式、服务器模式、分布式模式等方式来使用数据库;
- 使用简单框图就可以设计数据模型,方便建模;
- 图数据的结构特点可以提供更多更优秀的算法设计;
- 完全支持ACID完整的事务管理特性;
- 提供分布式高可用模式,可以支持大规模的数据增长;
- 数据库安全可靠,可以实时备份数据,很方便恢复数据;
- 图的数据结构直观而形象地表现了现实世界的应用场景。
2.4 环境部署
2.4.1 运行环境
- python3.0及以上
- neo4j 3.5.0及以上
- jdk 1.8.0
2.4.2 neo4j安装及使用
进官方网站:https://neo4j.com/下载neo4j桌面版或者community版本的,自行安装好。
运行neo4j前,需要安装jdk 1.8.0的版本。配置好环境后,在命令行中输入:java -version,查看是否安装成功。
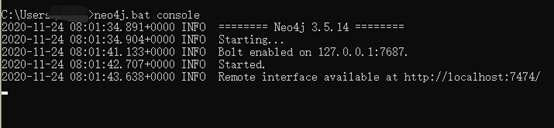
图 2 Neo4j 启动
注:neo4j和jdk都需要配置环境变量!!!
测试neo4j是否安装成功,在命令行中输入:neo4j.bat console,如下图 3 所示:
图 3 测试neo4j是否安装成功
如图 4 所示,已经开启了neo4j数据库,配置成功后,可以在浏览器中使用http://localhost:7474/browser/网址查看数据库,但是前提是得把桌面的应用程序关掉。
注:记住数据库的用户名和密码,一般默认的是:用户:neo4j, 密码:neo4j。
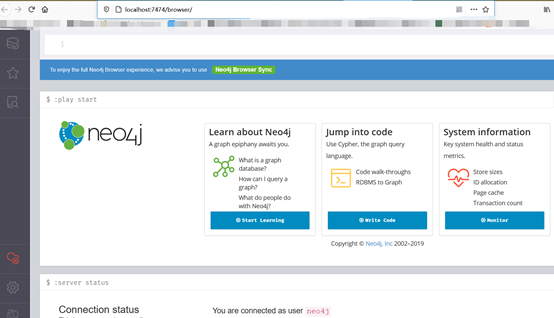
图 4 Neo4j 可视化界面
注:首次登陆会提醒你修改密码!!!
三、Neo4j 数据导入
3.1 数据集简介
-
数据源:39健康网。包括15项信息,其中7类实体,约3.7万实体,21万实体关系。
-
本次组队学习搭建的系统的知识图谱结构如下:
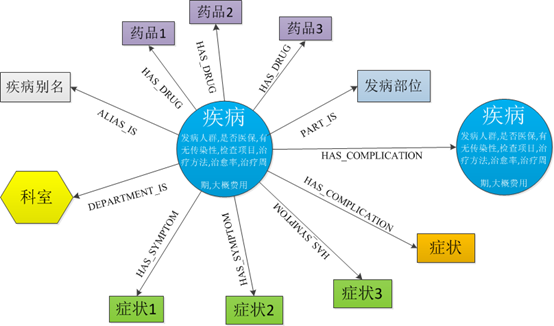
图 5 知识图谱结构
- 知识图谱实体类型
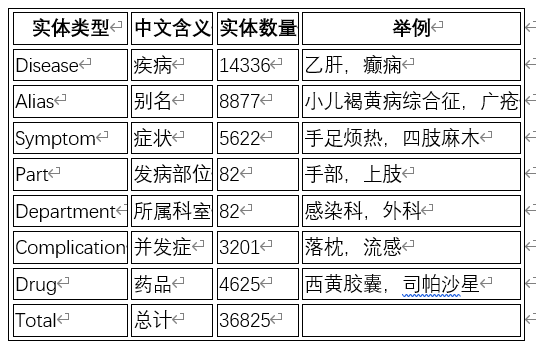
图 6 知识图谱实体类型
- 知识图谱实体关系类型
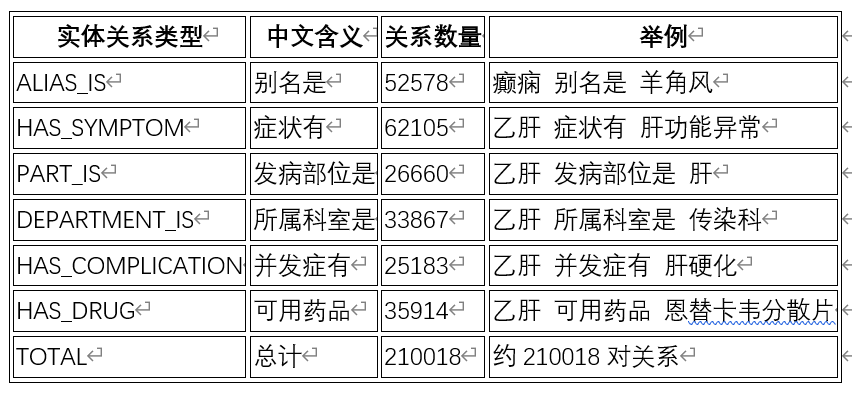
图 6 知识图谱实体关系类型
- 知识图谱疾病属性
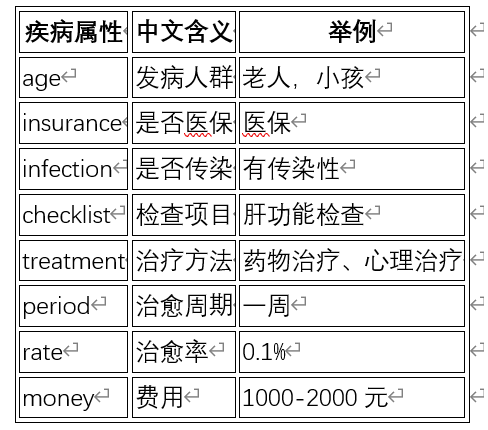
图 7 知识图谱疾病属性
- 基于特征词分类的方法来识别用户查询意图

图 8 基于特征词分类的方法来识别用户查询意图
3.2 数据导入
3.2.1 Neo4j 账号密码设置
要将 数据 导入 Neo4j 图数据库,首先需要 进入 build_graph.py 类中,在 类 MedicalGraph 中 的加入 本地 Neo4j 图数据库 的 账号和密码;
class MedicalGraph:
def __init__(self):
...
self.graph = Graph("http://localhost:7474", username="neo4j", password="自己的")
...
3.2.2 导入 数据
运行 以下命令:
python build_graph.py
注:由于数据量比较大,所以该过程需要运行几个小时
3.3 知识图谱展示
运行介绍之后,打开浏览器进入网址:http://localhost:7474/browser/,可以看到我们导入的数据的知识图谱,如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zNeQKbMI-1610358397016)(assets/展示图.jpg)]](https://img-blog.csdnimg.cn/20210111175312340.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JvY2tfeQ==,size_16,color_FFFFFF,t_70)
图 9 知识图谱 展示图
3.4 主体类 MedicalGraph 介绍
class MedicalGraph:
def __init__(self):
pass
# 读取文件,获得实体,实体关系
def read_file(self):
psss
# 创建节点
def create_node(self, label, nodes):
pass
# 创建疾病节点的属性
def create_diseases_nodes(self, disease_info):
pass
# 创建知识图谱实体
def create_graphNodes(self):
pass
# 创建实体关系边
def create_graphRels(self):
pass
# 创建实体关系边
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
pass
3.5 主体类 MedicalGraph 中关键代码讲解
- 获取数据路径
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'DATA/disease.csv')
- 链接 Neo4j 图数据库
self.graph = Graph("http://localhost:7474", username="neo4j", password="自己设定的密码")
- 读取文件,获得实体,实体关系
这部分代码的核心就是读取 数据文件,并 获取实体和实体关系信息。
- 实体信息:
- diseases 疾病
- aliases 别名
- symptoms 症状
- parts 部位
- departments 科室
- complications 并发症
- drugs 药品
- 实体关系:
- disease_to_symptom 疾病与症状关系
- disease_to_alias 疾病与别名关系
- diseases_to_part 疾病与部位关系
- disease_to_department 疾病与科室关系
- disease_to_complication 疾病与并发症关系
- disease_to_drug 疾病与药品关系
- disease 实体 属性信息:
- name
- age 年龄
- infection 传染性
- insurance 医保
- checklist 检查项
- treatment 治疗方法
- period 治愈周期
- rate 治愈率
- money 费用
def read_file(self):
"""
读取文件,获得实体,实体关系
:return:
"""
# cols = ["name", "alias", "part", "age", "infection", "insurance", "department", "checklist", "symptom",
# "complication", "treatment", "drug", "period", "rate", "money"]
# 实体
diseases = [] # 疾病
aliases = [] # 别名
symptoms = [] # 症状
parts = [] # 部位
departments = [] # 科室
complications = [] # 并发症
drugs = [] # 药品
# 疾病的属性:age, infection, insurance, checklist, treatment, period, rate, money
diseases_infos = []
# 关系
disease_to_symptom = [] # 疾病与症状关系
disease_to_alias = [] # 疾病与别名关系
diseases_to_part = [] # 疾病与部位关系
disease_to_department = [] # 疾病与科室关系
disease_to_complication = [] # 疾病与并发症关系
disease_to_drug = [] # 疾病与药品关系
all_data = pd.read_csv(self.data_path, encoding='gb18030').loc[:, :].values
for data in all_data:
disease_dict = {} # 疾病信息
# 疾病
disease = str(data[0]).replace("...", " ").strip()
disease_dict["name"] = disease
# 别名
line = re.sub("[,、;,.;]", " ", str(data[1])) if str(data[1]) else "未知"
for alias in line.strip().split():
aliases.append(alias)
disease_to_alias.append([disease, alias])
# 部位
part_list = str(data[2]).strip().split() if str(data[2]) else "未知"
for part in part_list:
parts.append(part)
diseases_to_part.append([disease, part])
# 年龄
age = str(data[3]).strip()
disease_dict["age"] = age
# 传染性
infect = str(data[4]).strip()
disease_dict["infection"] = infect
# 医保
insurance = str(data[5]).strip()
disease_dict["insurance"] = insurance
# 科室
department_list = str(data[6]).strip().split()
for department in department_list:
departments.append(department)
disease_to_department.append([disease, department])
# 检查项
check = str(data[7]).strip()
disease_dict["checklist"] = check
# 症状
symptom_list = str(data[8]).replace("...", " ").strip().split()[:-1]
for symptom in symptom_list:
symptoms.append(symptom)
disease_to_symptom.append([disease, symptom])
# 并发症
complication_list = str(data[9]).strip().split()[:-1] if str(data[9]) else "未知"
for complication in complication_list:
complications.append(complication)
disease_to_complication.append([disease, complication])
# 治疗方法
treat = str(data[10]).strip()[:-4]
disease_dict["treatment"] = treat
# 药品
drug_string = str(data[11]).replace("...", " ").strip()
for drug in drug_string.split()[:-1]:
drugs.append(drug)
disease_to_drug.append([disease, drug])
# 治愈周期
period = str(data[12]).strip()
disease_dict["period"] = period
# 治愈率
rate = str(data[13]).strip()
disease_dict["rate"] = rate
# 费用
money = str(data[14]).strip() if str(data[14]) else "未知"
disease_dict["money"] = money
diseases_infos.append(disease_dict)
return set(diseases), set(symptoms), set(aliases), set(parts), set(departments), set(complications), \
set(drugs), disease_to_alias, disease_to_symptom, diseases_to_part, disease_to_department, \
disease_to_complication, disease_to_drug, diseases_infos
- 创建节点
这部分代码主要是为了创建不包含属性的 节点
def create_node(self, label, nodes):
"""
创建节点
:param label: 标签
:param nodes: 节点
:return:
"""
count = 0
for node_name in nodes:
node = Node(label, name=node_name)
self.graph.create(node)
count += 1
print(count, len(nodes))
return
- 创建带有属性节点
def create_diseases_nodes(self, disease_info):
"""
创建疾病节点的属性
:param disease_info: list(Dict)
:return:
"""
count = 0
for disease_dict in disease_info:
node = Node("Disease", name=disease_dict['name'], age=disease_dict['age'],
infection=disease_dict['infection'], insurance=disease_dict['insurance'],
treatment=disease_dict['treatment'], checklist=disease_dict['checklist'],
period=disease_dict['period'], rate=disease_dict['rate'],
money=disease_dict['money'])
self.graph.create(node)
count += 1
print(count)
return
- 创建知识图谱实体
def create_graphNodes(self):
"""
创建知识图谱实体
:return:
"""
disease, symptom, alias, part, department, complication, drug, rel_alias, rel_symptom, rel_part, \
rel_department, rel_complication, rel_drug, rel_infos = self.read_file()
self.create_diseases_nodes(rel_infos)
self.create_node("Symptom", symptom)
self.create_node("Alias", alias)
self.create_node("Part", part)
self.create_node("Department", department)
self.create_node("Complication", complication)
self.create_node("Drug", drug)
return
- 创建知识图谱关系
def create_graphRels(self):
disease, symptom, alias, part, department, complication, drug, rel_alias, rel_symptom, rel_part, \
rel_department, rel_complication, rel_drug, rel_infos = self.read_file()
self.create_relationship("Disease", "Alias", rel_alias, "ALIAS_IS", "别名")
self.create_relationship("Disease", "Symptom", rel_symptom, "HAS_SYMPTOM", "症状")
self.create_relationship("Disease", "Part", rel_part, "PART_IS", "发病部位")
self.create_relationship("Disease", "Department", rel_department, "DEPARTMENT_IS", "所属科室")
self.create_relationship("Disease", "Complication", rel_complication, "HAS_COMPLICATION", "并发症")
self.create_relationship("Disease", "Drug", rel_drug, "HAS_DRUG", "药品")
- 创建实体关系边
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
"""
创建实体关系边
:param start_node:
:param end_node:
:param edges:
:param rel_type:
:param rel_name:
:return:
"""
count = 0
# 去重处理
set_edges = []
for edge in edges:
set_edges.append('###'.join(edge))
all = len(set(set_edges))
for edge in set(set_edges):
edge = edge.split('###')
p = edge[0]
q = edge[1]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.graph.run(query)
count += 1
print(rel_type, count, all)
except Exception as e:
print(e)
return
四、总结
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。Neo4j是一个高度可扩展的本机图形数据库,旨在专门利用数据和数据关系。使用Neo4j,开发人员可以构建智能应用程序,以实时遍历当今大型的,相互关联的数据集。大家工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中,但是可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。














 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









