







数据库对象
索引

2.创建索引的目的和方式
使用索引加速数据查询的速度,减少磁盘I/O的次数,但同时也会增加系统维护索引的开销;
创建索引方式:
(1)隐式创建:DBMS一般会在创建 PRIMARY KEY 和 UNIQUE 约束列上自动建立索引;
(2)显式创建:使用 CREATE INDEX 语句创建。
4.删除索引
一般格式:
DROP INDEX <表名>.<索引名称>
说明:
用户只能删除自己建立的索引;
✏例1:对XS表的姓名列创建索引。
create index idx_xs_sname on xs(sname);
select * from xs where sname like '%王';
创建索引之后,系统会自动调用索引表
✏例2:对XS表的姓名列创建唯一索引。
create unique index xs_sname_uniq_idx on xs(sname);
✏例3:为CJ表创建学号列和课程号列的复合索引
create index idx_cj_snocno on cj(sno,cno);
索引创建之后要严格按照创建格式匹配字段
为CJ表创建学号列和课程号列的复合索引之后,
select * from cj where sno='001101' ;不会调用索引
select * from cj where sno='001101' and cno='101';会调用索引
✏例4:为Stu表按姓名升序建立索引,索引名为sn ame_idx
create index sname_idx on stu('select * from stu order by sname asc');
✏例5:删除索引sname_idx。
drop index sname_idx;
5.索引的说明
-
表越大,索引越能有效地改善查询的响应时间,对于少于100行的表建立索引可能不合算;
-
对WHERE子句中最常使用的列建立索引。对连接列建立索引,也可大大地改善连接查询的速度;
-
只要可能,尽量将索引列定义为NOT NULL;
-
一个表上最多可创建16个索引;
-
应根据需要建立索引,应当在查询速度和插入更新速度之间进行权衡。通常不要在一个表上建立多于三个索引。
视图
简单地说,视图可以看成是一个窗口,它所反映的是一个表或若干表的局部数据。视图一经定义,用户就可以把它当作表一样来查询数据。
视图和基本表不同,视图是一个虚表,即视图储存的是查询语句而不是查询结果。
视图是定义在基本表上的,也可以定义在视图上;一个视图可在几个表或视图上建立,一个表或视图也可建立多个视图。

1.视图定义
CREATE [OR REPLACE] VIEW <视图名>
AS <子查询>
[WITH CHECK OPTION] 带有检查项
[WITH READ ONLY] 只读
- 执行CREATE VIEW语句时只是把视图定义存入数据字典,并不执行其中的SELECT语句。
- WITH CHECK OPTION表示对视图进行UPDATE, INSERT和DELETE操作时要保证更新、插入和删除的行满足视图定义中的谓词条件。
- 如果子查询中包含有计算列,则必须指定列名(别名)。
✏例1:建立计算机系的学生视图xs_dept_view 。
creat view xs_dept_view as
select * from xs where dept ='计算机';//一次查询
简化了查询语句,之后再查
select * from xs_dept_view;
✏例2:把学生的学号及它的平均成绩定义为视图cj_avg_view
create view cj_avg_view
as
select sno,avg(grade) avg_grade from cj group by sno;
注意:要使用别名 avg_grade 命名 avg(grade)
2.视图的使用
✏例:求平均成绩为90分以上的学生的学号和成绩。
select * from cj_avg_view where avg_grade>90;
3.视图的更新
对视图的更新最终要转换成对基本表的更新,但实际上,在RDBMS中,并非所有的视图都是可以更新的,有些视图的更新不能唯一地有意义地转换成对基本表的更新。
✏例:将‘001101’学生的平均成绩修改为90分。
update cj_avg_view set avg_grade=70 where sno='001101';
这样是无法成功的,因为视图保存的是查询语句,而avg_grade是别名,基本表里没有该字段。
4.视图的删除
DROP VIEW <视图名>
✏例:删除视图cj_avg_view
Drop view cj_avg_view ;
数据库的三级模式结构
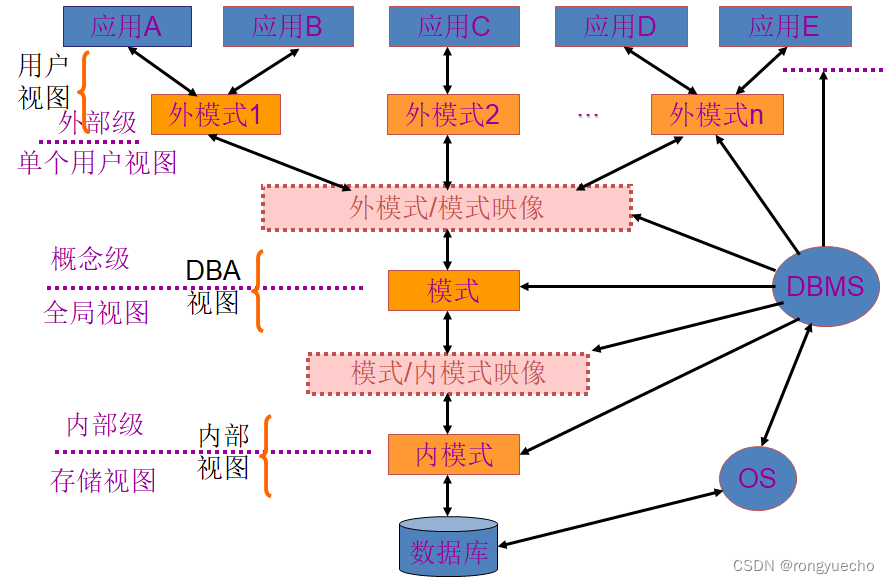
数据库三层模式/两级映象的好处
方便了用户的使用,简化了用户的接口;
实现了数据的独立性;
物理数据独立
逻辑数据独立
有利于数据共享;
有利于数据的安全和保密;
同义词
1.概述
- 通过同义词可以给表、索引、视图等数据库对象创建一个别名,来隐藏一些信息,提供一定的安全性。
- 当DBA改变数据库对象的名称时,通过同义词可以避免前台应用程序的改变。
- 同义词分公有和私有,公有同义词每个用户都能使用,私有同义词必须具有访问权限的用户才能使用。
2.格式:
CREATE [OR REPLACE] [PUBLIC]SYNONYM <同义词名> FOR <对象名>
✏例1:创建公共同义词cj_v访问视图cj_avg_view
create public synonym cj_v for cj_avg_view;
✏例2:创建私有同义词cj_view访问视图cj_avg_view
create or replace synonym cj_view for cj_avg_view;
序列
1.概述
- 序列是ORACLE提供的用于生成一系列唯一数值的数据库对象,以实现自动提供唯一的主键值。
- 序列可以为多个用户并发环境中使用,为多个用户生成不重复的顺序数值。
2.格式:
CREATE SEQUENCE <序列名>
START WITH n 开始值
INCREMENT BY n 自增
(2)目的:创建自增主键值
(3)取值:<对象名>.nextval 查值: <对象名>.currval
✏例1:创建一个Sc1(SID,SNO,CNO,TNO,GRADE)表,将SID定义为自增型的主键。并向其中添加两条记录验证。
--创建表
create table Sc1(
sid int primary key,
sno char(5),
cno char(3),
tno char(6),
garade decimal(3,1));
--创建序列
create sequence sin_sqn;
--插入两行数据
insert into sc1 values(sin_sqn.nextval,'1','1','1',80);
insert into sc1 values(sin_sqn.nextval,'1','1','1',90);















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









