







最近正在看《
Virtual Machines: Versatile Platforms for Systems and Processes
》,发现在虚拟机层面涉及了很多热点技术,当然,处理器、
OS
、
Compiler
等等,都是重点,这里要继续处理器的学习,很多精彩技术,我就再接再厉,及时看看有没有可以相互借鉴的地方。
概念
7
:
Predication (
论断
)
Branch Instructions really hurt the performance. – The processor pipeline is flushed, and the instruction cache is potentially flushed.
为什么分支结构指令会导致性能受损?
因为
CPU
的执行过程是从
Memory
里面取数据,然后即将执行的数据放在
Cache
里面,但是
Branch Instruction
的存在有可能会引导
CPU
去执行一个非常“突兀”的指令,这个指令要么不在
Cache
里面
,要么在
Cache
里面很远的地方
,都会使
Cache
里面的数据处于基本无效的状态,需要重新执行前面的行动,很多操作都相当于“无用功”。为什么要引入
if-then
结构的
Instruction branch
呢?
——这是带入
Standard Branch
的好处,至少可以知道下一步会去哪里,而不是突然冒出一个指令,引入“突兀”操作。什么叫做
Flush
呢?为什么要
Flush
?
——
Flush
就是放弃现在手上正在执行的一堆指令,重新
Load
新的指令,然后重新执行。而且
Flush
是无法避免的
,我们所能够做的就是尽量限制不得不
Flush
的那堆数据
/
指令的大小
,通过利用
Standard branch
,利用
Predication
技术,可以找出即将执行的指令和潜在执行的指令,然后这些就是经过限制后的数量最少
/
带来影响最少的那堆数据
/
指令
,然后我们就把
Flush
的损失控制在了最小。这里再给出一个更加专业的术语,那就是
Cache Flush
和
Pipeline Flush
,前者是没有采用
Predication
技术的时候,
CPU
利用率不够的情况下,出现的症状,后者是采用了
Predication
技术,提高了
CPU
利用率的时候,仍然需要付出的代价。
|
Predicate logic
is where you execute both branches of the code stream before you have figured out which of the branches you are going to take.
You can execute instructions from both potential branch targets, while you are executing the instruction (often a load followed by a compare) to figure out which branch you are going to take. Then you simply throw away all of the results from the branch you *didn’t* take, and continue on with the results of the branch you did take. This is often a huge win, because it optimizes the use of the cache and it doesn’t force you to stall the entire job and all of its threads waiting for a memory fetch.
——后面仍有不足,但已经是经过优化的结果了。
We still have are branches and the costly penalties associated with making the wrong choice – pipeline flushes
。
|
Every if-then statement is potentially a branch. – But only potentially, because we might not take the branch.
前面已经讲过了采用“标准分支”的好处,那就是可以将
Cache Flush
控制在
PipeLine Flush
,同时,还有另外一项技术“推理技术
– Speculation
”或者
data Speculation
技术,
With the Speculation architecture we have support for setting predicates that will tell us what branch path is valid in our code. We simply execute the entire branch then proceed with only those instructions with the ‘branch True’ flag and discard the rest. Since we prepared to execute either path we have no stall.
最后,上面说的这两项技术
– Predication and Speculation
,需要占用额外的
Silicon
空间(
from the PHY perspective
),那么我们的做法是什么呢?做在
Compiler
里面,而不是集成在
CPU
上面,就是专门开辟出
PHY
上的全新的空间,
Compiler
,然后提升
CPU
的利用率。看文章评价:
Having the compiler make this choice (like Itanium with bundling) allows you to increase the performance of your application simply by re-compiling and then running it on the same processor.
附录:来自网络的关于
Predication
和
Speculation
的释义。
|
预测技术(
Predication
)
CPU
使指令并行性达到最大的一个关键因素
是对如何处理判定点以作出正确的判定。传统的结构不能在指令流上超前很远,因此,必须多次推测判定点后的哪个指令流是正确的指令流。为了避免错误地预测执行哪个分支/指令流,目前的
CPU
可以设法智能猜测
(
“分支预测”
)
,运行不同流水线上的两个指令流
(
推测执行
)
,或当
CPU
利用不足时,执行一个或两个分支
(
无序执行
)
。这些策略多半时间不能充分利用
CPU
的并行性,
Intel
估计,这些结构的“被错误预测的分支”
(
执行错误的指令流
)
可损失高达
40%
的
CPU
性能。
在
IA-64
中,预测采取了一种新的处理条件分支的方法。在
CPU
接收代码之前,解决编译器中“超前”这个问题,即编译器同时调度一些等待执行的分支。预测可以把分支移到任何可能的地方。
IA-64
还把有关每个分支的详细情况告诉
CPU
,这样,
CPU
就可以更好地去做推测正确的指令流的工作。
推理技术(
Speculation
)
处理器有时因等待从相对低速的存储器完成装入而空闲着,推理技术就是针对减少处理器的空闲时间而引入的。在
CPU
准备接收指令前,推理技术从主存或缓存尽可能早地装入指令,因而当某些指令需要从存储器输入数据时,处理器就不会空闲着。实际上,推理是把指令和数据缓存在
CPU
本身中
。
IA-64
还能把预测和推测结合起来,通过预测消除许多分支,通过推理加快推理执行或提高对剩余分支的分支预测。推理对频繁访问缓存的应用程序特别有效,因为这些应用程序需要迅速地把指令和数据送到
CPU
上。例如,大型
Internet
和数据库应用程序必须在大量终端用户之间快速切换。推测可将每个新终端用户指令和数据“预发送”到
CPU
,通过这一技术,编码指令与其它指令一同进行处理,总体的处理时间大大缩短。
|
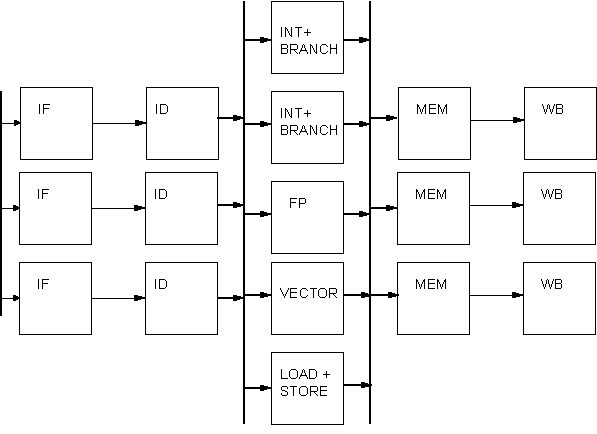
概念
8
:
Pipelining
对于
pipelining
,一个最简单的
Model
有
5
个
Stage
:
Instruction Fetch, Instruction Decode, Execution, Memory Access, Writeback
Pipelining is a natural method of attempting to speed up program execution and the most common form of parallelism around. Its use in computers as a performance enhancing mechanism can be traced back to the late 50s/early 60s, which is remarkably close to the start of the computing era. Most current reasonably state-of-the-art machines are quite heavily pipelined. A common aim in processor design is to increase instruction level parallelism (ILP), though a more useful measure is Cycles per Instruction (CLI) – the lower the better.
The principle of a pipelined processor is that of the assembly line — many components are in different stages of construction at once. The stages of the assembly line are arranged so they all take the same amount of time, and once every time cycle, a new product drops off the end — which may have taken hours to progress from start to finish.
This is a critical point: the length of time an individual instruction takes to execute (latency) is irrelevant. What is important is the total throughput; the length of time a whole block of instructions takes to execute. In practice, an individual instruction is likely to take longer to execute, because of the overheads imposed by implementing pipelining.
现实中的处理器通常有更多的执行
Stage
,对于执行
Stage
的数目,这里有一个
Trade-off between “
执行效率
”
和
”
设计复杂度
”
。
Long pipelines increase Instruction Level Parallelism (ILP) / Short pipelines reduce the chance of dependency stalls, and reduce the number of times the pipeline is completely empty because of a branch / Each processor designer makes difference choices
概念
9
:
Virtualization Topics
每个
Processor
拥有不同的优先级,
different privilege levels
;
OS
需要在较高
Privilege Level
上执行;——但是,在同一台
Server
上运行多个
OS
的时候,因为
OS
可以操作的
Processor level
高级,很可能会造成
Security
方面的冲突。这时候,利用
VM
软件,可以很好地控制每个“
The VM’s “fix up” the guest operating systems, so they never run at the highest privilege level
”,还有可以保证
Security
“
AMD and Intel implement a higher privilege level (VMX Root), allowing solid security between the guest instances
”,似乎是类似于
Physical Isolation
的效果。















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









