







本文是关于方面级情感分析的一篇论文,于2019年发表在EMNLP上,下面是对这篇论文的详细介绍。
文章目录
注意机制和卷积神经网络由于其固有的方面和上下文词的语义对齐能力,被广泛应用于基于方面的情感分类。然而,这些模型缺乏一种机制来解释相关的句法约束和长距离单词依赖性,并且可能错误地将句法上不相关的上下文单词识别为判断方面情感的线索。为了解决这个问题,我们建议在句子的依存关系树上建立一个图卷积网络(GCN),以利用句法信息和单词依存关系。在此基础上,提出了一种新的特定方面的情感分类框架。在三个基准测试集合上的实验表明,我们提出的模型具有与一系列最先进的模型1相当的有效性,并且进一步证明了语法信息和长距离单词依赖都被图形卷积结构恰当地捕获。
1 Introduction
尽管基于注意力的模型很有希望,但是它们不足以捕捉上下文词和句子中方面之间的句法依赖性。因此,当前的关注机制可能导致给定的方面错误地将句法上不相关的上下文词作为描述符(限制1)。一个方面的情感通常由关键短语而不是单个单词决定。尽管如此,基于CNN的模型只能通过对单词序列进行卷积操作将多单词特征感知为连续单词,但不足以确定由彼此不相邻的多个单词所表示的情感(限制2)。
在本文中,我们旨在通过使用图卷积网络(GCN)解决上述两个局限性(Kipf和Welling,2017)。 GCN具有多层体系结构,每一层都使用直接邻居的特征来编码和更新图中节点的表示。通过引用语法相关性树,GCN可能能够将语法相关的单词绘制到目标方面,并利用GCN层利用远程多单词关系和语法信息。
据我们所知,它是第一个基于GCN的基于方面的情感分类模型。
ASGCN从双向长期短期记忆网络(LSTM)层开始,以捕获有关单词顺序的上下文信息。为了获得特定于方面的特征,在LSTM输出的顶部实现了多层图卷积结构,然后是masking机制,该机制可过滤掉非方面的单词并仅保留高级方面的特定特征。特定于方面的特征被反馈到LSTM输出,以检索有关该方面的信息性特征,然后将其用于预测基于方面的情感。
我们的贡献如下:
•我们建议利用句子中的句法依存结构,并解决基于方面的情感分类的长距离多词依存问题。
•我们认为图卷积网络(GCN)适合我们的目的,并提出了一种新颖的方面特定的GCN模型。
•广泛的实验结果证明了利用句法信息和远程单词依存关系的重要性,并证明了我们的模型在基于方面的情感分类中捕获和利用它们的有效性。
2 Graph Convolutional Networks
GCN可以看作是常规CNN的改编,用于对非结构化数据的本地信息进行编码。对于具有k个节点的给定图,通过枚举该图获得邻接矩阵A。为方便起见,我们将节点i的第l层的输出表示为hli,其中h0表示节点i的初始状态。对于L层GCN,l∈[1,2,···,L],hLi是节点i的最终状态。对节点表示进行操作的图卷积可写为:
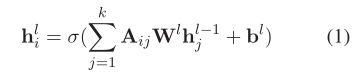
由于图卷积过程仅编码直接邻居的信息,因此图中的节点只能受到L层GCN中L步内的相邻节点的影响。在这样,在句子的依赖树上的图卷积为句子中的一个方面提供了句法约束,以基于句法距离识别描述性词。此外,GCN能够处理用非连续词描述方面的极性的情况,因为依赖树上的GCN会将非连续词收集到较小的范围内,并通过图卷积适当地聚集其特征。因此,我们受到启发,采用GCN来利用句法信息和远程单词依存关系进行基于方面的情感分类。
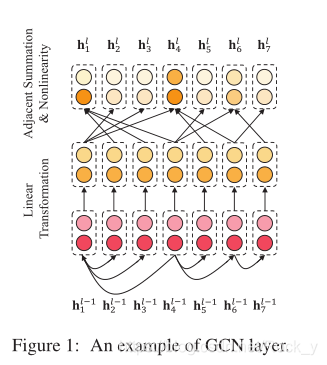
3 Aspect-specific Graph Convolutional Network
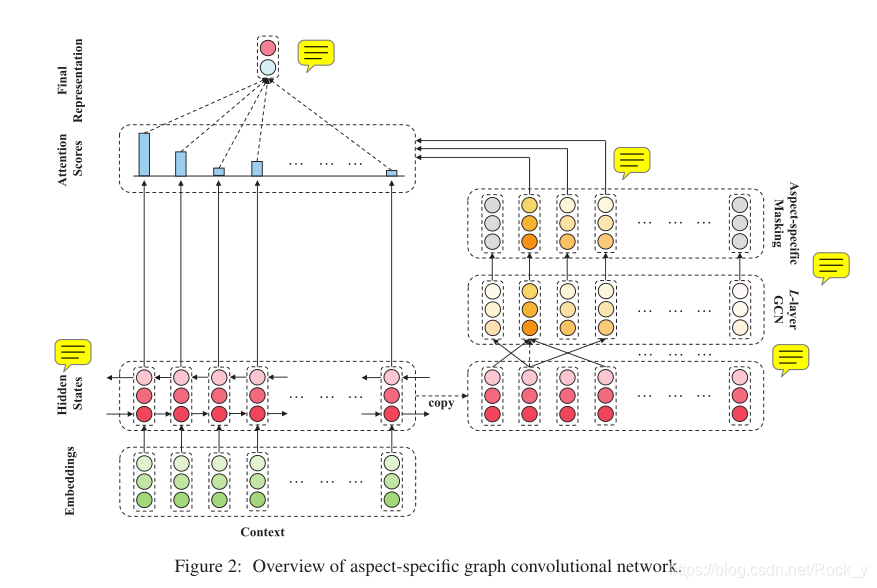
3.1 Embedding and Bidirectional LSTM
给定一个n词句子c = {wc 1,wc 2,···,wcτ+ 1,···,wcτ+ m,···,wc n-1,wc n}包含相应的从第(τ+ 1)个标记开始的m个单词方面,我们将每个单词标记嵌入具有嵌入矩阵E∈R | V |×de的低维实值向量空间(Bengio等,2003),其中| V |是词汇量的大小,表示单词嵌入的维数。利用句子的词嵌入,构造双向LSTM来产生隐藏状态向量Hc = {hc 1,hc 2,···,hcτ+ 1,···,hcτ+ m,···,hc n−1,hc n},其中hct∈R2dh表示从双向LSTM开始的时间步t处的隐藏状态向量,而dh是单向LSTM输出的隐藏状态向量的维数。
3.2 Obtaining Aspect-oriented Features(获得面向方面的特征)
与一般的情感分类不同,基于方面的情感分类的目标是从方面的角度判断情感,因此需要面向方面的特征提取策略。在这项研究中,我们通过在句子的句法依赖树上应用多层图卷积,并在其顶部强加一个特定于方面的屏蔽层,来获得面向方面的特征。
3.2.1 Graph Convolution over Dependency Trees(依赖树上的图卷积)
为了解决现有方法的局限性(如前几节所述),我们在句子的依赖树上利用了图卷积网络。具体而言,在构造给定句子的依存关系树3之后,我们首先根据句子中的单词获得邻接矩阵A∈Rn×n。重要的是要注意依赖树是有向图。尽管GCN通常不考虑方向,但可以将其调整为适合方向感知的情况。因此,我们提出了ASGCN的两个变体,即,在无向的依赖图上的ASGCN-DG,以及在有向的依赖树上的ASGCN-DT。 实际上,ASGCN-DG和ASGCN-DT之间的唯一区别在于它们的邻接矩阵:ASGCN-DT的邻接矩阵比ASGCN-DG的稀疏得多。这样的设置是根据父节点广泛受其子节点影响的现象。此外,遵循Kipf和Welling(2017)中的自循环思想,每个单词都与其相邻位置手动设置,即A的对角线值均为1。
在第3.1节中的双向LSTM输出的基础上,以多层方式执行ASGCN变体,即H0 = Hc以使节点了解上下文(Zhang等人,2018)。然后使用具有规范化因子的图卷积运算更新每个节点的表示(Kipf和Welling,2017),如下所示:
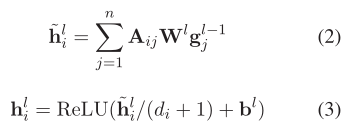
其中gl−1 j是从前一个GCN层演变而来的第j个令牌的表示形式,而hli是当前GCN层的乘积,并且di =?nj = 1Aij是树中第i个令牌的程度。权重Wl and偏重b是可训练参数。
值得注意的是,我们没有立即将其送入连续的GCN层,而是首先进行了位置感知转换:
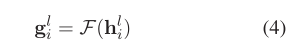
其中F(·)是分配位置权重的函数,以增强与方面相近的上下文词的重要性。通过这样做,我们的目标是减少依赖项解析过程中自然产生的噪声和偏差。具体来说,函数F(·)为:

L层GCN的最终结果是HL={HL 1,HL 2,··,HLτ+1,··,HLτ+m,··,HL n−1,HL n},HL t∈R2dh。
3.2.2 Aspect-specific Masking
在这一层中,我们屏蔽掉非方面词的隐藏状态向量,并保持方面词状态不变:
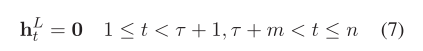
**该零屏蔽层的输出是面向方面的特征HL= {0,,,hL τ+1,,,hL τ+m,,,0}。**通过图形卷积,这些特征HL Mask以一种既考虑句法依存关系又考虑了远程多词关系的方式在方面周围感知了上下文。
3.3 Aspect-aware Attention
基于面向方面的特征,通过新颖的基于检索的注意力机制生成了隐藏状态向量Hc的精确表示。这个想法是从隐藏状态向量中检索与方面单词在语义上相关的重要特征,并因此为每个上下文单词设置基于检索的注意力权重。在我们的实现中,注意力权重计算如下:
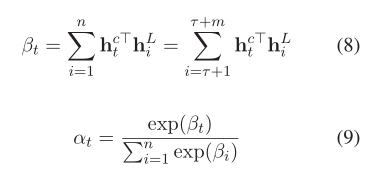
在这里,点积用于测量方面组成词与句子中的词之间的语义相关性,以便特定方面的掩盖(即零掩盖)可以如公式8所示生效。因此,预测的最终表示形式为:
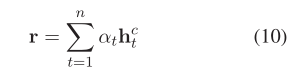
3.4 Sentiment Classification
获得表示r后,将其馈入一个全连接层,然后馈入一个softmax归一化层,以在极性决策空间上产生概率分布p∈Rdp:
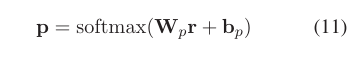
3.5 Training
4 Experiments
4.1 Datasets and Experimental Settings
五个数据集:一个(TWITTER)中包含推特帖子,而其他四个(LAP14,REST14,REST15,REST16)分别来自SemEval 2014任务4,SemEval 2015任务12和SemEval 2016任务5,由笔记本电脑和餐厅两类数据组成。
## 4.2 Models for Comparison
•SVM(Kiritchenko等人,2014)是使用常规特征提取方法赢得SemEval 2014任务4的模型。
•LSTM(Tang等人,2016a)使用LSTM的最后一个隐藏状态向量来预测情绪极性。
•MemNet(Tang等人,2016b)将上下文视为外部存储器,并从多跳架构中受益。
•AOA(Huang等,2018)从机器翻译领域借鉴了注意力过度注意的概念。 •IAN(Ma等人,2017)以交互方式建模方面及其上下文之间的关系。
•TNet-LF(Li等人,2018)提出了上下文保存转换(CPT),以保存和加强上下文的信息部分。
为了检查GCN在何种程度上胜过CNN,我们在实验中还涉及了一个名为ASCNN的模型,该模型在ASGCN中将2层GCN替换为2层CNN。
4.3 Results
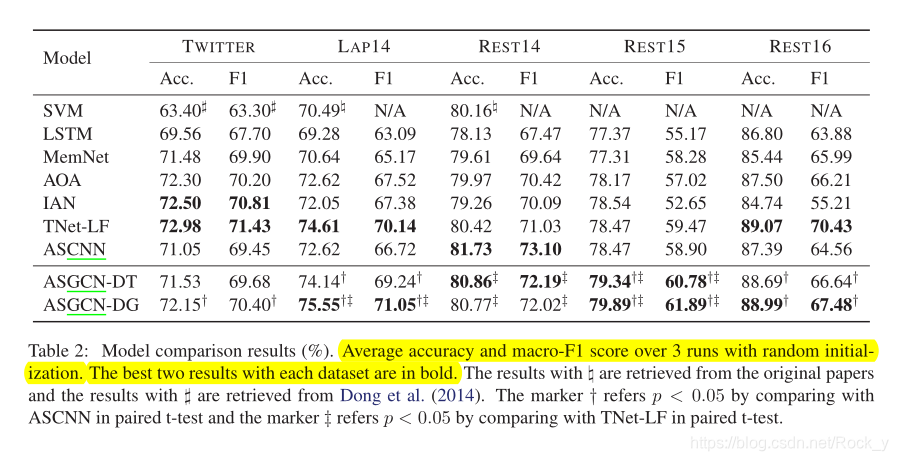
如表2所示,ASGCN-DG在LAP14和REST15数据集上的性能始终优于所有比较模型,并且在TWITTER和REST16数据集上与基线TNet-LF以及在REST14上与ASCNN相比均达到可比的结果。
结果证明了ASGCN-DG的有效性以及将语法信息直接集成到注意力机制中的不足,如He等人所述。 (2018)。同时,在TWITTER,LAP14,Rest15和REST16数据集上,ASGCN-DG的性能要优于ASGCN-DT。而且ASGCN-DT的结果低于LAP14上的TNet-LF的结果。一个可能的原因是,来自父节点的信息与来自子节点的信息一样重要,因此将依赖树视为有向图会导致信息丢失。
此外,除REST14之外,ASGCNDG在所有数据集上的表现均优于ASCNN,这说明ASGCN在捕获远程单词依存关系方面更胜一筹,而ASCNN在某种程度上显示了特定于方面的屏蔽带来的影响。我们怀疑REST14数据集对语法信息不太敏感。此外,TWITTER数据集中的句子语法较少,从而限制了效果。我们推测这可能是ASGCN-DG和ASGCN-DT在TWITTER数据集上获得次优结果的原因。
4.4 Ablation Study
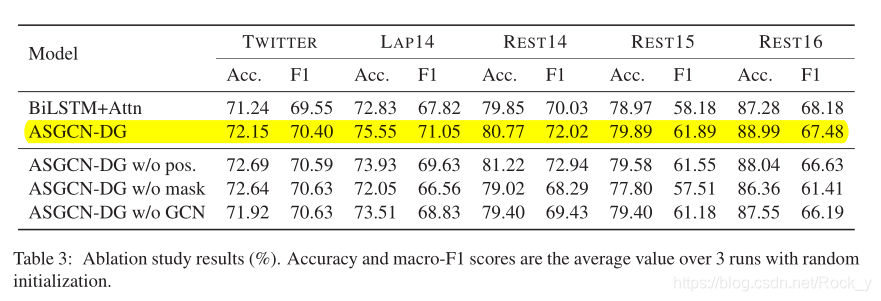
为了进一步检查ASGCN的每个组件带来的收益水平,对ASGCN-DG进行了消融研究。结果显示在表3中。我们还提供了BiLSTM + Attn的结果作为基线,该基线分别使用两个LSTM作为方面和上下文。
首先,移除位置权重(即ASGCN-DG w / o pos)会导致LAP14,REST15和REST16数据集的性能下降,但TWITTER和REST14数据集的性能会提高。回想一下REST14数据集的主要结果,我们得出的结论是,如果语法对数据不重要,则位置权重的集成无助于减少用户生成内容的噪声。 而且,在摆脱了特定于方面的mask(即不带mask的ASGCN-DG)之后,该模型无法保持与TNet-LF一样的竞争力。这验证了特定于方面的掩盖的重要性。
与ASGCN-DG相比,不带GCN的ASGCN-DG(即保留位置权重和特定于方面的遮罩,但不使用GCN图层)在TWITTER数据集上的所有五个数据集上除F1度量外都无能为力。但是,由于方面特定的掩盖机制的优势,在除REST14数据集之外的所有数据集上,不带GCN的ASGCNDG仍比BiL-STM + Attn稍好。
因此可以得出结论,因为GCN同时捕获了句法性的单词依赖性和远程单词关系,所以GCN在很大程度上有助于ASGCN。 尽管如此,正如我们在TWITTER和REST14数据集中看到的那样,GCN在对语法信息不敏感的数据集上并没有达到预期的效果。
4.5 Case Study
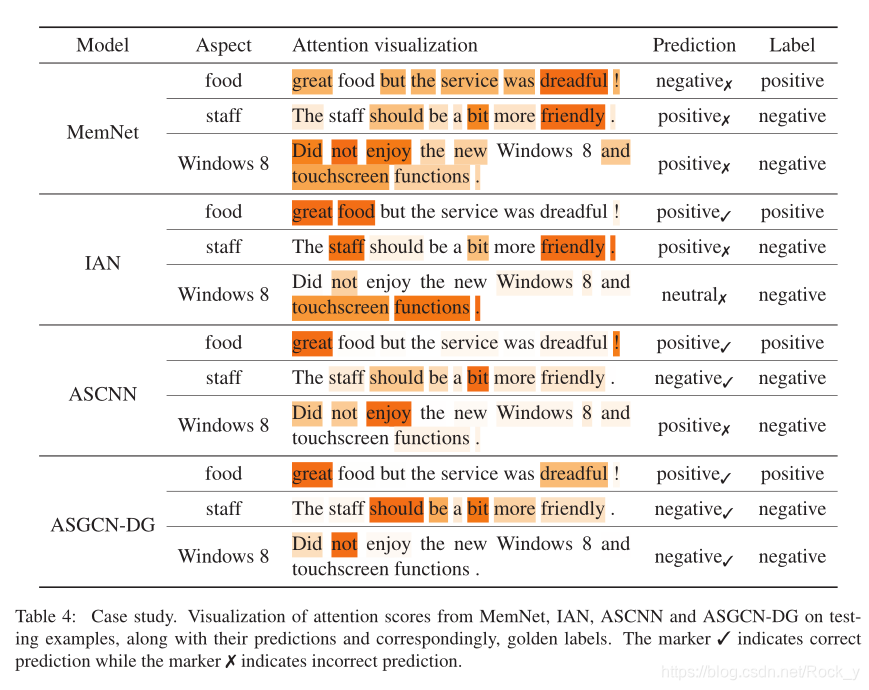
第一个样本"美味的食物,但是服务真糟糕!"一句话中有两个方面,这可能会妨碍基于注意力的模型将这些方面与其相关的描述性词精确对齐。第二个示例句子"员工应该更友好一点。“使用虚拟词"应该”,给检测隐式语义带来额外的困难。最后一个示例在句子中包含否定词,这很容易导致模型做出错误的预测。
MemNet在所有三个示例中均失败。尽管IAN可以针对不同方面使用不同的修饰语,但它无法推断具有特殊样式的句子的情感极性。有了位置权重,ASCNN可以正确预测第二个样本的标签,因为该短语应该与方面人员接近,但对于第三个样本,则具有较长的单词依赖性。我们的ASGCN-DG正确处理了所有三个样本,这意味着GCN有效地将语法相关性信息集成到了丰富的语义表示中。特别地,ASGCNDG对第二个和第三个样本做出正确的预测,这两个样本都具有看似偏向的焦点。这表明ASGCN能够捕获远程多字功能。
5 Discussion
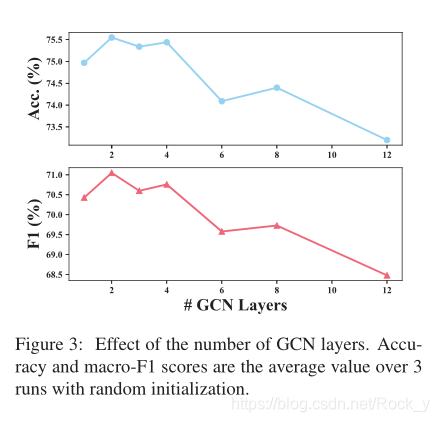
5.1 Investigation on the Impact of GCN(GCN层影响的调查)
由于ASGCN涉及L层GCN,因此我们研究了层号L对ASGCN-DG最终性能的影响。
5.2 Investigation on the Effect of Multiple Aspects

在数据集中,一个句子中可能存在多个方面的术语。因此,我们打算测量这种现象是否会影响ASGCN的有效性。 我们根据句子中方面词的数量将LAP14和REST14数据集中的训练样本分为不同的组,并计算这些组之间的训练精度差异。值得注意的是,将具有7个以上方面的样本作为异常值删除,因为这些样本的大小对于任何有意义的比较而言都太小了。
从图4中可以看出,当句子中的方面数大于3时,准确性会发生波动, 这表明在捕获多方面相关性方面的鲁棒性较低,这表明在将来的工作中需要对多方面相关性进行建模。
6 Related Work
在单词序列上构建神经网络模型,例如CNN(Kim,2014; Johnson and Zhang,2015),RNN(Tang等,2016a)和递归卷积神经网络(RC-CNNs)在情感分析中取得了可喜的表现。但是,人们也认识到了利用依赖树来捕获单词的远距离关系的有效机制的重要性,但缺乏这种机制。 Tai等。 (2015年)表明,具有依赖树或选区树的LSTM优于CNN。董等。 (2014年)提出了一种使用依赖树的自适应递归神经网络,与强基线相比,该网络取得了竞争性结果。最近的研究表明,一般的基于依赖的模型很难获得与基于注意力的模型相当的结果,因为依赖树无法正确捕获长期的上下文语义信息。我们的工作通过采用图卷积网络(GCN)克服了这一局限性(Kipf and Welling,2017)。
GCN最近在人工智能领域引起了越来越多的关注,并已应用于自然语言处理(NLP)。 Marcheggiani and Titov(2017)声称GCN可以被认为是LSTM的补充,并提出了基于GCN的语义角色标记模型。 V ashishth等。 (2018)和Zhang等。 (2018)分别在文档约会和关系分类中使用了依赖树上的图卷积。姚等。 (2018)将GCN引入到利用文档单词和单词-单词关系的文本分类中,并在各种最新方法上获得了改进。我们的工作通过图卷积深入研究了依赖树的影响,并开发了特定于方面的GCN模型,该模型与LSTM架构和注意力机制集成在一起,可以更有效地基于方面进行情感分类。
7 Conclusions and Future Work
我们重新审视了针对特定方面的情感分类的现有模型所面临的挑战,并指出了图卷积网络(GCN)应对这些挑战的适用性。因此,我们提出了一种新颖的网络来采用GCN进行基于方面的情感分类。实验结果表明,GCN通过利用句法信息和远程单词依存关系为整体性能带来好处。
该研究可能会在以下方面得到进一步改进。首先,这项工作没有利用句法依赖树的边缘信息,即每个边缘的标签。我们计划设计一种考虑边缘标签的特定图神经网络。其次,可以合并领域知识。最后但并非最不重要的是,可以通过捕获方面词之间的依赖性来扩展ASGCN模型以同时判断多个方面的情感。

















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









