







Machine Learning and algorithm
K Nearest Neighbor
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier # classifier
from sklearn.preprocessing import StandardScaler # standard
from sklearn.model_selection import train_test_split #split data
#read data
data=pd.read_csv('data/---.csv')
data.head()
# feature,score
x=data[['--','---','---']] #array_x should be two-dimensional
y=data[['target--']] #score
# split data
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=24) #test_size-the test data ratio。random_state---set casually,migrate easily
# standard
sc=StandardScaler()
new_x_train=sc.fit_transform(x_train)
new_x_test=sc.transform(x_test)
# machine learning
knn=KNeighborsClassifier()
knn.fit(new_x_train,y_train) #model training
knn.predict(new_x_test) #model prediction
knn.score(new_x_test,y_test) #model assessment
GridSearchCV
gridsearch and cross validation
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier # classifier
from sklearn.preprocessing import StandardScaler # standard
from sklearn.model_selection import train_test_split,GridSearchCV #split data and gridsearchcv
# read data
data=pd.read_csv('data/---.csv')
data.head()
# feature,score
x=data[['--','---','---']] #array_x should be two-dimensional
y=data[['target--']] #score
# split data
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=24) #test_size-the test data ratio。random_state---set casually,migrate easily
# standard
sc=StandardScaler()
new_x_train=sc.fit_transform(x_train)
new_x_test=sc.transform(x_test)
# mahine learning------
knn=KNeighborsClassifier()
# GridSearchCv-----------------------!
param_dict={'n_neighbors':[1,3,5]} # param dict for adjustment
es=GridSearchCV(knn,param_grid=param_dict,cv=3) # gridsearch and cross validation
es.fit(new_x_train,y_train) #data training
# model assessment
y_predict=es.predict(x_test) # predict y
score=es.score(x_test,y_test) # calculate the precision
es.best_score_ # best score
es.best_params_ # best params
Linear regression
LinearRegression
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
.........
#model training
lr=LinearRegression()
lr.fit(new_x_train,y_train)
#prediction
y_pred=lr.predict(new_x_test)
print("y_prediction:",y_pred)
lr.coef_ #w
# coef_array of shape (n_features, ) or (n_targets, n_features) --->can be regarded as '系数'
lr.intercept_ #b
# intercept_float or array of shape (n_targets,)----->can be regarded as '截距'
#model assessment
err=mean_squared_error(y_test,y_pred)
err
SGDRegressor
- Stochastic gradient descent



from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
.........
# model training
lr2=SGDRegressor(max_iter=5000,learning_rate='constant',eta0=0.001)
lr2.fit(new_x_train,y_train)
#prediction
y_pred=lr.predict(new_x_test)
print("y_prediction:",y_pred)
# model assessment
score=lr.score(new_x_test,y_test)#[0,1] be better to close "1"
print(score)
error=predictions-y_test#calculate error
rmse=(error**2).mean()**.5#calculate rmse
mae=abs(error).mean()#calculatemae
print(rmse)
print(mae)
Regularized linear model
Ridge Regression
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)

# ridge=Ridge(alpha=0.1)
ridge=RidgeCV(alphas=(0.001,0.005,0.1,0.5,1,10,20,50,100))
ridge.fit(new_x_train,y_train)
#predict
y_pred=ridge.predict(new_x_test)
Losso Regression
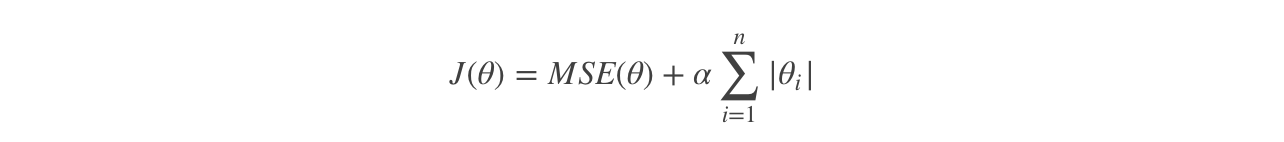
Logistic Regression
sklearn.linear_model.LogisticRegression(solver=‘liblinear’, penalty=‘l2’, C = 1.0)
#model training
lr=LogisticRegression()
lr.fit(new_x_train,y_train)
#model assessment
pred=lr.predict(new_x_test)
pred
#ouput score
lr.score(new_x_test,y_test)
# the distribution of test data
y_test.value_counts()
# assessment
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,pred)
tn,fp,fn,tp=confusion_matrix(y_test,pred).ravel()
tn,fp,fn,tp
pr=tp/(tp+fp) # precision
recall=tp/(tp+fn) # recall
#api for calculating precision and recall
from sklearn.metrics import precision_score,recall_score
precision_score(y_true,y_pred) # y_true and y_pred must be 1 or 0
recall_score(y_true,y_pred)
#calculate f1
f1=2*tp/(2*tp+fn+fp)
f1
f12=2*pr*recall/(pr+recall)
f12
# f1_score
from sklearn.metrics import f1_score
f1_score(y_true,y_pred)
# classification_report!!!!!!!!!!!
from sklearn.metrics import classification_report
print(classification_report(y_test,pred,labels=(1,0),target_names=("good","bad")))
precision_score(y_true,y_pred)
DecisionTree
import pandas as pd
import numpy as np
from sklearn.feature_extration import DictVectorizer # transform non-numeric data into numerical value----onehot
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,export_graphviz
data=pd.read_csv('data/----.csv')
x=data[['--','--','--','--']]
y=data['--']
# solve the null
x['--'].fillna(x['--'].mean(),inplace=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=12) # split data
# feature extraction
# DictVectorizer can only deal with the "dict",must use 'to_dict' to make that
transfer=DictVectorizer(sparse=False)
x_train=transfer.fit_transform(x_train.to_dict(orient="records"))
x_test=transfer.transform(x_test.to_dict(orient='records'))
# machine learning
es=DecisionTreeClassfier(criterion="entropy", max_depth=5)
es.fit(x_train,y_train)
es.score(x_test,y_test)
es.predict(x_test)
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
# the visualization of decision tree
Boosting & Bagging
RandomForest
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# init the object
rf=RandomForestClassifier()
# setting the
param= {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
# define gridsearch
gs=GridSearchCV(rf,param_grid=param,cv=3)
gs.fit(new_x_train,y_train)
gs.score(new_x_test,y_test)
gs.best_params_
adaboost
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(n_estimators=1000,learning_rate=0.01)
ada.fit(new_x_train,y_train)
ada.score(new_x_test,y_test)
Kmeans


from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# model training
km=KMeans(n_clusters=8,random_state=24)
km.fit(data)
y_predict=km.predict(data)
km.cluster_centers_
silhouette_score(data, y_predict)
Others
feature extraction
CountVectorizer
#
from sklearn.feature_extraction.text import CountVectorizer
# get data
data=["人生苦短,我喜欢Python","生活太长久,我不喜欢Python"]
stop_words={'。',','}
# init the object
vector=CountVectorizer(tokenizer=jieba.lcut,stop_words=stop_words)
new_data=vector.fit_transform(data)# handle the data
print(new_data.toarray())#
# into dataFrame
pd.DataFrame(new_data.toarray(),columns=vector.get_feature_names()).T
Feature dimensionality reduction
Feature selector that removes all low-variance features.

from sklearn.feature_selection import VarianceThreshold # removes all low-variance features
vt=VarianceThreshold(threshold=1)
new_x=vt.fit_transform(x)
new_x.shape
PCA
Principal component analysis (PCA).

from sklearn.decomposition import PCA
pca=PCA(n_components=2)
pca_x=pca.fit_transform(new_x)
pca_x.shape
Correlated Features
# pearsonr
from scipy.stats import pearsonr
x1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9]
x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]
pearsonr(x1,x2)
# spearmanr
from scipy.stats import spearmanr
spearmanr(x1,x2)
the guidance of choosing algorithm

















 3465
3465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









