






#先要检查配置环境
pip show numpy/pandas/matplotlib
一、pandas数据分析
Pandas是一种基于Numpy的开源的数据分析包,提供了高性能、简单易用的数据结构和数据分析函数。
1、Series对象
(1)定义和创建
(2)数据访问
(3)常用方法
(1)定义和创建
Series对象是一种带有标签数据的一维数据,标签在Pandas中有对应的数据类型“Index”,Series类似于一维数组与字典的结合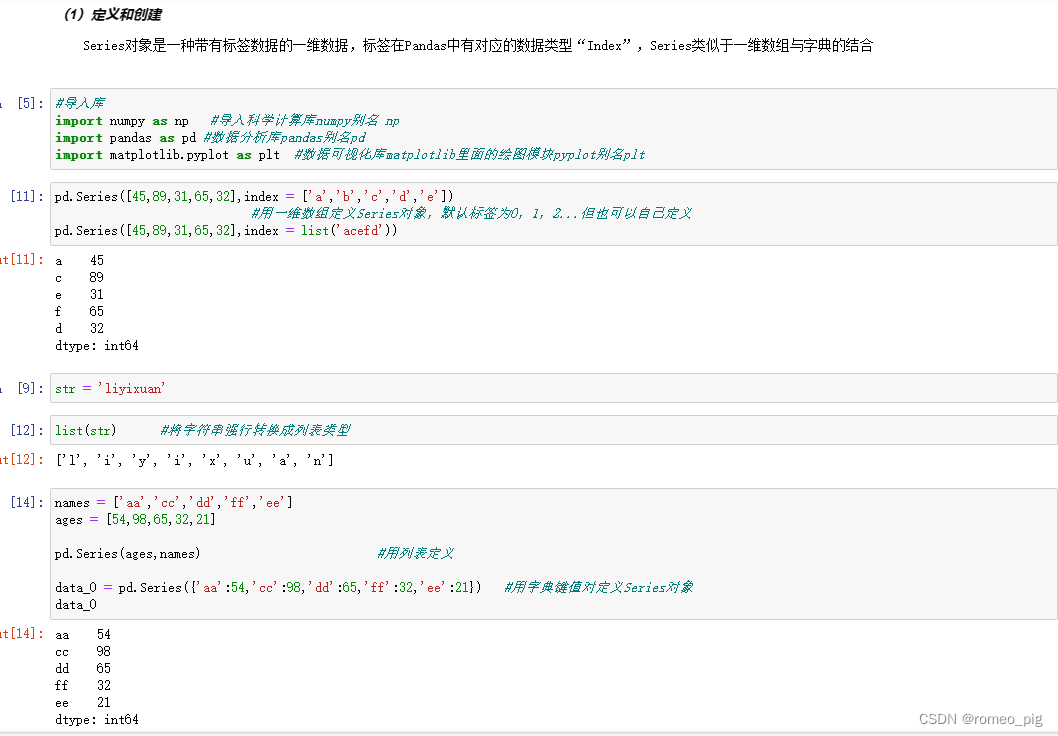


2、DataFrame对象
(1)定义与创造
DataFrame可以看作是一种既有行索引,又有列索引的二维数组,类似于Excel表或关系型数据库中的二维表,是Pandas中最常用的基本结构
(2)数据访问
(3)常用方法
(4)常见操作
(1)Pandas中的缺失值处理
(2)Pandas中的分组操作
(3)Pandas中的数据合并操作
names = ['aa','cc','dd','ff','ee']
ages = [54,98,65,32,21]
nums = [11,22,33,44,66]
s_1 = pd.Series(names)
s_2 = pd.Series(ages)
#print(s_1) #将数据输出到客服端
#print()
s_2 #直接从内容中读取数据,没有对外输出,会被后面的输出数据覆盖
print(pd.DataFrame({'学号':nums,'姓名':s_1,'年龄':s_2})) #用Series对象创建DataFrame对象
data_2 = pd.DataFrame({'学号':nums,'姓名':names,'年龄':ages},index = list('abcde'))#用数组创建
data_2学号 姓名 年龄 0 11 aa 54 1 22 cc 98 2 33 dd 65 3 44 ff 32 4 66 ee 21
Out[49]:
| 学号 | 姓名 | 年龄 | |
|---|---|---|---|
| a | 11 | aa | 54 |
| b | 22 | cc | 98 |
| c | 33 | dd | 65 |
| d | 44 | ff | 32 |
| e | 66 | ee | 21 |
#导入库
import numpy as up
import pandas as pd
import matplotlib.pyplot as plt
#1.使用Pandas读取两个表格数据,并将其根据姓名进行合并
data_1 = pd.read_excel('../Stu_pack/pandas/exer_1.xlsx',skiprows = 1) #读取文件数据
data_2 = pd.read_excel('../Stu_pack/pandas/exer_2.xlsx',skiprows = 1)
data_1
data_2
data_3 = pd.merge(data_1,data_2) #根据相同列名合并数据
data_3
| 姓名 | 性别 | 班级 | 语文 | 数学 | 英语 | 总分 | |
|---|---|---|---|---|---|---|---|
| 0 | Aa | 男 | 2班 | 83 | 78 | 98 | 259 |
| 1 | Bb | 男 | 3班 | 67 | 93 | 56 | 216 |
| 2 | Cc | 女 | 3班 | 59 | 86 | 86 | 231 |
| 3 | Dd | 男 | 3班 | 75 | 60 | 59 | 194 |
| 4 | Ee | 女 | 3班 | 81 | 81 | 79 | 241 |
| 5 | Ff | 女 | 1班 | 68 | 67 | 95 | 230 |
| 6 | Gg | 女 | 1班 | 61 | 80 | 75 | 216 |
| 7 | Hh | 女 | 1班 | 89 | 70 | 96 | 255 |
| 8 | Ii | 女 | 3班 | 62 | 55 | 90 | 207 |
| 9 | Jj | 男 | 3班 | 68 | 91 | 94 | 253 |
| 10 | Kk | 女 | 2班 | 86 | 77 | 51 | 214 |
| 11 | Ll | 男 | 1班 | 88 | 72 | 78 | 238 |
| 12 | Mm | 男 | 2班 | 85 | 91 | 59 | 235 |
| 13 | Nn | 男 | 3班 | 80 | 65 | 76 | 221 |
| 14 | Oo | 女 | 3班 | 70 | 96 | 68 | 234 |
| 15 | Pp | 男 | 1班 | 76 | 78 | 98 | 252 |
| 16 | 女 | 1班 | 78 | 68 | 67 | 213 | |
| 17 | Rr | 女 | 1班 | 78 | 68 | 67 | 213 |
| 18 | Ss | 女 | 2班 | 77 | 51 | 90 | 218 |
| 19 | Tt | 男 | 3班 | 67 | 98 | 99 | 264 |
| 20 | Uu | 女 | 3班 | 68 | 67 | 78 | 213 |
| 21 | Vv | 女 | 3班 | 98 | 77 | 51 | 226 |
| 22 | Ww | 女 | 3班 | 77 | 51 | 89 | 217 |
| 23 | Xx | 男 | 1班 | 89 | 89 | 67 | 245 |
| 24 | Yy | 女 | 1班 | 77 | 51 | 56 | 184 |
| 25 | Zz | 男 | 2班 | 56 | 68 | 67 | 191 |
#2.实现接总分 或 语文、数学、英语单科从高到低排序功能:
def sort(df,col):
ss = df.sort_values(by = col,ascending = False)
#将DataFrame对象df按照某列的数据值排序,默认为升序,将ascending设置为False降序(从高到低)
return ss
col = input('请输入您要排序的列名:')
sort(data_3,col) #调用函数,将实参传递给形参
请输入您要排序的列名:总分
Out[75]:
| 姓名 | 性别 | 班级 | 语文 | 数学 | 英语 | 总分 | |
|---|---|---|---|---|---|---|---|
| 19 | Tt | 男 | 3班 | 67 | 98 | 99 | 264 |
| 0 | Aa | 男 | 2班 | 83 | 78 | 98 | 259 |
| 7 | Hh | 女 | 1班 | 89 | 70 | 96 | 255 |
| 9 | Jj | 男 | 3班 | 68 | 91 | 94 | 253 |
| 15 | Pp | 男 | 1班 | 76 | 78 | 98 | 252 |
| 23 | Xx | 男 | 1班 | 89 | 89 | 67 | 245 |
| 4 | Ee | 女 | 3班 | 81 | 81 | 79 | 241 |
| 11 | Ll | 男 | 1班 | 88 | 72 | 78 | 238 |
| 12 | Mm | 男 | 2班 | 85 | 91 | 59 | 235 |
| 14 | Oo | 女 | 3班 | 70 | 96 | 68 | 234 |
| 2 | Cc | 女 | 3班 | 59 | 86 | 86 | 231 |
| 5 | Ff | 女 | 1班 | 68 | 67 | 95 | 230 |
| 21 | Vv | 女 | 3班 | 98 | 77 | 51 | 226 |
| 13 | Nn | 男 | 3班 | 80 | 65 | 76 | 221 |
| 18 | Ss | 女 | 2班 | 77 | 51 | 90 | 218 |
| 22 | Ww | 女 | 3班 | 77 | 51 | 89 | 217 |
| 1 | Bb | 男 | 3班 | 67 | 93 | 56 | 216 |
| 6 | Gg | 女 | 1班 | 61 | 80 | 75 | 216 |
| 10 | Kk | 女 | 2班 | 86 | 77 | 51 | 214 |
| 16 | 女 | 1班 | 78 | 68 | 67 | 213 | |
| 17 | Rr | 女 | 1班 | 78 | 68 | 67 | 213 |
| 20 | Uu | 女 | 3班 | 68 | 67 | 78 | 213 |
| 8 | Ii | 女 | 3班 | 62 | 55 | 90 | 207 |
| 3 | Dd | 男 | 3班 | 75 | 60 | 59 | 194 |
| 25 | Zz | 男 | 2班 | 56 | 68 | 67 | 191 |
| 24 | Yy | 女 | 1班 | 77 | 51 | 56 | 184 |
#3.打印所有存在不及格科目(单科<60)的学生记录:
data_3[(data_3['语文']<60) | (data_3['数学']<60) | (data_3['英语']<60)]| 姓名 | 性别 | 班级 | 语文 | 数学 | 英语 | 总分 | |
|---|---|---|---|---|---|---|---|
| 1 | Bb | 男 | 3班 | 67 | 93 | 56 | 216 |
| 2 | Cc | 女 | 3班 | 59 | 86 | 86 | 231 |
| 3 | Dd | 男 | 3班 | 75 | 60 | 59 | 194 |
| 8 | Ii | 女 | 3班 | 62 | 55 | 90 | 207 |
| 10 | Kk | 女 | 2班 | 86 | 77 | 51 | 214 |
| 12 | Mm | 男 | 2班 | 85 | 91 | 59 | 235 |
| 18 | Ss | 女 | 2班 | 77 | 51 | 90 | 218 |
| 21 | Vv | 女 | 3班 | 98 | 77 | 51 | 226 |
| 22 | Ww | 女 | 3班 | 77 | 51 | 89 | 217 |
| 24 | Yy | 女 | 1班 | 77 | 51 | 56 | 184 |
| 25 | Zz | 男 | 2班 | 56 | 68 | 67 | 191 |
#4.获取指定科目的最高分、最低分以及平均分:
def get_course(df,col):
mm = np.max(df[col]) #求最高分
nn = np.min(df[col]) #求最低分
cc = np.mean(df[col])#求平均分
return '科目为:{},最高分为:{},最低分为:{},平均分为:{:.2f}'.format(col,mm,nn,cc)
col = input('请输入您要查找的科目:')
get_course(data_3,col)
请输入您要查找的科目:总分
Out[80]:
'科目为:总分,最高分为:264,最低分为:184,平均分为:226.15'















 2245
2245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









